원문 : https://arxiv.org/abs/2307.15793
이 글에 대한 모든 권리는 원문 저자들에게 있다.
##############
Summaries, Highlights, and Action items: Design, implementation and evaluation of an LLM-powered meeting recap system
SUMIT ASTHANA, University of Michigan, Ann Arbor, USA
SAGIH HILLELI, Microsoft, Israel PENGCHENG HE, Microsoft, USA AARON HALFAKER, Microsoft, USA
Meetings play a critical infrastructural role in the coordination of work. In recent years, the nature of meetings have been changing with the shift to hybrid and remote work – meetings have moved into computer mediated spaces in new ways that have lead to new problems (e.g. more time spent in less engaging meetings) and new opportunities (e.g. automated transcription/captioning and recap support). Recent advances in large language models (LLMs) for dialog summarization have the potential to improve the experience of meetings by reducing individuals’ meeting load and increasing the clarity and alignment of meeting outputs. Despite this potential, they exhibit significant issues if directly applied to summarize meeting long transcripts. Moreover, prior studies of recap highlight varying recap needs based on user’s context that no one design addresses, highlighting the need for in-context evaluations. To address these gaps, we describe the design, implementation, and in-context evaluation a meeting recap system. We first conceptualize two salient recap representations – important “highlights”, and a structured, “hierarchical” minutes view and provide supporting rationales from cognitive science and discourse theories on perception and recall. We develop a system to operationalize the representations with dialogue summarization as its building blocks. Finally, we evaluate the effectiveness of the system with seven users in the context of their work meetings. Our findings show promise in using LLM-based dialogue summarization for meeting recap and the need for both representations in different contexts. However, we find that LLM-based recap still lacks an understanding of whats personally relevant to participants, can miss important details, and mis-attributions can be detrimental to group dynamics. We identify collaboration opportunities such as a shared recap document that a high quality recap enables. We report on implications for designing AI systems to partner with users to learn and improve from natural interactions to overcome the limitations related to personal relevance and summarization quality. We synthesize these findings as design implications to advance the space of meeting recap in supporting group work in organizations.
회의는 업무 조율에 있어 중요한 인프라 역할을 한다. 최근 몇 년 동안 하이브리드 및 원격 근무로의 전환에 따라 회의의 성격이 변화하고 있다. 회의가 컴퓨터를 매개로 한 새로운 방식으로 진행되면서 새로운 문제(예: 참여도가 낮은 회의에 소요되는 시간 증가)와 새로운 기회(예: 자동화된 전사/캡션 및 요약 지원)가 생겨났다. 대화 요약을 위한 대규모 언어 모델(LLM)의 최근 발전은 개인의 회의 부담을 줄이고, 회의 결과물의 명확성과 일관성을 높여 회의 경험을 개선할 수 있는 잠재력을 가지고 있다. 이러한 잠재력에도 불구하고 장문의 회의 내용을 요약하는데 직접 적용할 경우 상당한 문제가 있다. 또한 요약에 대한 선행 연구에 따르면 사용자의 컨텍스트에 따라 다양한 요약 니즈가 존재하며, 이는 어떤 디자인도 해결하지 못하므로 컨텍스트 내 평가의 필요성을 강조한다. 이러한 격차를 해소하기 위해 이 글에서는 회의 요약 시스템의 설계, 구현 및 맥락 내 평가에 대해 설명한다. 먼저 중요한 '하이라이트'와 구조화된 '계층적' 회의록 보기라는 두 가지 주요 요약 표현을 개념화하고, 지각과 회상에 관한 인지 과학 및 담론 이론의 근거를 제시한다. 대화 요약을 기본 구성 요소로 하여 표현을 운영할 수 있는 시스템을 개발한다. 마지막으로 7명의 사용자를 대상으로 업무 회의 맥락에서 시스템의 효과를 평가한다. 연구 결과, 회의 요약에 LLM 기반 대화 요약 기능을 사용할 수 있는 잠재력과 다양한 맥락에서 두 가지 표현이 모두 필요하다는 것을 알 수 있었다. 그러나 LLM 기반 요약은 여전히 참가자와 개인적으로 관련된 내용에 대한 이해가 부족하고, 중요한 세부 사항을 놓칠 수 있으며, 잘못된 귀속으로 인해 그룹 역학 관계에 해를 끼칠 수 있다는 사실을 발견했다. 고품질 요약이 가능하게 하는 공유 요약 문서와 같은 협업 기회를 파악한다. 개인별 관련성 및 요약 품질과 관련된 한계를 극복하기 위해 사용자와 협력하여 자연스러운 상호 작용을 통해 학습하고 개선하는 AI 시스템 설계에 대한 시사점에 대해 보고한다. 이러한 연구 결과를 종합하여 조직의 그룹 작업을 지원하는 회의 요약 공간을 발전시키기 위한 설계적 시사점을 도출한다.
1.INTRODUCTION
“Communication is the lifeblood of organizations”[66] and meetings are “window into the soul of a business”[36] are truisms that describe the reality of modern work in organizational settings. Meetings serve an important organizational purpose for people to discuss ideas, share information, build consensus, and make decisions. They help get key points, actions items, questions and answers distributed so people get the information on time [79]. They also help to reduce the uncertainty in the organization by bringing the participants together, to discuss and resolve issues [4]. However, key details of the meetings could be missed or forgotten due to participants being oversubscribed to meetings or due to distractions by emails, IMs and other communication [56]. Further, time conflicts and increasing cross-timezone collaborations cause participants to need to miss meetings altogether [57].
With the rise in geographically dispersed teams, the COVID-19 pandemic, and shifts towards remote work, organizations are increasingly adopting online web conferencing software to hold meetings[71, 84]. With the wide adoption of technically mediated meetings comes an opportunity for designers and researchers to apply technical approaches to support these new ways of working.
"커뮤니케이션은 조직의 생명선"[66], "회의는 비즈니스의 영혼을 들여다보는 창"[36]이라는 말은 현대 조직 환경의 업무 현실을 잘 설명하는 진리이다. 회의는 사람들이 아이디어를 논의하고, 정보를 공유하고, 합의를 도출하고, 의사 결정을 내리는 중요한 조직의 목적에 부합한다. 회의는 사람들이 제시간에 정보를 얻을 수 있도록 핵심 사항, 실행 항목, 질문 및 답변을 배포하는 데 도움이 된다[79]. 또한 참가자들을 한자리에 모아 문제를 논의하고 해결함으로써 조직의 불확실성을 줄이는 데 도움이 된다[4]. 그러나 참가자가 회의에 과도하게 참여하거나 이메일, 메신저 및 기타 커뮤니케이션으로 인해 회의의 주요 세부 사항을 놓치거나 잊어버릴 수 있다[56]. 또한 시간 충돌과 시간대 간 협업의 증가로 인해 참가자가 미팅에 아예 불참해야 하는 경우도 있다[57].
지리적으로 분산된 팀의 증가, 코로나19 팬데믹, 원격 근무로의 전환으로 인해 조직은 회의를 개최하기 위해 온라인 웹 회의 소프트웨어를 점점 더 많이 채택하고 있다[71, 84]. 기술적으로 중개된 회의가 널리 채택됨에 따라 디자이너와 연구자들은 이러한 새로운 업무 방식을 지원하기 위한 기술적 접근 방식을 적용할 수 있는 기회가 생겼다.
In this paper, we consider technological support for meeting recap – systems that aid in the capture of important information, decisions, and action items conveyed in a meeting for asynchronous review and engagement. Meeting recap serves an important role in preserving meeting content both for attendees and non-attendees alike [79]. Past practices for capturing meeting content such as note-taking are often informal and their manual nature places a high burden on meeting participants [34]. While current meeting technologies allow for effective participation within meetings, like seamless high quality videos and raising hands for participation [43, 63], tools for supporting meeting recap either rely on participants to engage in distracted note-taking during the meeting or require the user to sort through dense meeting content (e.g. recordings or transcript) by inefficient scanning patterns [52].
이 백서에서는 비동기식 검토 및 참여를 위해 회의에서 전달된 중요한 정보, 의사 결정 및 실행 항목을 캡처하는 데 도움이 되는 시스템인 회의 요약에 대한 기술적 지원을 고려한다. 미팅 요약은 참석자와 비참석자 모두를 위해 미팅 콘텐츠를 보존하는 데 중요한 역할을 한다[79]. 메모 작성과 같은 회의 콘텐츠를 캡처하는 과거의 관행은 비공식적인 경우가 많았고 수작업으로 진행되어 회의 참가자에게 큰 부담을 주었다[34]. 현재의 회의 기술은 끊김 없는 고품질 비디오, 참여 시 손 들기 등 효과적인 회의 참여가 가능하지만[43, 63], 회의 요약 지원 도구는 참가자가 회의 중에 산만하게 메모를 작성하거나 사용자가 비효율적인 스캔 패턴으로 밀집된 회의 콘텐츠(예: 녹취 또는 대본)를 분류해야 한다[52].
Prior approaches have attempted to ease recap by presenting a mix of audio, video, or transcripts generated using automated speech recognition (ASR) in navigable browsers [79]. While such browsers provide a record to reference, raw utterances and recordings still leave sense-making to participants, making it cumbersome to digest information [6, 52]. This also limits asynchronous participation – opportunities for non-attendees to engage with the meeting content and with attendees after the meeting has taken place – due to the lack of context in generated summaries [34]. Recent dialogue summarization models [45] have been shown to generate contextual summaries for short chit-chat style dialogues [25] and such summaries could improve over raw transcripts. However, meeting dialogues are long discussions between multiple participants for disseminating information, achieving consensus, negotiating deals and deliberations [4, 74]. Directly applying dialogue summarization on meeting length transcripts has been challenging due to scattered information, multiple and changing topics and unclear topic boundaries [33, 59]. Moreover, research shows that user needs vary based on their role, whether they attended the meeting, and their work expectations [7, 79]. A single recap representation is unlikely to capture all such needs [74]. Thus, automated metrics, or crowd-sourced evaluations are un-reliable indicators of useful meeting recap [35, 79]. Prior research in CSCW indicates that studying how users apply technology in their work (e.g., ML assisted Wikipedia editing or ML assisted medical note-taking) [42] is essential to identify technology’s alignment with contextual user needs that automated metrics or crowd- sourced evaluations cannot measure [64, 68, 70]. Yet, evaluations in people’s context of use is especially challenging because AI systems for complex work do not lend themselves well to traditional low-cost evaluation methods in HCI like heuristic evaluations, or wizard-of-oz [81].
이전의 접근 방식은 탐색 가능한 브라우저에서 자동 음성 인식(ASR)을 사용하여 생성된 오디오, 비디오 또는 녹취록을 혼합하여 제시함으로써 요약을 쉽게 하려고 시도했다[79]. 이러한 브라우저는 참조할 수 있는 기록을 제공하지만, 원어 발화 및 녹취는 여전히 참가자에게 의미가 남아있기 때문에 정보를 소화하는 데 번거로움이 있다[6, 52]. 또한 생성된 요약에 컨텍스트가 부족하기 때문에 비동기식 참여(회의에 참석하지 않은 사람이 회의 콘텐츠에 참여할 수 있는 기회 및 회의가 끝난 후 참석자와 함께 참여할 수 있는 기회)가 제한된다[34]. 최근의 대화 요약 모델[45]은 짧은 채팅 스타일의 대화[25]에 대해 문맥에 맞는 요약을 생성하는 것으로 나타났으며, 이러한 요약은 원시 트랜스크립트보다 개선될 수 있다. 그러나 회의 대화는 정보 전달, 합의 도출, 협상, 심의 등을 위해 여러 참여자 간에 이루어지는 긴 토론이다[4, 74]. 흩어져 있는 정보, 다양하고 변화하는 주제, 불명확한 주제 경계로 인해 장문의 회의 녹취록에 대화 요약 기능을 직접 적용하는 것은 어려운 일이었다[33, 59]. 또한 연구 결과에 따르면 사용자의 요구는 역할, 회의 참석 여부, 업무 기대치에 따라 달라진다[7, 79]. 단일 요약 표현으로는 이러한 모든 니즈를 포착할 수 없다[74]. 따라서 자동화된 지표 또는 크라우드 소싱 평가는 유용한 회의 요약의 신뢰할 수 없는 지표이다[35, 79]. CSCW의 선행 연구에 따르면 사용자가 업무에 기술을 적용하는 방식(예: ML 지원 위키피디아 편집 또는 ML 지원 의료 노트 작성)을 연구하는 것은 자동화된 지표나 크라우드 소스 평가로는 측정할 수 없는 맥락적 사용자 요구와 기술의 연계성을 파악하는 데 필수적이다[64, 68, 70]. 그러나 복잡한 작업을 위한 AI 시스템은 휴리스틱 평가나 마법사 오브 오즈와 같은 HCI의 전통적인 저비용 평가 방법에 적합하지 않기 때문에 사람들의 사용 맥락에서 평가하는 것은 특히 어렵다[81].
To address this gap of how to apply dialogue summarization for meeting recap, and evaluate how well recap representations serve user needs we 1) Develop an LLM-based summarization system [15, 28, 45] for long meeting dialogues using transformers and text segmentation, 2) Use theories from cognitive science and discourses [85] to conceptualize two diverse experimental representations [81] "highlights" and "hierarchical" that capture the need for quick takeaways, and chronological topic focused discussions respectively [35, 56], 3) Perform preliminary evaluations with seven information workers in a large software company to explore the benefits and challenges when attendees use the representations to support their work and collaborations. Since the models we develop are trained on crowd-sourced data, that do not align with user needs in high context applications like meeting recap [80], we also explore what interactions can enable users to provide high quality feedback to improve and align model behavior to their needs. In summary, our context of study is organizational work which is a core tenet of cscw [64]. We leverage the concept of imperfect prototype experiences from HCI [81] to explore the design space of meeting summarization for recap support as well as ways in which user interactions with a meeting recap experience could be turned into useful training data to improve the alignment of the summarization models.
회의 요약에 대화 요약을 적용하는 방법의 이러한 격차를 해결하고 요약 표현이 사용자 요구에 얼마나 잘 부합하는지 평가하기 위해 1) 변환기와 텍스트 분할을 사용하여 긴 회의 대화를 위한 LLM 기반 요약 시스템[15, 28, 45]을 개발하고, 2) 인지 과학과 담론[85]의 이론을 사용하여 빠른 테이크아웃의 필요성을 포착하는 "하이라이트"와 "계층적"[81] 두 가지 다양한 실험적 표현을 개념화했다, 및 연대기적 주제 중심 토론 [35, 56], 3) 대형 소프트웨어 회사의 정보 근로자 7명과 함께 예비 평가를 수행하여 참석자가 업무 및 협업을 지원하기 위해 표현을 사용할 때의 이점과 과제를 탐색한다. 우리가 개발하는 모델은 회의 요약과 같이 맥락이 중요한 애플리케이션에서 사용자의 요구와 일치하지 않는 크라우드 소스 데이터로 학습되었기 때문에[80], 사용자가 모델 동작을 개선하고 필요에 맞게 조정하기 위해 고품질 피드백을 제공할 수 있는 상호 작용이 무엇인지도 탐색한다. 요약하자면, 우리의 연구 컨텍스트는 조직 작업이며, 이는 CSCW의 핵심 신조이다[64]. 우리는 HCI[81]의 불완전한 프로토타입 경험이라는 개념을 활용하여 요약 지원을 위한 회의 요약의 설계 공간과 회의 요약 경험과의 사용자 상호작용을 유용한 학습 데이터로 전환하여 요약 모델의 정렬을 개선할 수 있는 방법을 탐색한다.
Our in-context evaluations highlight user needs that existing linguistic evaluations of dialogue summarization do not capture. We find that dialogue summarization generates summaries that are understandable by users, allowing them to recall their meeting, plan action items, and share, improving over the distractions observed from transcript based browsers [35]. While all participants found the summaries understandable, pronoun issues and mis-attributions are mildly distracting for individual recap, but could be detrimental to group dynamics. We find strong support for a hierarchical approach to meeting summary presentation that is implied by cognitive theory on task structure understanding [85] and discourse analysis [26]. With both "highlights" and "hierarchical", we found the need to incorporate personal relevance in recap (e.g., priority ordering of summary items). Additionally, we found strong inclination to collaborate using the recap, by sharing summaries, or using it as a collaborative document indicating the recap’s role in persisting meeting outcomes as permanent documents. To improve the relevance of generated summaries, we found that ML models can learn from users adding or editing summaries but deleting summaries may not provide high quality training data as participants reported multiple reasons for deletions. These implications are grounded in existing literature of increasing alignment of Human-AI models [83]. Our work follows the lineage of CSCW Design and Evaluation systems category of work that uses existing technological support to design systems for supporting group work [61, 77] and evaluate the system’s usefulness in supporting the organizational processes through a preliminary in-context study [70].
우리의 In-context 평가는 대화 요약에 대한 기존의 언어적 평가가 포착 못하는 사용자 니즈를 강조한다. 대화 요약은 사용자가 이해할 수 있는 요약을 생성하여 사용자가 회의를 회상하고, 실행 항목을 계획하고, 공유할 수 있도록 지원하며, 트랜스크립트 기반transcript based 브라우저에서 관찰된 산만함distractions[35]을 개선한다는 사실을 발견했다. 모든 참가자가 요약 내용을 이해할 수 있다고 답했지만, 대명사 문제와 잘못된 귀속mis-attributions은 개별 요약에는 다소 산만하지만 그룹 역학group dynamics 관계에는 해가 될 수 있다. 우리는 과제 구조 이해에 관한 인지 이론[85]과 담화 분석[26]이 암시하는 회의 요약 프레젠테이션에 대한 계층적 접근 방식을 강력하게 지지한다. "하이라이트"와 "계층적" 모두에서 요약에 개인적 관련성(예: 요약 항목의 우선순위)을 통합할 필요성을 발견했다. 또한 요약본을 공유하거나 회의 결과를 영구 문서로 보존하는데 요약본의 역할을 나타내는 협업 문서로 사용하는 등 요약본을 사용하여 협업하려는 성향이 강하다는 것을 발견했다. 생성된 요약의 관련성을 개선하기 위해 ML 모델은 사용자가 요약을 추가하거나 편집하는 것을 통해 학습할 수 있지만, 참가자들이 여러 가지 삭제 이유를 보고함에 따라 요약을 삭제하면 고품질의 학습 데이터를 제공하지 못할 수 있다는 사실을 발견했다. 이러한 시사점은 인간-AI 모델의 정렬이 증가한다는 기존 문헌에 근거한다[83]. 우리의 연구는 기존의 기술 지원을 사용하여 그룹 작업을 지원하기 위한 시스템을 설계하고[61, 77], 예비 상황 내 연구를 통해 조직 프로세스를 지원하는 데 있어 시스템의 유용성을 평가하는 CSCW 설계 및 평가 시스템 범주의 작업 계보를 따른다[70].
2. RELATED WORK
2.1 Speech and text summarization
Speech and text summarization is the backbone of generating intelligent meeting recap experiences. The most straightforward approach is to directly detect important utterances using automatic speech recognition (ASR). However, natural language summarization methods [88] are designed for text and cannot be directly applied to speech signals Therefore, it is more effective to translate the speech to text and then apply text summarization [3, 54]. Early text summarization approaches simply extracted important sentences from the corpus to represent in the summary. However, a summary consisting of important sentences verbatim does not capture enough context due to unresolved pronouns and references. With advent of neural based summarization approaches [18], models can generate an abstracted summary of corpus with context. While corpus based abstractive summarization provides more context, it does not work well in the dialogue setting due to the inability to map dialogues to speakers and resolve the references in the multiparty dialogues [39].
음성 및 텍스트 요약은 지능형 회의 요약 경험을 생성하는 중추이다. 가장 간단한 접근 방식은 자동 음성 인식(ASR)을 사용하여 중요한 발화를 직접 감지하는 것이다. 그러나 자연어 요약 방법[88]은 텍스트용으로 설계되어 음성 신호에 직접 적용할 수 없으므로 음성을 텍스트로 번역한 다음 텍스트 요약 기능을 적용하는 것이 더 효과적이다[3, 54]. 초기의 텍스트 요약 접근 방식은 단순히 말뭉치에서 중요한 문장을 추출하여 요약에 표현했다. 그러나 중요한 문장을 그대로 요약하면 미해결 대명사 및 참조로 인해 충분한 문맥을 포착하지 못한다. 신경 기반 요약 접근법[18]의 등장으로 모델은 문맥이 포함된 코퍼스의 추상화된 요약을 생성할 수 있게 되었다. 코퍼스 기반의 추상적 요약은 더 많은 컨텍스트를 제공하지만, 다자간 대화에서 대화를 화자에게 매핑하고 참조를 해결할 수 없기 때문에 대화 환경에서는 잘 작동하지 않는다[39].
Dialogue datasets based on informal SMS exchanges [11, 12] led to progress on capturing context resulting in summaries that are close to human written notes. However, meetings can typically span 30 minutes or more and involve sensemaking in a shared grounded environment, and even state of the art transformer models cannot be directly applied to long discussions because of limited text input length [88], and inability to capture long range context dependencies. To overcome these limitations, Cohen et al [15] explored a two stage process 1) Identify the important meeting seg- ments using transcripts where important utterances are annotated for relevance, 2) Paraphrase the utterances identified in step (1) to generate abstractive notes and add them to the summary. Current evaluations in summarization explore the faithfulness of summaries to reference text dialogues [48], or automated metrics like ROGUE [46]. While ROGUE supports evaluating summaries for text corpus, or short dialogues [25], metrics and crowd-sourced evaluations are not a good choice for evaluating meeting recap as it requires high contextual knowledge to assess relevance [70]. Fac- tors like user’s background, organizational contexts like established recap practices and cognitive load can all have an impact on what recap fits user’s needs and requires in-context studies to evaluate [79].
비공식적인 SMS 교환에 기반한 대화 데이터 세트[11, 12]를 통해 문맥을 파악하는 데 진전이 있었고, 그 결과 사람이 직접 작성한 메모에 가까운 요약본을 만들 수 있었다. 그러나 회의는 일반적으로 30분 이상 지속될 수 있고, 공유된 환경에서 감각적 의사결정이 수반되며, 텍스트 입력 길이가 제한되고[88] 장거리 컨텍스트 종속성을 포착할 수 없기 때문에 최첨단 트랜스포머 모델조차도 긴 토론에 직접 적용할 수 없다. 이러한 한계를 극복하기 위해 Cohen 등[15]은 1) 중요한 발언에 관련성 주석이 달린 녹취록을 사용하여 중요한 회의 내용을 식별하고, 2) 1단계에서 식별한 발언을 의역하여 추상적인 메모를 생성하고 요약에 추가하는 2단계 프로세스를 탐색했다. 현재 요약에 대한 평가는 텍스트 대화 참조에 대한 요약의 충실도[48] 또는 ROGUE [46]와 같은 자동화된 메트릭을 사용한다. ROGUE는 텍스트 코퍼스 또는 짧은 대화에 대한 요약 평가를 지원하지만[25], 관련성을 평가하기 위해서는 높은 수준의 문맥 지식이 필요하기 때문에 메트릭과 크라우드 소스 평가는 회의 요약 평가에는 적합하지 않는다[70]. 사용자의 배경, 기존 요약 관행과 같은 조직적 맥락, 인지적 부하와 같은 요인은 모두 사용자의 요구에 맞는 요약에 영향을 미칠 수 있으며, 이를 평가하기 위해서는 맥락 내 연구가 필요한다[79].
2.2 Meeting recap tools
Most contemporary meeting tools allow participants to record meetings and generate automatic transcription, for later recap. However, raw audio and video recordings of meetings have been found to be poor means of recap [6, 52] because they are long with redundant information. Prior approaches to ease recap have focused on building tools to combine audio, video and other artefacts (e.g., slides, documents, whiteboard annotations, transcripts marked with discourse labels) [79]. Such methods employed various strategies to help participants consume the raw information like helping take notes or mark timestamps in meetings, or automatically extract phrases with keywords that participants can use and review later. They could also provide index into meetings [23, 24, 56, 78], generate short annotations [7], or record notes on electronic devices [17]. For example, the Lite minutes system [13] allowed participants to create and share text, audio and slide based notes with automatically generated smart links, and post meeting note correction over email. Such annotations when linked with video have been shown to provide value in education environments as well [56, 67] acting as digital bookmarks.
대부분의 최신 회의 도구는 참가자가 회의를 녹화하고 자동 트랜스크립션을 생성하여 나중에 요약할 수 있도록 지원한다. 그러나 회의의 원시 오디오 및 비디오 녹화물은 중복 정보가 많고 길기 때문에 [6, 52] 요약 수단으로 적합하지 않은 것으로 밝혀졌다. 요약을 쉽게 하기 위한 이전의 접근 방식은 오디오, 비디오 및 기타 아티팩트(예: 슬라이드, 문서, 화이트보드 주석, 담화 레이블이 표시된 녹취록)를 결합하는 도구를 구축하는 데 중점을 두었다[79]. 이러한 방법은 참가자가 회의에서 메모를 하거나 타임스탬프를 표시하는 것을 돕거나, 참가자가 나중에 사용하고 검토할 수 있는 키워드로 구문을 자동으로 추출하는 등 원시 정보를 소비하는 데 도움이 되는 다양한 전략을 사용했다. 또한 회의에 대한 색인을 제공하거나[23, 24, 56, 78], 짧은 주석을 생성하거나[7], 전자 장치에 메모를 기록할 수도 있다[17]. 예를 들어, 라이트 회의록 시스템[13]을 통해 참가자는 자동으로 생성된 스마트 링크를 사용하여 텍스트, 오디오, 슬라이드 기반 노트를 작성 및 공유하고 이메일을 통해 회의 노트 수정 사항을 게시할 수 있었다. 이러한 주석은 비디오와 연결될 때 교육 환경에서도 디지털 북마크 역할을 하는 것으로 나타났다[56, 67].
To further ease the cognitive load, research into automatic indexing tools developed indexes based on the transcript content [72], speech recognition on audio, semantic grouping of concepts represented in the transcript [21, 24, 37, 38, 60], or removing redundant utterances from recordings [73]. Segmentation, action item detection and note extraction can then be combined in a meeting browser [20] for easy meeting recap. Despite the rich modalities of recap browsers, Whittaker et al [79] in their evaluation of meeting browsers found that participants found audio/video distracting, and resorted to scanning transcripts due to relative ease of skimming [79]. Yet, due to digesting raw utterances, they repeatedly missed the high level picture of the meeting, while being overconfident in their recall. Both Whittaker et al and Banerjee et al’s recap studies [7, 79] highlight the need to consider different recap forms for different needs, one for quick catch-up and another for detailed topic focused structured discussions.
인지적 부하를 더욱 완화하기 위해 자동 색인 도구에 대한 연구에서 녹취록 내용을 기반으로 한 색인[72], 오디오에 대한 음성 인식, 녹취록에 표현된 개념의 의미론적 그룹화[21, 24, 37, 38, 60] 또는 녹음에서 중복 발화 제거[73] 등을 개발했다. 그런 다음 세분화, 작업 항목 감지 및 메모 추출을 회의 브라우저에서 결합하여[20] 회의를 쉽게 요약할 수 있다. 요약 브라우저의 다양한 양식에도 불구하고, 회의 브라우저를 평가한 Whittaker 등[79]은 참가자들이 오디오/비디오가 산만하다고 느꼈으며, 상대적으로 쉽게 훑어볼 수 있기 때문에 녹취록을 스캔하는 데 의존한다는 사실을 발견했다[79]. 하지만 원어민 발언을 소화하다 보니 회의의 큰 그림을 놓치는 경우가 반복되었고, 기억력을 과신하는 경향이 있었다. 휘태커와 바네르지의 요약 연구[7, 79]는 빠른 따라잡기를 위한 요약과 세부 주제 중심의 구조화된 토론을 위한 요약 등 필요에 따라 서로 다른 요약 양식을 고려할 필요가 있음을 강조한다.
With all prior recap systems [7, 13, 20, 78] participants could identify disjoint independent nuggets of information, but struggled to draw a high level picture of the meeting. This was due to limitations of text processing at the time to rephrase transcripts in formats that are akin to manual notes and summaries. Recap in online discussions is similarly complex and has similar opportunities. Structured presentation of discussion in a hierarchical format has been found to be helpful for recap sense-making activities [55, 87]. Moreover, Zhang et al found that simple information augmentation on messages like attaching discourse labels (e.g. action, answer, decision) to slack discussions [86] helped participants skim and filter relevant discussions on asynchronous discussion forums. However, their augmentation still required participants to add tags manually, which is not feasible when attending meetings online [50].
이전의 모든 요약 시스템[7, 13, 20, 78]에서 참가자들은 독립적인 정보 덩어리를 식별할 수는 있었지만, 회의의 전체적인 그림을 그리는 데는 어려움을 겪었다. 이는 당시 텍스트 처리의 한계로 인해 수기 메모 및 요약과 유사한 형식으로 녹취록을 재구성하는 데 한계가 있었기 때문이다. 온라인 토론에서의 요약도 마찬가지로 복잡하며 비슷한 기회가 있다. 계층적 형식의 구조화된 토론 프레젠테이션은 요약의 의미 파악 활동에 도움이 되는 것으로 밝혀졌다[55, 87]. 또한 Zhang 등은 느슨한 토론에 담론 레이블(예: 행동, 답변, 결정)을 붙이는 것과 같이 메시지에 간단한 정보 증강이 비동기식 토론 포럼에서 참가자들이 관련 토론을 훑어보고 필터링하는 데 도움이 된다는 사실을 발견했다[86]. 그러나 이러한 증강 기능을 사용하려면 여전히 참가자가 수동으로 태그를 추가해야 했으며, 이는 온라인 미팅에 참석할 때 불가능했다[50].
2.3 Meeting recap and sensemaking
Meetings play a crucial role in organizations in terms of reducing the uncertainty by building mutual understanding, as well as helping participants brainstorm, and create new ideas [1, 4]. Meeting recap helps to sustain these benefits after a meeting by documenting the discussions and outputs. Documented discussions can foster collaboration and dissemination of ideas [5, 10, 40, 67]. Beyond collaboration, meeting discussions are a rich source of resources whose documentation can add to existing resources in the organization for newcomers, and experts alike. Besides acting as memory aids, meeting recap afford participants retrospective sensemaking that may lead to more insights, or clarifications of concepts[86].
회의는 상호 이해를 증진하여 불확실성을 줄이고 참가자들이 브레인스토밍을 통해 새로운 아이디어를 창출하는 데 도움을 준다는 점에서 조직에서 중요한 역할을 한다[1, 4]. 회의 요약은 토론과 결과물을 문서화하여 회의 후에도 이러한 이점을 지속하는 데 도움이 된다. 문서화된 토론은 협업과 아이디어의 확산을 촉진할 수 있다[5, 10, 40, 67]. 협업 외에도, 회의 토론은 신입 사원과 전문가 모두에게 문서화가 조직의 기존 리소스에 추가될 수 있는 풍부한 리소스 소스이다. 회의 요약은 기억을 보조하는 역할 외에도 참가자들에게 더 많은 인사이트나 개념의 명확화로 이어질 수 있는 회고적 감각 형성을 제공한다[86].
Due to such diverse uses of meeting recap, there is considerable debate on what constitutes a good recap [79]. Including everything in the recap can lead to increased cognitive burden on participants, no better than video, and fixation on ideas [32, 52]. For attendees, meetings serve as reminders, acting as "cues" into their memory [35], for which a meeting recap with the most important discussions and decisions suffices. However, for non-attendees and attendees after a sufficient time since the meeting, a "minutes" like view that provides a chronological meeting record helps understand the purpose, discussions and decisions of the meeting. In-context prior evaluations with meeting attendees surface similar needs [79] According to cognitive fit theory [69], the structure of the meeting recap can determine the kind of tasks, and sensemaking that it can support. Recap composed of a list of key discussions and decisions is suitable to aid recall when participants already have meeting details in their memory.
이처럼 회의 요약의 용도가 다양하기 때문에 무엇이 좋은 요약인지에 대해 상당한 논쟁이 있다[79]. 요약에 모든 내용을 포함하면 참가자의 인지적 부담이 증가하여 비디오보다 낫지 않으며 아이디어에 집착하게 될 수 있다[32, 52]. 참석자에게 회의는 기억에 '단서'로 작용하는 알림 역할을 하므로[35], 가장 중요한 논의와 결정 사항이 포함된 회의 요약만으로도 충분한다. 그러나 비참석자와 회의가 끝난 후 충분한 시간이 지난 참석자의 경우, 시간순으로 회의 기록을 제공하는 '회의록'과 같은 보기가 회의의 목적, 논의 및 결정을 이해하는 데 도움이 된다. 회의 참석자들과의 맥락에 맞는 사전 평가를 통해 유사한 니즈를 파악할 수 있다[79] 인지 적합성 이론[69]에 따르면 회의 요약의 구조에 따라 지원할 수 있는 작업의 종류와 센스메이킹이 결정될 수 있다. 주요 논의 및 결정 사항의 목록으로 구성된 요약은 참가자가 이미 회의 세부 사항을 기억하고 있을 때 회상을 돕는 데 적합한다.
"Minutes" like chronological structure is supported by theories in discourses and cognitive science. Zacks et al.[85] show through experiments asking people to record, recall, and communicate about video recordings that people tend to put together events in hierarchical structure where the object of reference (e.g. a meeting agenda item) is at the top of the hierarchy and details discussing and referencing that object appear below. They refer to details at the very bottom as “behavioral primitives” – details that are so low level that they are often ignored in summary and communication. This structure roughly reflects the practice of producing meeting “minutes”, a summary record of what took pace at a meeting that is intended for general recap use cases. Theories in discourses find similar evidence of structures in written work documents. Intentional theory of discourse [26] posits that discourses follow a hierarchical structure with intentions guiding the discourse and discourse segments form individual sub-topics within the discourse.
"연대기적 구조와 같은 '분'은 담론과 인지 과학의 이론에 의해 뒷받침된다. Zacks 등[85]은 사람들에게 비디오 녹화물을 기록하고, 회상하고, 의사소통하도록 하는 실험을 통해 사람들이 참조 대상(예: 회의 안건 항목)이 계층 구조의 맨 위에 있고 그 대상을 논의하고 참조하는 세부 사항이 아래에 나타나는 계층 구조로 사건을 조합하는 경향이 있음을 보여준다. 가장 아래에 있는 세부 사항을 '행동 기본 요소'라고 하는데, 이는 너무 낮은 수준이어서 요약 및 커뮤니케이션에서 종종 무시되는 세부 사항이다. 이 구조는 일반적인 요약 사용 사례를 위해 회의에서 어떤 일이 진행되었는지에 대한 요약 기록인 회의 '회의록'을 작성하는 관행을 대략적으로 반영한다. 담화의 이론은 문서화된 업무 문서에서도 유사한 구조의 증거를 찾을 수 있다. 담화의 의도적 이론[26]은 담화가 담화를 이끄는 의도가 있는 계층적 구조를 따르고 담화 세그먼트가 담화 내에서 개별 하위 주제를 형성한다고 가정한다.
Mann et al. [49] studied letters, memos, newspapers, scientific articles and found that similar hierarchical relations hold between parts of written text. Moreover, hierarchical structure also emerges in our sensemaking of temporal events condensed in Rhetorical Structure Theory of text. Thus, there is compelling evidence in cognitive science about hierarchical structures in sense-making both during perception, and during expression of information.
Mann 등[49]은 편지, 메모, 신문, 과학 기사를 연구한 결과 텍스트의 각 부분 간에 유사한 계층적 관계가 존재한다는 사실을 발견했다. 또한, 텍스트의 수사 구조 이론에 응축된 시간적 사건에 대한 우리의 감각 형성에서도 계층적 구조가 나타난다. 따라서 인지 과학에서는 지각하는 동안과 정보를 표현하는 동안의 감각 형성에서 계층적 구조에 대한 설득력 있는 증거가 있다.
3. SYSTEM DESIGN
3.1 Design Rationale
Meeting recap supports complex organizational workflows that requires participants to scan through summaries, judge each summary block’s relevance to their own work, and decide how to act on it [4]. Naturalistic sense-making under constraints (e.g., limited time, multi-tasking) for such complex tasks has been shown to be impacted both by limitations of the technology, and interactions of the technology with the user’s context (e.g., how much context the user has about the meeting, or their time availability). Since an "ideal" summary can have many different representations for different users (e.g., most important points, full minutes, action items), using dialogue summarization to generate actual recap representations from people’s meetings and evaluating with them is necessary help bridge the gap between user expectations, and technology affordances [61, 70, 79]. However conceptualizing good representations is hard without well defined measures of quality [82]. Thus, we leverage the cognitive fit theory to conceptualize representations whose structure aligns with potential user needs [69] and represent them using "design rationales" [44].
회의 요약은 참가자가 요약을 훑어보고, 각 요약 블록이 자신의 업무와 관련성이 있는지 판단하고, 어떻게 행동할지 결정해야 하는 복잡한 조직 워크플로우를 지원한다[4]. 이러한 복잡한 작업에 대한 제약 조건(예: 제한된 시간, 멀티태스킹) 하에서 자연스러운 의사 결정은 기술의 한계와 기술 및 사용자의 컨텍스트와의 상호작용(예: 사용자가 회의에 대해 얼마나 많은 컨텍스트를 가지고 있는지 또는 시간 가용성)에 의해 영향을 받는 것으로 나타났다. "이상적인" 요약은 사용자마다 다양한 표현(예: 가장 중요한 요점, 전체 회의록, 실행 항목)을 가질 수 있으므로 대화 요약을 사용하여 사람들의 회의에서 실제 요약 표현을 생성하고 이를 평가하는 것은 사용자의 기대와 기술 어포던스 사이의 격차를 해소하는 데 도움이 된다[61, 70, 79]. 그러나 잘 정의된 품질 측정이 없으면 좋은 표현을 개념화하는 것은 어렵다[82]. 따라서 우리는 인지 적합성 이론을 활용하여 잠재적인 사용자 니즈에 부합하는 구조를 가진 표현을 개념화하고[69], "디자인 근거"[44]를 사용하여 이를 표현한다.
Design Rationales (DR) are used in HCI to evaluate computational support for complex tasks in user’s context. Design Rationales explicitly define representations, their supporting reasoning, and a criteria for their evaluation against reference tasks [44]. Since prior work has not explored the in-context usefulness of AI generated meeting recap to participants, we take an interpretivist approach to evaluate the design rationales using interviews. Our goal is to discover themes that capture relevant aspects of meeting recap in relation to usefulness for end user needs.
설계 근거(DR)는 HCI에서 사용자 컨텍스트에서 복잡한 작업에 대한 컴퓨팅 지원을 평가하는 데 사용된다. 설계 근거는 표현과 이를 뒷받침하는 추론, 참조 작업에 대한 평가 기준을 명시적으로 정의한다[44]. 이전 연구에서는 AI가 생성한 회의 요약이 참가자에게 맥락에서 얼마나 유용한지에 대한 연구가 없었기 때문에, 우리는 인터뷰를 통해 해석주의적 접근 방식을 취하여 설계 근거를 평가한다. 우리의 목표는 최종 사용자의 요구사항에 대한 유용성과 관련하여 회의 요약의 관련 측면을 포착하는 주제를 발견하는 것이다.
Inspired by design rationales, we ask – what shape should a meeting recap take? On one hand, we try to mimic the way that people take personal notes – focusing on only the most important information (e.g., decisions and action items [4]). On the other hand, some use cases for meeting recap may prioritize knowing how a decision was made as well the details of the decision itself [52, 79].
디자인적 근거에서 영감을 받아 우리는 회의 요약은 어떤 형태여야 할까요? 한편으로는 사람들이 개인적으로 메모하는 방식을 모방하여 가장 중요한 정보(예: 결정 및 실행 항목[4])에만 초점을 맞추려고 노력한다. 반면에, 회의 요약의 일부 사용 사례에서는 결정이 어떻게 내려졌는지와 결정 자체의 세부 사항을 파악하는 것을 우선시할 수도 있다[52, 79].
Both of these approaches have potential advantages and drawbacks. Since each represents a design rationale about what will be most useful to meeting participants, we formalize them below and then describe their operationalization as different user experiences to evaluate.
이 두 가지 접근 방식 모두 잠재적인 장점과 단점이 있다. 각각은 미팅 참가자에게 가장 유용한 것이 무엇인지에 대한 설계 근거를 나타내므로 아래에서 이를 공식화한 다음 평가할 수 있는 다양한 사용자 경험으로 운영 방식을 설명한다.
DR1: Personal note-taking: a meeting recap should be as short as possible and focus on outcomes to serve the users’ needs efficiently.
DR2: Meeting minutes: a meeting recap should summarize the entire meeting including discussions and outcomes within a hierarchical structure to enable broad use cases and contextual navigation.
DR1: 개인 메모 작성: 회의 요약은 가능한 한 짧게 작성하고 사용자의 요구 사항을 효율적으로 충족하기 위해 결과에 초점을 맞춰야 한다.
DR2: 회의록: 회의 요약은 광범위한 사용 사례와 맥락에 맞는 탐색이 가능하도록 계층 구조 내에서 토론과 결과를 포함한 전체 회의 내용을 요약해야 한다.
By focusing only on the most important outcomes of the meeting, the recap experience can be as brief as possible and thus save the user the time and energy of reviewing information that is less relevant after the meeting. Meeting minutes tend to employ a hierarchical structure that is supported by Zack et al’s [85] study that people perceive and understand events in hierarchy, where agenda items represent the high-level objects of discussion and details about that agenda item’s discussion are recorded beneath. Moreover, hierarchical structure also shows up in discourse analysis of people’s communication, and written documents of work, both of which are crucial elements of organizational collaborations [26, 49].
회의의 가장 중요한 결과에만 집중함으로써 요약 환경을 최대한 간략하게 만들 수 있으므로 사용자는 회의가 끝난 후 관련성이 낮은 정보를 검토하는 데 드는 시간과 에너지를 절약할 수 있다. 회의록은 계층 구조를 사용하는 경향이 있는데, 이는 사람들이 사건을 계층 구조로 인식하고 이해한다는 Zack 등[85]의 연구에 의해 뒷받침되는데, 안건 항목은 상위 수준의 논의 대상을 나타내고 해당 안건 항목의 논의에 대한 세부 사항은 그 아래에 기록된다. 또한 계층적 구조는 조직 협업의 중요한 요소인 사람들의 의사소통에 대한 담론 분석과 업무 문서에서도 나타난다[26, 49].
We designed two experiences that exemplify each design rationale (see Fig 1) respectively. The highlights experience (DR1) focuses on pulling out key points and action items from meetings as these help participants decide on the consensus on the decisions, as well as upcoming action items. The experience provides users a brief set of key points and action items from their meetings, each represented by one to two sentence summaries.
우리는 각 설계 근거를 보여주는 두 가지 경험을 각각 디자인했다(그림 1 참조). 하이라이트 경험(DR1)은 회의에서 핵심 사항과 실행 항목을 도출하는 데 초점을 맞췄는데, 이는 참가자들이 의사 결정에 대한 합의와 향후 실행 항목을 결정하는 데 도움이 되기 때문이다. 이 경험은 사용자에게 회의의 핵심 사항과 실행 항목에 대한 간략한 요약을 제공하며, 각각 1~2개 문장의 요약으로 표시된다.
In contrast, the hierarchical experience (DR2) leverages a “chapterization” strategy to break the meeting into parts and to give each part a representative title. Beneath, each chapter, a user can explore lower level summaries. And beneath those summaries is the raw transcript. Unlike the highlights experiences, the hierarchical experience captures the entirety of the meeting in a structure that should be intuitive for users.
이와 대조적으로 계층적 경험(DR2)은 '챕터화' 전략을 활용하여 회의를 여러 부분으로 나누고 각 부분에 대표 제목을 부여한다. 각 챕터 아래에서 사용자는 더 낮은 수준의 요약을 탐색할 수 있다. 그리고 그 요약 아래에는 원시 녹취록이 있다. 하이라이트 경험과 달리 계층적 경험은 사용자에게 직관적이어야 하는 구조로 회의 전체를 캡처한다.
We also designed these experiences to provide opportunities for users to correct, direct, and use what they saw in front of them in ways that we hoped would provide signals our models could learn from in order to become more aligned with users’ expectations [14]. In order to achieve this, these interactions need to have relatively consistent meaning when users apply them (alignment), they need to be performed in cases where the model was wrong (informative). Further, the users themselves need to understand what they are doing well enough to teach the model (situatedness), and they need to perform these actions frequently enough that we could gather a reasonable amount of training data over time (quantity). In our interviews, in addition to focusing on the proposed design’s usefulness in providing recap support, we also focused on what users said and did in the UX to improve the summaries. We argue that these interactions provide early indicators of the type and quality of training data we would likely get in a deployment at scale to support meeting recap and improving the meeting recap AI through feedback. We provide full description of the two user experiences with specific details about these interface components in Section 3.3.
또한 사용자가 눈앞에서 본 것을 수정하고, 지시하고, 사용할 수 있는 기회를 제공하여 모델이 사용자의 기대에 더 부합하도록 학습할 수 있는 신호를 제공하고자 이러한 경험을 설계했다[14]. 이를 위해서는 이러한 상호작용이 사용자가 적용했을 때 비교적 일관된 의미를 가져야 하며(정렬), 모델이 틀린 경우에도 수행되어야 한다(정보 제공). 또한, 사용자 스스로가 모델을 학습시킬 수 있을 만큼 자신이 무엇을 잘하고 있는지 이해해야 하며(적절성), 시간이 지남에 따라 적절한 양의 학습 데이터를 수집할 수 있을 만큼 자주 이러한 작업을 수행해야 한다(양). 인터뷰에서는 요약 지원을 제공하는 데 있어 제안된 디자인의 유용성에 초점을 맞추는 것 외에도 요약 기능을 개선하기 위해 사용자가 UX에서 어떤 말을 하고 어떤 행동을 했는지에 대해서도 집중했다. 이러한 상호작용은 미팅 요약 지원을 위한 대규모 배포에서 얻을 수 있는 학습 데이터의 유형과 품질에 대한 초기 지표를 제공하고 피드백을 통해 미팅 요약 AI를 개선할 수 있다고 주장한다. 섹션 3.3에서 이러한 인터페이스 구성 요소에 대한 구체적인 세부 사항과 함께 두 가지 사용자 경험에 대한 자세한 설명을 제공한다.
While prior recap studies [78] have highlighted needs for both quick takeaways and detailed hierarchical discussions, we are the first to 1) Formalize the needs as design rationales to structure exploration, and provide supporting reasoning from cognitive science, 2) Design recap systems to operationalize these rationales to evaluate their fit in addressing target recap needs.
이전의 요약 연구[78]에서는 빠른 요약과 상세한 계층적 논의에 대한 필요성이 강조되었지만, 1) 탐색을 구조화하기 위한 설계 근거로 이러한 필요성을 공식화하고 인지 과학의 추론을 뒷받침하며, 2) 이러한 근거를 운영하여 목표 요약 요구 사항을 해결하는 데 적합성을 평가하는 요약 시스템을 설계한 것은 우리 팀이 처음이다.

- Fig. 1. Meeting recap UX that exemplify design rationales
3.2 Modeling
3.2.1 Highlights model. Highlights experience is generated from four sequential transformer models [76], two for the key points, and two for the action items in the meeting. For each note or action item, the first model is an extractive model that takes an utterance with its surrounding context as an input, and classifies it as a key point or action item. The second is an abstractive model that gets the utterances identified as a key point or action item from the previous model and rewrites them using the surrounding utterances as their context [15]. Key points and action items in the “highlights” experience both use fine-tuned deBERTa with 12 transformer layers [28] for their extractive part. They were trained on ICSI and AMI labeled datasets [31]. Their input size is 100 tokens which are extracted from the relevant utterance and enough context from previous and next utterances to fill the 100 tokens input size.
3.2.1 하이라이트 모델. 하이라이트 경험은 4개의 순차적 변환기 모델[76]에서 생성되는데, 이 중 2개는 회의의 요점에 대한 모델이고 2개는 회의의 실행 항목에 대한 모델이다. 각 노트 또는 실행 항목에 대해 첫 번째 모델은 주변 컨텍스트와 함께 발화를 입력으로 받아 키포인트 또는 실행 항목으로 분류하는 추출 모델이다. 두 번째 모델은 이전 모델에서 키포인트 또는 액션 아이템으로 식별된 발화를 가져와 주변 발화를 문맥으로 사용하여 다시 작성하는 추상 모델이다[15]. '하이라이트' 경험의 핵심 요점과 행동 항목은 모두 추출 부분에 12개의 트랜스포머 레이어[28]로 미세 조정된 deBERTa를 사용한다. 이들은 ICSI 및 AMI 레이블이 지정된 데이터 세트에 대해 학습되었다[31]. 입력 크기는 관련 발화에서 추출된 100개의 토큰과 이전 및 다음 발화에서 100개의 토큰 입력 크기를 채울 수 있는 충분한 컨텍스트이다.
For the abstractive part, both key points and action items models use fine-tuned BART [45]. This was trained on ICSI and AMI labeled datasets as well [31]. The models get the input utterance identified as a key point or action item by the extractive model and a surrounding context 500 tokens. The output of the model is the rephrased action item or note in third person. Thus, the abstractive model relies on a supportive extractive model which identifies the relevant context from the surrounding utterances in order to make BART [45] focus on the important information in the context. e.g., if the extractive model identified the following as an action item - “Serena: I will finish this by Friday”, the abstractive model will rephrase it as “Serena will finish the slides by Friday”. In this example, the abstractive model replaces “this” with “slides” that Serena referenced earlier. Writing the note in 3rd person and with context makes it easy to understand for a broader audience [79]. Figure 3a (left) illustrates this pipeline. Please refer to Cohen et al. [15] for more details on the models.
추상적인 부분의 경우, 핵심 포인트와 액션 항목 모델 모두 미세 조정된 BART를 사용한다[45]. 이 모델은 ICSI 및 AMI 레이블이 지정된 데이터 세트에 대해서도 학습되었다[31]. 모델은 추출 모델과 주변 컨텍스트 500 토큰에 의해 키포인트 또는 액션 항목으로 식별된 입력 발화를 가져온다. 모델의 출력은 3인칭으로 재구문된 행동 항목 또는 메모이다. 따라서 추상 모델은 BART [45]가 문맥의 중요한 정보에 집중할 수 있도록 주변 발화에서 관련 문맥을 식별하는 지원 추출 모델에 의존한다. 예를 들어, 추출 모델이 다음을 행동 항목으로 식별한 경우 "세레나: 금요일까지 이 작업을 마칠 것이다."라는 문장을 추상 모델은 "세레나는 금요일까지 슬라이드를 마칠 것이다."라고 바꾸어 표현한다. 이 예에서 추상화 모델은 "이"를 세레나가 앞서 언급한 "슬라이드"로 대체한다. 3인칭으로 문맥과 함께 메모를 작성하면 더 많은 청중이 쉽게 이해할 수 있다[79]. 그림 3a(왼쪽)는 이 파이프라인을 보여준다. 모델에 대한 자세한 내용은 Cohen 등[15]을 참조하세요.
3.2.2 Hierarchical (“Chapters”) model. We generate the hierarchical (“chapters”) experience in two steps – 1) Segment the entire meeting transcript into parts where each part corresponds to a sub-topic or set of topics (Figure 2), 2) Synthesize a title and a set of notes representing each part (Figure 3a right half).
3.2.2 계층적("챕터") 모델. 1) 전체 회의 내용을 각 부분이 하위 주제 또는 주제 집합에 해당하는 부분으로 세분화하고(그림 2), 2) 각 부분을 나타내는 제목과 노트 집합을 합성하는 두 단계로 계층적("챕터") 경험을 생성한다(그림 3a 오른쪽 절반).
For step (1), we follow the text-tiling approach for segmenting meetings into chapters (topics) [29, 75]. Segmentation is based on the idea of document segmentation using lexical cohesion [29]. The segmentation boundary is determined so that distribution of representative words within the segment are similar and distribution of representative words across segments are dissimilar [22, 60].
(1)의 경우, 회의를 챕터(주제)로 세분화하는 텍스트 타일링 접근법을 따른다[29, 75]. 세분화는 어휘 응집력을 이용한 문서 세분화 아이디어를 기반으로 한다[29]. 세그먼트 내 대표 단어의 분포는 유사하고 세그먼트 간 대표 단어의 분포는 서로 다르도록 세그먼트 경계가 결정된다[22, 60].

Fig. 2. We apply text-tiling segmentation process using BERT for segmenting long sequences of meeting dialogues into individual chapters (topics) [29]. Utterance refers to a single sentence spoken by a meeting participant in the transcript.
그림 2. 긴 회의 대화 시퀀스를 개별 챕터(주제)로 분할하기 위해 BERT를 이용한 텍스트-타일링 분할 프로세스를 적용한다[29]. 발화란 트랜스크립트에서 회의 참가자가 말한 단일 문장을 의미한다.
Text-tiling is a method for transcript segmentation that breaks a long input sequence into smaller windows of overlapping sequences. Each window is then labeled with the classifier for topic boundaries and the final boundary is identified with max-voting of the boundaries of the individual windows. (see Figure 2 for an illustration). To train the segmentation model, we annotate a dataset of meetings with chapter boundaries. We recruit annotators on a the UHRS crowd-sourced platform1 and ask them to mark utterances in the transcript that mark the end of one topic of a meeting and beginning of the next as chapter boundaries. This dataset has 12,600 meetings with 126,872 segmentation blocks. The train, dev, test split was 70%, 15%, 15% respectively. We compensated the annotators $10 per transcript for their time. Using the annotated dataset we train a BART [45] classification model to predict if an utterance is the start of a new segment. For prediction, we split the transcript into overlapped windows of 30 utterances and stride of 10 utterances. We then apply the classifier to each utterance in the window. We then combine predictions by maximum pooling to arrive at segment boundaries. We adopt the sliding window approach for prediction because average meeting transcripts are much longer than the input length of transformer models (token limit of 512) [45]. The result of this step is the meeting transcript segmented into blocks with each block corresponding to one topic or a set of coherent topics (see Figure 2).
텍스트 줄바꿈은 긴 입력 시퀀스를 겹치는 시퀀스의 작은 창으로 분할하는 트랜스크립트 분할 방법이다. 그런 다음 각 창에 주제 경계를 위한 분류기로 레이블을 지정하고 개별 창 경계의 최대 투표를 통해 최종 경계를 식별한다. (그림 2를 참조하세요). 세분화 모델을 훈련하기 위해 챕터 경계가 있는 회의 데이터 세트에 주석을 달았다. UHRS 크라우드 소싱 플랫폼1에서 주석 작성자를 모집하여 회의의 한 주제의 끝과 다음 주제의 시작을 표시하는 발언을 챕터 경계로 표시하도록 요청한다. 이 데이터 세트에는 12,600개의 회의와 126,872개의 세그먼트 블록이 있다. 훈련, 개발, 테스트 분할은 각각 70%, 15%, 15%였다. 주석 작성자에게는 트랜스크립트당 10달러의 보상을 지급했다. 주석이 달린 데이터 세트를 사용하여 발화가 새로운 세그먼트의 시작인지 예측하기 위해 BART [45] 분류 모델을 훈련했다. 예측을 위해 대본을 30개의 발화 구간과 10개의 발화 구간으로 겹치는 창으로 나눈다. 그런 다음 윈도우의 각 발화에 분류기를 적용한다. 그런 다음 최대 풀링으로 예측을 결합하여 세그먼트 경계에 도달한다. 평균 회의 녹취록이 트랜스포머 모델의 입력 길이(토큰 제한 512)보다 훨씬 길기 때문에 예측을 위해 슬라이딩 윈도우 접근 방식을 채택했다[45]. 이 단계의 결과는 하나의 주제 또는 일관된 주제 집합에 해당하는 각 블록이 있는 블록으로 분할된 회의 기록이다(그림 2 참조).
In step (2), we generate chapter heading and notes for each of these blocks using deBERTa with
(2)단계에서는 다음과 같이 deBERTa를 사용해 각 블록에 대한 챕터 제목과 노트를 생성한다.
12 transformer layers [28], same as the highlights model. This step is similar to the rephrasing in step (2) of the highlights model, where the model takes in sequence of utterances as input, and rephrases them in 3rd person. We train a transformer model on a dataset of short (eight) dialogue utterances and their corresponding summary. This dataset has 1M meeting utterance-summary pairs. The model generates notes, one for each sequential chunk of eight utterances in the meeting utterance blocks. The chapter headings are generated by a third deBERTa with 12 transformer layers [28] model that is trained on a dataset of meeting utterances, and their corresponding topic assignment. This dataset has 1M meeting utterance topic assignment pairs and was also obtained through annotation on the UHRS crowd-work platform. The final output from the three models is a set of topics marked with topic headings, and a set of notes under each of those topics that represent the entire meeting summary. This result is very similar to a set of meeting minutes. Figure 3a (right) illustrates this pipeline.
12개의 트랜스포머 레이어[28], 하이라이트 모델과 동일한다. 이 단계는 하이라이트 모델의 2단계에서 발화 시퀀스를 입력으로 받아 3인칭으로 다시 표현하는 것과 유사한다. 짧은 대화 발화(8개)와 그에 해당하는 요약으로 구성된 데이터 세트로 트랜스포머 모델을 훈련한다. 이 데이터 세트에는 1백만 개의 회의 발화-요약 쌍이 있다. 이 모델은 회의 발화 블록에 있는 8개 발화의 순차적 청크마다 하나씩 노트를 생성한다. 챕터 제목은 회의 발화 데이터 세트와 해당 주제 할당에 대해 학습된 12개의 트랜스포머 레이어[28] 모델을 갖춘 세 번째 deBERTa에 의해 생성된다. 이 데이터 세트에는 1백만 개의 회의 발화 주제 할당 쌍이 있으며 UHRS 크라우드워크 플랫폼의 주석을 통해 얻기도 했다. 세 가지 모델의 최종 출력은 주제 제목으로 표시된 주제 집합과 각 주제 아래에 전체 회의 요약을 나타내는 메모 집합이다. 이 결과는 회의록 세트와 매우 유사한다. 그림 3a(오른쪽)는 이 파이프라인을 보여준다.
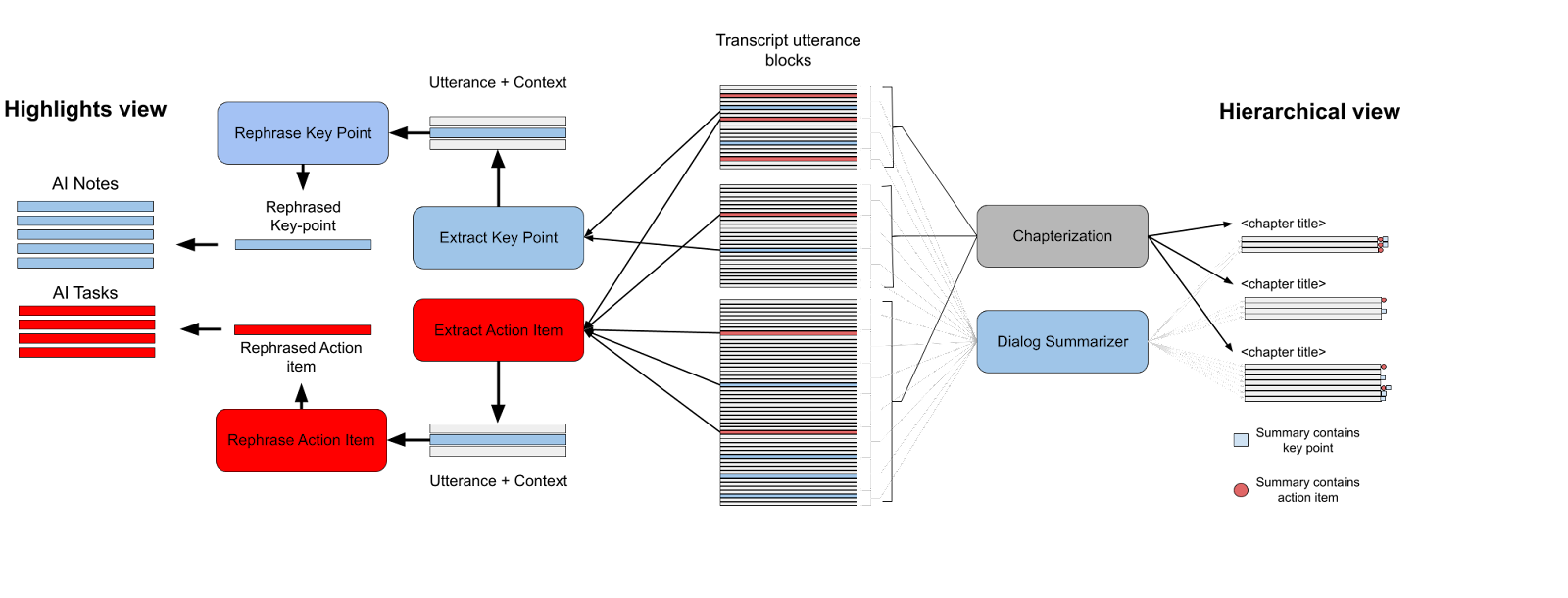
(a) Summarization pipeline that generates the two experiences illustrated below. Highlights experience (left) extracts top-N utterances as key-points or action items followed by rephrasing in 3rd person with context, and displaying as a sequence (Figure 1a). Hierarchical experience (right) segments the entire meeting transcript into sections, generates summaries for each section in 3rd person, and represents them sequentially in a minutes like format (Figure 1b). Summaries that contain key points or action items are marked with a corresponding number of stars and checkboxes respectively. Each rectangular block is a transformer model.
(a) 아래 그림과 같이 두 가지 경험을 생성하는 요약 파이프라인. 하이라이트 경험(왼쪽)은 상위 N개의 발언을 키포인트 또는 실행 항목으로 추출한 다음 컨텍스트에 따라 3인칭으로 다시 표현하고 시퀀스로 표시한다(그림 1a). 계층적 경험(오른쪽)은 전체 회의 내용을 섹션으로 분류하고, 각 섹션에 대한 요약을 3인칭으로 생성한 다음, 이를 회의록과 같은 형식으로 순차적으로 표시한다(그림 1b). 요점이나 실행 항목이 포함된 요약에는 각각 해당되는 수의 별과 체크박스가 표시된다. 각 직사각형 블록은 변압기 모델이다.
Fig. 3. Illustration of the modeling pipeline that we use to generate the two recap experiences (3a).
그림 3. 두 가지 요약 경험을 생성하는 데 사용하는 모델링 파이프라인의 그림(3a).
3.3 Prototype User Experience
We refer to “key points” as “AI notes” and “action items” as “AI tasks” in the UX for ease of understanding of participants. We use the shorthand terminology “notes” and “tasks” in the context of UX and results. To refer to both “notes” and “tasks” together, we use the term “summary”.
참가자의 이해를 돕기 위해 UX에서는 '키 포인트'를 'AI 노트'로, '실행 항목'을 'AI 작업'으로 지칭한다. UX와 결과의 맥락에서 "노트"와 "작업"이라는 약칭을 사용한다. '노트'와 '작업'을 함께 지칭할 때는 '요약'이라는 용어를 사용한다.
We prototype the recap experiences on an HTML webapp. The users start with a text area where they can copy-paste a transcript of a recorded meeting. Clicking “Process” sends the transcript to the backend for generating the recap insights for the two experiences The backend uses the two summarization pipelines described above to generate the recap data which is sent back to the webapp frontend. Once the recap data is received from the two summarization pipelines, we populate the two tabs “Highlights” and “Hierarchical” with the data, formatting it as shown (Figure 3).
우리는 HTML 웹앱에서 요약 경험을 프로토타입으로 제작했다. 사용자는 녹화된 회의 내용을 복사하여 붙여넣을 수 있는 텍스트 영역에서 시작한다. "프로세스"를 클릭하면 두 경험에 대한 요약 인사이트를 생성하기 위해 기록이 백엔드로 전송된다. 백엔드는 위에서 설명한 두 가지 요약 파이프라인을 사용하여 웹앱 프런트엔드로 다시 전송되는 요약 데이터를 생성한다. 두 요약 파이프라인에서 요약 데이터를 받으면 그림 3과 같이 서식을 지정하여 '하이라이트' 및 '계층' 탭을 데이터로 채운다(그림 3).
The highlights view displays a sequence of notes selected by the key points extractive model, and rephrased by the key points abstractive model. The action items displays a sequence of action items selected by the action items extractive model, and rephrased by the action items abstractive model. Against each action item, the UI displays an “assigned to” field and “date” field which is initially empty, and can be filled by participants to reflect the assignee and the deadline for the action item. Users can see more context for both notes and action items by clicking on the three dots at the end of each item line and selecting “show context”. This opens up a tooltip displaying upto three transcript utterances before and after the utterance where the algorithm detected the notes or action item.
하이라이트 보기에는 요점 추출 모델에 의해 선택되고 요점 추상화 모델에 의해 다시 표현된 일련의 노트가 표시된다. 작업 항목에는 작업 항목 추출 모델에 의해 선택되고 작업 항목 추상화 모델에 의해 재구문된 일련의 작업 항목이 표시된다. 각 실행 항목에 대해 UI에는 '할당 대상' 필드와 '날짜' 필드가 표시되며, 처음에는 비어 있지만 참가자가 할당자와 실행 항목의 마감일을 반영하기 위해 채울 수 있다. 사용자는 각 항목 줄 끝에 있는 점 3개를 클릭해 '컨텍스트 표시'를 선택하면 노트와 실행 항목 모두에 대한 자세한 컨텍스트를 볼 수 있다. 그러면 알고리즘이 노트 또는 작업 항목을 감지한 발화 전후의 최대 3개의 트랜스크립트 발화를 표시하는 도구 설명이 열린다.
The hierarchical view displays a summary of the entire meeting segmented into topics. Each topic is made up of a topic heading that summarizes the topic name, followed by a one line summary of the topic, and the timespan (in minutes) of the meeting that the topic covers. Clicking the timespan opens up the topic into a list of summaries that provide a rolling summary of that section of the meeting. Each summary is represented by a summary text, followed by a timestamp that corresponds to the first transcript utterance included in the summary. Clicking each summary item further opens up the constituent transcript utterances that make up the summary. If the summarization algorithm detects one or more important “key points” in the topic, stars are displayed to the left of the summary and also next to the chapter title that contains the key point summary. Similarly, If the summarization algorithm detects one or more action items in the topic, checkboxes are displayed to the left of the summary and also next to the chapter title that contains the action item summary. If the user clicks on the star or checkbox, the the chapter is expanded into individual summaries with the summary containing the key point or action item emphasized by the respective star or checkbox.
계층 보기에는 전체 미팅이 주제별로 분류된 요약이 표시된다. 각 주제는 주제 이름을 요약한 주제 제목, 주제에 대한 한 줄 요약, 주제가 포함된 회의 시간(분)으로 구성된다. 기간을 클릭하면 해당 주제가 회의의 해당 섹션에 대한 롤링 요약을 제공하는 요약 목록으로 열린다. 각 요약은 요약 텍스트와 요약에 포함된 첫 번째 녹취록 발언에 해당하는 타임스탬프로 표시된다. 각 요약 항목을 클릭하면 요약을 구성하는 녹취록 발화들이 추가로 열린다. 요약 알고리즘이 주제에서 하나 이상의 중요한 '요점'을 감지하면 요약의 왼쪽과 요점 요약이 포함된 장 제목 옆에 별표가 표시된다. 마찬가지로 요약 알고리즘이 주제에서 하나 이상의 작업 항목을 감지하면 요약 왼쪽과 작업 항목 요약이 포함된 장 제목 옆에 확인란이 표시된다. 사용자가 별표 또는 확인란을 클릭하면 해당 장이 개별 요약으로 확장되고 해당 별표 또는 확인란이 강조하는 핵심 사항 또는 작업 항목이 포함된 요약이 표시된다.
In order to explore interactions that could be used as training data to align [14] the model behavior with user expectations, we implemented various features that would allow the user to correct and direct the model. In the highlights view, A user can directly edit any suggested note or action item. They can also add or remove notes and action items from the lists that are automatically generated. Similarly in the hierarchical view, a user can directly edit any summary or even the chapter titles. Users can also remove an action item, but they cannot remove a summary because doing so would render some of the raw meeting transcript inaccessible. However users can add or remove stars/checkboxes from various low-level summaries to flag moments of the meeting as key points/action items or remove the same, respectively. We also provide basic sharing functionality by providing a “share to chat” option at the top of the experience.
모델 동작을 사용자의 기대에 맞추기 위한 학습 데이터로 사용할 수 있는 상호작용을 탐색하기 위해[14], 사용자가 모델을 수정하고 지시할 수 있는 다양한 기능을 구현했다. 하이라이트 보기에서 사용자는 제안된 노트나 작업 항목을 직접 편집할 수 있다. 또한 자동으로 생성된 목록에서 노트와 작업 항목을 추가하거나 제거할 수도 있다. 계층 구조 보기에서도 마찬가지로 사용자는 요약이나 장 제목을 직접 편집할 수 있다. 사용자는 작업 항목도 제거할 수 있지만, 요약은 제거하면 일부 원시 회의 녹취록에 액세스할 수 없게 되므로 제거할 수 없다. 그러나 사용자는 다양한 하위 수준 요약에서 별표/체크박스를 추가하거나 제거하여 회의의 중요한 순간을 요점/행동 항목으로 표시하거나 제거할 수 있다. 또한 경험 상단에 '채팅으로 공유' 옵션을 제공하여 기본적인 공유 기능도 제공한다.
4. METHODS
4.1 Participants
We conducted our evaluation of the two recap experiences through semi-structured interviews with seven participants. We recruited the participants through internal lists and emails. When the participants agreed for the study, we setup a time of 90 minutes over video conferencing for the interview. Since we recruited employees within the organization as participants, we did not compensate them.
7명의 참가자와 반구조화된 인터뷰를 통해 두 가지 요약 경험에 대한 평가를 실시했다. 참가자는 내부 목록과 이메일을 통해 모집했다.참가자가 연구에 동의하면 화상 회의를 통해 90분 동안 인터뷰 시간을 설정했다.
4.2 Tasks and procedures
Each interview session was conducted by two authors of the paper, with one leading the interview, and the other taking notes. At the start of each session, the interview lead explained the interview process to the participants and solicited their consent to record the session and use transcript of one of their recent meetings to generate meeting recap and study its usefulness. We had informed participants in advance about using one of their meetings to generate the recap and study its contextual usefulness so that they could record a meeting prior to the study after seeking consent from the participants of the respective meeting. All the participants’ recorded meetings that they brought to the study were between one to two weeks old. We started the interview by asking the participants to copy-paste the transcript of the meeting that they had decided to discuss, and hit process to start generating the recap experiences. We did this in the beginning because the system took several minutes to generate the recap and we used that time to ask preliminary questions. The prototype did not log any user data, and we did not have access to the contents of the meeting transcripts that participants chose to use for the study. We also asked participants to share their screen during the study so we could observe their interactions with the recap experiences as we proceeded through the interview.
각 인터뷰 세션은 두 명의 논문 저자가 진행했으며, 한 명은 인터뷰를 주도하고 다른 한 명은 메모를 작성했다. 각 세션이 시작될 때 인터뷰 진행자는 참가자에게 인터뷰 프로세스를 설명하고 세션을 녹음하고 최근 회의 중 하나의 녹취록을 사용하여 회의 요약을 생성하고 그 유용성을 연구하는 데 동의를 구했다. 참가자들에게 회의 요약본을 생성하고 맥락적 유용성을 연구하기 위해 회의 중 하나를 사용한다는 사실을 미리 알려 해당 회의 참가자들에게 동의를 구한 후 연구 전에 회의를 녹음할 수 있도록 했다. 참가자들이 연구에 가져온 녹음된 회의는 모두 1~2주 전의 것이었다. 참가자들에게 논의하기로 결정한 회의의 녹취록을 복사하여 붙여넣고 프로세스를 눌러 요약 경험을 생성하도록 요청하는 것으로 인터뷰를 시작했다. 처음에 이렇게 한 이유는 시스템이 요약본을 생성하는 데 몇 분이 걸렸고 그 시간을 예비 질문을 하는 데 사용했기 때문이다. 프로토타입은 사용자 데이터를 기록하지 않았으며, 참가자가 연구에 사용하기로 선택한 회의 녹취록의 내용에는 액세스할 수 없었다. 또한 인터뷰를 진행하면서 요약 경험에 대한 상호작용을 관찰할 수 있도록 참가자에게 연구 중 화면을 공유해 달라고 요청했다.
We designed the interview questions so that we could 1) Understand people’s prior notetaking practices, 2) Capture the opinions of the participants when making sense of the recap, 3) Observe
인터뷰 질문은 1) 사람들의 이전 노트 필기 관행을 이해하고, 2) 요약본을 이해할 때 참가자의 의견을 포착하고, 3) 관찰할 수 있도록 설계했다.
| Demographic information | ||
| Gender | Male Female |
50% 50% |
| 21-25 | 17% | |
Age |
26-30 31-35 36-40 |
50% – 17% |
| 46-50 | 17% | |
| North America | 66% | |
| Region | Greater China India | 33% 0% |
| Middle-east | 0% | |
| Research | 58.3% | |
Profession |
Software engineer User engineer Design/creative | 16.7% 8.3% 8.3% |
| Other | 8.3% | |
Table 1. Demographic details of interview participants
표 1. 인터뷰 참가자의 인구통계학적 세부 정보
how participants interacted with the recap to validate their understanding of the meeting, and fix any issues they came across. Observing participants perform tasks instead of simply eliciting problems about the recap from them evokes higher order cognitive capabilities [16] and is expected to give data that is closer in alignment to their actual understanding of the recap. Thus, we divided the interview questions into three sections – 1) General participant background and meeting habits, 2) Questions and tasks for the highlights view, 3) Questions and tasks for the hierarchical view. For both highlights and hierarchical sections we ask participants questions about the i) general usefulness of the experience, ii) missing summaries and the reasons, iii) inaccurate and irrelevant summaries and the reasons, iv) sharing the summaries. For missing, inaccurate and irrelevant summaries, we also ask participants to interact with the UX and add, edit or remove the summaries respectively and think aloud through the process so that we get insights on the reasons for participant’s actions. To get natural insights, we made sure to let the participants explore the UX on their own, and only direct them when absolutely necessary (e.g., they get stuck with an interaction). Think aloud [19] is a popular HCI method to elicit user expectations, and capture the thought process of participants as they interact with the output of a system. We provide the complete question set that we used for the interviews in the supplementary material. The study was reviewed and approved by the institution’s review board.
참가자가 요약본과 상호작용하는 방식을 관찰하여 미팅에 대한 이해도를 검증하고 발견한 문제를 해결할 수 있다. 참가자로부터 요약에 대한 문제를 단순히 도출하는 대신 과제를 수행하는 모습을 관찰하는 것은 고차원적인 인지 능력을 불러일으키며[16], 요약에 대한 참가자의 실제 이해에 더 근접한 데이터를 제공할 것으로 기대된다. 따라서 인터뷰 질문은 1) 일반적인 참가자 배경 및 회의 습관, 2) 하이라이트 보기를 위한 질문 및 과제, 3) 계층적 보기를 위한 질문 및 과제의 세 가지 섹션으로 나누었다. 하이라이트 및 계층적 보기 섹션 모두에 대해 참가자에게 i) 경험의 일반적인 유용성, ii) 누락된 요약과 그 이유, iii) 부정확하고 관련 없는 요약과 그 이유, iv) 요약 공유에 대해 질문한다. 누락된 요약, 부정확한 요약, 관련성 없는 요약의 경우, 참가자에게 UX와 상호작용하여 요약을 추가, 편집 또는 삭제하도록 요청하고 그 과정을 통해 참가자의 행동 이유에 대한 인사이트를 얻을 수 있도록 큰 소리로 생각하도록 했다. 자연스러운 인사이트를 얻기 위해 참가자가 스스로 UX를 탐색하도록 하고, 꼭 필요한 경우(예: 인터랙션이 막히는 경우)에만 참가자에게 지시하도록 했다. 소리 내어 생각하기[19]는 사용자의 기대를 이끌어내고 참가자가 시스템의 결과물과 상호 작용할 때 사고 과정을 포착하는 데 널리 사용되는 HCI 방법이다. 인터뷰에 사용한 전체 질문 세트는 보충 자료에서 확인할 수 있다. 이 연구는 기관의 심의위원회에서 검토 및 승인을 받았다.
4.3 Analysis
After each interview, one of the authors went through the recordings and transcripts and added any missing notes to those taken during the interview. At the end of all the interviews, we had about 7 hours of recordings, associated transcripts, and notes taken during the interviews. We analyzed the interviews using thematic analysis [9]. One author went through the transcripts line by line and assigned open codes, additionally using the notes taken during the interviews. Following established coding practices, we inductively assigned codes to reflect what participants said, and did during the interview, and avoided codes that reflect prior understanding of the coder [47, 51]. Our codes captured the general opinion of the participants with respect to the usefulness of the experiences (e.g., “this is useful”), how they imagined using the recap (e.g., “planning upcoming tasks”), and their challenges associated with using it (e.g., “ambiguous note”). We also made sure to code participants’ interactions with the UX during the study to understand how they modified the summaries to align [14] it better with their own preferences and what UX interactions enabled them to do so (e.g., “looks up context”, “edits summary”).
각 인터뷰가 끝나면 저자 중 한 명이 녹음과 대본을 검토하고 인터뷰 중에 누락된 메모를 추가했다. 모든 인터뷰가 끝났을 때 약 7시간 분량의 녹음과 관련 대본, 인터뷰 중 작성한 메모를 확보했다. 우리는 주제별 분석[9]을 사용하여 인터뷰를 분석했다. 한 명의 저자가 녹취록을 한 줄 한 줄 검토하고 오픈 코드를 할당했으며, 인터뷰 중에 작성한 메모를 추가로 사용했다. 확립된 코딩 관행에 따라 귀납적으로 코드를 할당하여 참가자가 인터뷰 중에 말하고 행동한 내용을 반영하고 코더의 사전 이해를 반영하는 코드는 피했다[47, 51]. 코드는 경험의 유용성(예: "유용하다"), 요약의 사용 방법(예: "향후 작업 계획"), 요약 사용과 관련된 어려움(예: "모호한 메모")에 관한 참가자의 일반적인 의견을 포착했다. 또한 연구 기간 동안 참가자들이 요약본을 자신의 선호도에 더 잘 맞추기 위해[14] 어떻게 수정했는지, 그리고 어떤 UX 상호작용을 통해 그렇게 할 수 있었는지(예: "문맥 조회", "요약본 편집")를 파악하기 위해 참가자들이 UX와 상호작용한 내용을 코딩하도록 했다.
After coding each interview session, the primary author refined the codes through discussions with another author to resolve any disagreements. At the end of the coding session, we had about 143 codes that reflected various dimensions of recap that we wanted to study. We grouped the final set of codes into themes using affinity diagramming [30]. We performed the affinity diagramming step using Microsoft Excel.
각 인터뷰 세션을 코딩한 후 주 저자는 다른 저자와의 토론을 통해 코드를 다듬어 의견 차이를 해결했다. 코딩 세션이 끝났을 때 연구하고자 하는 요약의 다양한 차원을 반영하는 약 143개의 코드가 완성되었다. 최종 코드 세트는 선호도 다이어그램화[30]를 사용하여 테마로 그룹화했다. 선호도 다이어그램화 단계는 MS Excel을 사용하여 수행했다.
5. RESULTS
| 참가자 미팅 | |
| 1 | 60분 동안 진행된 연구 프로젝트 회의. 참석자는 연구 인턴과 프로젝트 책임자였다. |
| 2 | 컴퓨터 아키텍처를 주제로 한 45분간의 강연과 15분간의 Q&A. |
| 3 | 연구 멘토와 연구 인턴 간의 60분간의 연구 업데이트. |
| 4 | 두 명의 연구 멘토와 한 명의 연구 인턴이 '논문 제출'이라는 의제를 가지고 연구 그룹 회의를 진행한다. |
| 5 | 한 연구팀과 한 제품팀, 두 팀 간의 프로젝트 킥오프 미팅. 안건은 연구팀과 제품팀 간의 협업을 소개하는 것이었다. 참석자는 연구팀 소속으로 자동차를 운전하면서 회의에 참석했다. 회의에 부분적으로만 집중할 수 있었다 |
| 6 | 연구 멘토와 연구 인턴이 매주 60분 동안 연구 업데이트를 진행한다. |
| 7 | 분석에 대한 토론, 설문조사 결과에 대한 논의, 최소 3명이 회의에 참석. 최소 2명 이상의 인턴과 최소 1명 이상의 멘토. |
Table 2. Overview of meetings
5.1 General meeting habits and meetings overview
Figure 2 provides an overview of the meetings of our participants. Generally, all participants reported that they take notes in one way or another during meetings. All took some version of digital notes while two participants also took physical notes with pen and paper. Four preferred putting notes into the chat or using a collaborative document format like google docs. Six participants also shared notes with others sometimes. Four participants suggested that their note-taking generally focused on To-Do’s and task tracking.
그림 2는 참가자들의 회의에 대한 개요를 보여준다. 일반적으로 모든 참가자는 회의 중에 어떤 방식으로든 메모를 한다고 답했다. 모두 디지털 메모를 사용했으며, 2명의 참가자는 펜과 종이를 사용하여 실제 메모를 하기도 했다. 4명은 채팅에 메모를 입력하거나 Google 문서와 같은 협업 문서 형식을 사용하는 것을 선호했다. 6명의 참가자는 가끔 다른 사람들과 노트를 공유하기도 했다. 4명의 참가자는 일반적으로 할 일과 작업 추적에 중점을 두고 메모를 작성한다고 답했다.
Participants reported several different strategies for recapping meetings: 1) Three asked someone who attended, 2) Three Used the transcript, 3) Five Watched recording 4) One indicated reviewing presented slides and 5) Two reviewed chat. These numbers are not mutually exclusive as each participant indicated multiple strategies for recap depending on their needs and time availability. Table 3 provides a summary of general meeting habits across all participants.
참가자들은 회의를 요약할 때 몇 가지 다른 전략을 사용한다고 보고했다: 1) 3명 참석자에게 질문 2) 3명 녹취록 사용 3) 5명 녹화본 시청 4) 1명 발표 슬라이드를 검토 5) 2명 채팅을 검토한다고 답했다. 각 참가자가 자신의 필요와 시간적 여유에 따라 여러 가지 요약 전략을 제시했기 때문에 이 수치는 상호 배타적이지 않는다. 표 3은 전체 참가자의 총회의 습관을 요약한 것이다.
| Construct | Number of partici- pants |
Construct | Number of partici- pants |
| Takes notes | 7 | Should take more notes | 2 |
| Keyword notes | 1 | Notes focus on ToDos | 4 |
| Digital notes | 7 | Recordings too long | 2 |
| Physical notes | 2 | Transcripts too long | 1 |
| Notes in chat | 2 | Notes help plan next meeting | 3 |
| Notes in Gdoc | 2 | Recaps with collaborator | 3 |
| Records meetings | 4 | Recaps with transcript | 3 |
| Shares notes | 6 | Recaps with recordings | 5 |
| Shares tasks | 2 | Recaps with slides | 1 |
| Shares slides | 0 | Recaps with chat | 2 |
| Cleanup before share | 1 | ASR issues | 1 |
| Collaborative notes | 4 | Task tracking | 4 |
| Agenda driven meeting Ask to record | 1 1 |
Recap at end of meeting | 1 |
Table 3. Overview of meeting recap habits
5.2 Highlights view
5.2.1 General benefits and issues.
Action items and reminders. Four participants pointed out that suggested summaries served as reminders of what happened in the meeting. Participants indicated using the summaries to decide their action items for the next week’s meeting if it was a recurring one. They also said it helps them plan out their action items for the upcoming week if they had many action items, and prioritize them. Some participants already had a good understanding of what they needed to work on, but still found the summaries helpful as reminders to go back to when unsure. P05 said
실행 항목 및 리마인더. 4명의 참가자는 제안된 요약이 회의에서 일어난 일을 상기시키는 역할을 한다고 지적했다. 참가자들은 반복되는 회의인 경우 다음 주 회의의 실행 항목을 결정할 때 요약을 사용한다고 말했다. 또한 실행 항목이 많은 경우 다음 주 실행 항목을 계획하고 우선순위를 정하는 데 도움이 된다고 말했다. 일부 참가자는 이미 작업해야 할 내용을 잘 이해하고 있지만, 확실하지 않을 때 다시 돌아볼 수 있는 알림으로 요약이 도움이 된다고 했다. P05는 다음과 같이 말했다.
It is helpful to remember. They are accurate. Jogging my memory about the content of the meeting. The task is helpful. It reminds me that I can go look at the email about the meeting to see something I missed.
기억해두면 도움이 된다. 정확한다. 회의 내용에 대한 기억을 되살리는 데 도움이 된다. 이 작업이 도움이 된다. 회의에 관한 이메일을 보고 놓친 내용을 확인할 수 있다는 사실을 상기시켜 준다.
e.g., in status update meeting, each participant discusses their own status sequentially and the status of one participant is not always relevant to others. To easily see discussions of relevant people, P02 also suggested to group the summaries by people so that they can pick the people relevant to them and see their discussions. Further, participants indicated that tasks assigned by their manager were high priority action items that they needed to address urgently, and termed it as “main task” (P03)–other deliverables could be addressed later.
예를 들어, 상태 업데이트 회의에서는 각 참가자가 자신의 상태를 순차적으로 논의하는데, 한 참가자의 상태가 항상 다른 참가자와 관련이 있는 것은 아니다. P02는 관련자의 토론 내용을 쉽게 볼 수 있도록 요약 내용을 사람별로 그룹화하여 자신과 관련된 사람을 골라 토론 내용을 볼 수 있도록 하자는 제안도 했다. 또한 참가자들은 관리자가 지정한 작업은 시급히 해결해야 하는 우선순위가 높은 실행 항목이라고 답했으며, 이를 '주요 작업'(P03)이라고 명명하고 다른 결과물은 나중에 다룰 수 있다고 답했다.
P03 reported
It’s not that good because the AI tells you to do two things – one tiny task. A detail. Like, this detail is not correct, you have to fix after the meeting. It is not the main task. If these kind of tasks are extracted, there will be plenty of to-do list and I might miss the important ones.
AI가 작은 작업 하나에 두 가지를 하라고 지시하기 때문에 그다지 좋지 않는다. 세부 사항. 예를 들어, 이 세부 사항은 정확하지 않으니 회의 후에 수정해야 한다. 그것은 주요 작업이 아니다. 이런 종류의 작업을 추출하면 할 일 목록이 너무 많아져서 중요한 작업을 놓칠 수 있다.
On finding less relevant summaries at the top, four participants also expressed the need for reordering them based on how much the feedback is useful for them (P02) for their workflow. They requested having the most relevant notes & action items right at the top so that they can get a quick overview of the most relevant items when in a hurry.
관련성이 낮은 요약을 상단에 배치하는 것에 대해 4명의 참가자는 피드백이 워크플로우에 얼마나 도움이 되는지에 따라 요약을 다시 정렬할 필요가 있다고 말했다(P02). 이들은 가장 관련성이 높은 노트와 작업 항목을 상단에 배치해 급할 때 가장 관련성이 높은 항목을 빠르게 살펴볼 수 있도록 해달라고 요청했다.
Process oriented discussions around summaries. Two participants indicated that the highlights experience is that discussion process is not well captured. This is because this experience focuses on highlighting key moments (high precision, low recall), and does not have an affordance for including discussion that lead up to that moment. For example, P04 mentioned not seeing a discussion around a paper submission.
요약을 중심으로 한 프로세스 중심 토론. 두 명의 참가자는 하이라이트 경험에서 토론 과정이 잘 포착되지 않는다는 점을 지적했다. 이는 하이라이트 경험이 핵심적인 순간을 강조하는 데 초점을 맞추다 보니(높은 정확도, 낮은 회상률) 그 순간에 이르는 토론 과정을 포함할 수 있는 어포던스가 없기 때문이다. 예를 들어, P04는 논문 제출에 대한 토론을 보지 못했다고 언급했다.
We had a lot of discussion about what needed to be done. [...] If I were taking notes, I would have written down something to that effect. [...] Ultimately, we decided to work with the smaller dataset. No notes about any of that discussion. [...] It would have been nice to see notes around that.
우리는 무엇을 해야 할지에 대해 많은 토론을 했다. [...] 제가 메모를 했다면 그런 취지의 내용을 적었을 것이다. [...] 결국 우리는 더 작은 데이터 집합으로 작업하기로 결정했다. 그 논의에 대한 메모는 없다. [...] 그 부분에 대한 메모가 있었다면 좋았을 것이다.
Context of summaries. Two participants indicated the need for more context to understand the summary. This was most prominent when the system generated summaries for a recorded presentation, and the context is a combination of utterances, as well as visual information on the slides. Current models only used transcripts to generate summaries making it difficult to summarize discussions that referred to presentation visuals.P04 noted
요약의 맥락. 두 명의 참가자가 요약을 이해하기 위해 더 많은 컨텍스트가 필요하다고 말했다. 이는 시스템이 녹화된 프레젠테이션에 대한 요약을 생성할 때 가장 두드러졌는데, 여기서 컨텍스트는 슬라이드의 시각적 정보뿐만 아니라 발언의 조합을 의미한다. 현재 모델은 대본만 사용하여 요약을 생성하기 때문에 프레젠테이션 시각 자료를 참조하는 토론을 요약하기 어려웠다.
If there was a way to link to the meeting for each of these notes I could watch. I can’t scroll back in the context, so it would be great if I had the whole transcript in the context and link to the video. I may want some more detail. If I can jump to the transcript or video, I can get that detail.
각 노트에 대해 회의에 연결할 수 있는 링크가 있으면 볼 수 있을 것 같다. 컨텍스트에서 뒤로 스크롤할 수 없으므로 컨텍스트에 전체 녹취록과 동영상 링크가 있으면 좋을 것 같다. 좀 더 자세한 내용이 필요할 수도 있다. 녹취록이나 동영상으로 이동할 수 있다면 그 세부 정보를 얻을 수 있을 것이다.
To get more context for ambiguous summaries, two participants explored the “show context” feature of the UX. However, three other participants still requested a link to the original video or the full transcript to get more context. They mentioned that the limited context did not help them understand completely and it would be helpful to look at the original discussion for clarity. P01 notes
I’m not sure what it is referring to and what it means in the context we were talking. [...] (Participant expands context) Oh! I remember what happened. A teams bug and the team couldn’t see the slide deck. [...] So maybe 1st part got confused with 2nd part. Even for a human it looks strange.
그게 무슨 뜻인지, 우리가 이야기하던 맥락에서 무슨 의미인지 잘 모르겠어요. [...] (참가자가 문맥을 확장하며) 아! 무슨 일이 있었는지 기억나요. 팀 버그가 발생해서 슬라이드 데크를 볼 수 없었죠. [...] 그래서 아마 1부가 2부와 혼동된 것 같아요. 사람한테도 이상해 보이죠.
Additionally, while examining the context of an action that mentioned someone’s name P04
wanted to know why the name was mentioned:
또한 누군가의 이름이 언급된 작업의 컨텍스트를 검토하는 동안 P04 는 그 이름이 언급된 이유를 알고 싶었다:
I don’t see anything in the context about sending out spreadsheets! I see where the “<name>” came from. We referred to his project and named the survey after their name. That does help in understanding how the name got in there. [...] This is really cool. I love that I can see the context of where it was drawn from.
스프레드시트 전송에 대한 문맥이 전혀 보이지 않는다! "<이름>"이 어디에서 왔는지 알겠다. 우리는 그의 프로젝트를 참조하여 그 프로젝트의 이름을 따서 설문조사 이름을 지었다. 그 이름이 어떻게 들어가게 되었는지 이해하는 데 도움이 된다. [...] 정말 멋지네요. 어디에서 유래했는지 맥락을 볼 수 있다는 점이 마음에 들어요.
Pronoun issues. Four participants indicated that the model generated summaries with their names associated with the wrong pronoun. Participants had varying feeling towards such errors, ranging from attributing it as a minor point (P01) to noticing and point them out, or even feeling uncomfortable about it. This was more frequent with non-Western names, in which case participants felt bad that the model behavior was less inclusive.
대명사 문제. 4명의 참가자가 모델이 자신의 이름에 잘못된 대명사가 포함된 요약을 생성했다고 말했다. 참가자들은 이러한 오류에 대해 사소한 점으로 여기거나(P01), 이를 알아차리고 지적하거나 심지어 불편함을 느끼는 등 다양한 감정을 보였다. 이러한 오류는 서양식 이름이 아닌 경우 더 자주 발생했으며, 이 경우 참가자들은 모델 행동이 덜 포용적이라고 느꼈다.
P06 reflected on the value of the summaries as well as the pronoun issues they saw
Even just looking at the headers, I remember much more about the meeting at a glance. The sentences have errors and the pronouns are wrong
P06은 요약의 가치와 대명사 문제에 대해 반성했다.
헤더만 봐도 회의 내용을 한눈에 파악할 수 있다. 문장에 오류가 있고 대명사가 틀린 경우
5.2.2 Add, edit, delete.
Adding and editing notes holds consistent meaning. All participants agreed that the intention behind adding and editing notes & tasks was consistent (high alignment) in meaning. The notes that participants added were personally important to them (4), a discussion to remember (6), capture general topic/hierarchy (4), or to add details to another note (5). P03 explained while adding a note from memory
노트 추가와 편집은 일관된 의미를 지닌다. 모든 참가자들은 노트와 작업을 추가하고 편집하는 의도가 일관된(높은 정렬성) 의미를 지닌다는 데 동의했다. 참가자들이 추가한 노트는 개인적으로 중요한 내용(4), 기억하기 위한 토론(6), 일반적인 주제/계층 구조 파악(4), 다른 노트에 세부 사항을 추가하기 위한 것(5)이었다. 기억에서 노트를 추가하면서 설명하는 P03
For the notes, I added them according to the timeline in my memory. In the beginning of the meeting, we discussed the result/trend.
P03 also reflected on adding notes that are important to them
I remember these because they are important parts I needed to do. [...] I’m writing down the mistakes I made, the things I need to correct, and the main task.
While adding a missing note P04 remembered of an task but was unsure if it was worth adding
As I’m writing, I think there could be a task there. It’s our path forward, but I’m not sure it needs to be a task.
Regarding editing notes, two participants raised concerns about the AI’s ability to learn from their edits because they used external knowledge to make the edits. Five edited to add relevant context , three fixed grammar issues, one fixed a pronoun issue and two included external information. Six participants were comfortable adding or editing summaries even if they were unsure or did not clearly remember the meeting details. For the likelihood to edit (quantity), two participants indicated that they would be more likely to edit if the summaries were collaborative, two were more likely to edit if the AI would learn from their edits (2) or if the summaries were of decent quality. Four participants also referenced non-audio meeting content such as presentations when making edits.
편집 노트와 관련하여 두 명의 참가자가 외부 지식을 사용하여 편집을 했기 때문에 AI의 학습 능력에 대한 우려를 제기했다. 5명은 관련 문맥을 추가하기 위해, 3명은 문법 문제를 수정하기 위해, 1명은 대명사 문제를 수정하기 위해, 2명은 외부 정보를 포함하기 위해 편집했다. 6명의 참가자는 회의 내용을 잘 모르거나 명확하게 기억하지 못하는 경우에도 요약을 추가하거나 편집하는 데 익숙했다. 편집 가능성(양)에 대해서는 2명의 참가자는 요약이 공동 작업인 경우, 2명은 AI가 자신의 편집 내용을 학습할 경우, 2명은 요약의 품질이 괜찮을 경우 편집할 가능성이 더 높다고 답했다. 4명의 참가자는 프레젠테이션과 같은 오디오가 아닌 회의 콘텐츠도 편집할 때 참고한다고 답했다.
Three participants made minor grammar edits like inserting verbs (P01) into the summaries, or major edits like rephrasing the note or task to make it more actionable (P03). Four participants made edits that changed the order of summaries without changing the content, like moving less relevant notes to the end (P01) to help them review the summaries better. Participants made considerable use of the context when editing notes, added external context like “<show on screen>” (P01) to refer to non-audio content and indicating that the likelihood of editing notes depends on the quality. e.g., P04 stated that they would edit the notes if they satisfied a quality threshold
3명의 참가자는 요약에 동사를 삽입하는 등 사소한 문법 수정(P01)을 하거나, 노트나 작업의 문구를 바꾸어 실행력을 높이는 등 큰 수정(P03)을 했다. 4명의 참가자는 요약을 더 잘 검토할 수 있도록 관련성이 낮은 노트를 맨 뒤로 옮기는 등, 내용에는 변화가 없이 요약 순서를 변경하는 편집을 했다(P01). 참가자들은 노트를 편집할 때 "<화면에 표시>"(P01)와 같은 외부 문맥을 추가하여 오디오가 아닌 콘텐츠를 참조하고, 품질에 따라 노트 편집 가능성이 달라진다는 점을 표시했다(예: P04는 품질 임계값을 충족하면 노트를 편집할 것이라고 말했다).
It’s easier to fix or clarify these mistakes than to start from scratch. If it takes less time for me to fix and correct stuff, then I’m going to do it. If its so bad that it takes more time, I’ll probably stop using it.
처음부터 다시 시작하는 것보다 이러한 실수를 수정하거나 명확히 하는 것이 더 쉽다. 문제를 해결하고 수정하는 데 시간이 덜 걸린다면 그렇게 할 것이다. 너무 심해서 시간이 더 걸린다면 사용을 중단할 것이다.
Deleting has inconsistent meaning. Deleting notes and tasks was more complicated. Two participants reported that they might delete a task when it is done, three reported they might delete a task if it is redundant, and two others reported they might delete the task if it is inaccurate. Two said they would not delete any notes or tasks without a very high level of confidence. Five participants generally found it straightforward to edit notes or tasks but only one participant deleted a task. One possible explanation for this is that deleting makes the summaries go away, so participants are more wary to delete, than adding or editing, where the content is still preserved. e.g., P03 reflected that completed, wrong or redundant action could be misleading.
삭제는 일관성 없는 의미를 가진다. 노트와 작업 삭제는 더 복잡했다. 2명의 참가자는 작업이 완료되면 삭제할 수 있다고 답했고, 3명은 작업이 중복되면 삭제할 수 있다고 답했으며, 2명은 작업이 부정확하면 삭제할 수 있다고 답했다. 2명은 매우 높은 수준의 확신이 없으면 노트나 작업을 삭제하지 않는다고 답했다. 5명의 참가자는 대체로 노트나 작업을 수정하는 것이 간단하다고 답했지만, 단 한 명의 참가자만이 작업을 삭제했다고 답했다. 이에 대한 한 가지 가능한 설명은 삭제하면 요약이 사라지기 때문에 참가자들이 콘텐츠가 그대로 보존되는 추가나 수정보다 삭제에 더 주의를 기울이기 때문일 수 있다. 예를 들어, P03은 완료되었거나 잘못되었거나 중복된 작업이 오해의 소지가 될 수 있다는 점을 반영했다.
If I see an inaccurate note or something I have already done, I will remove it. The wrong actionable could be misleading. I might delete redundant actions. I might insert a new task with the right meeting and delete the task that was summarized wrongly.
부정확한 노트나 제가 이미 수행한 작업을 발견하면 삭제한다. 잘못된 작업이 오해의 소지가 있을 수 있다. 중복된 작업을 삭제할 수 있다. 올바른 회의에 새 작업을 삽입하고 잘못 요약된 작업을 삭제할 수 있다.
P07’s comment brings out the contrast between lack of a consistent meaning for deleting notes and a consistent meaning for adding or editing summaries
P07의 의견은 노트 삭제에 대한 일관된 의미의 부재와 요약 추가 또는 편집에 대한 일관된 의미의 부재 사이의 대조를 잘 드러낸다.
For editing, I won’t wait until I’m super confident.
For delete, I’d be more careful. I might delete something that is important to others. If it learns from my deletions, I’m worried about that.
편집할 때는 자신감이 생길 때까지 기다리지 않는다.
삭제할 때는 좀 더 신중할 것 같다. 다른 사람에게 중요한 내용을 삭제할 수도 있으니까요. 제가 삭제한 내용을 알게 될까 봐 걱정된다.
Recall difficulty when adding or editing notes and tasks. Four participants were able to add a note or a task from memory or using the context in UX but three of these four needed to reference the raw transcript (that they had just copy-pasted into the prototype) in order to think of something they might add.
노트와 작업을 추가하거나 편집할 때의 어려움을 회상했다. 참가자 4명은 기억에서 또는 UX의 컨텍스트를 사용해 노트나 작업을 추가할 수 있었지만, 이 중 3명은 추가할 내용을 떠올리기 위해 (방금 프로토타입에 복사해 붙여넣은) 원시 기록을 참조해야 했다.
5.2.3 Sharing.
Collaborative notes and sharing behavior. Five participants expressed the desire to collaboratively edit the notes and have their changes reflected for others to see. They viewed collaboration on the notes as a way to build consensus around high value tasks, transparency, and also help identify dependencies between tasks. e.g., P03 noted that collaboratively available notes are helpful to transparently identify if their task requires someone else to finish theirs first.
협업 노트와 공유 행동 5명의 참가자가 노트를 공동 편집하고 다른 사람들이 볼 수 있도록 변경 사항을 반영하고 싶다고 말했다. 이들은 노트 협업이 중요한 작업에 대한 공감대를 형성하고, 투명성을 높이고, 작업 간의 종속성을 파악하는 데 도움이 된다고 생각했다. 예를 들어, P03은 협업 노트가 자신의 작업을 다른 사람이 먼저 끝내야 하는지를 투명하게 파악하는 데 도움이 된다고 언급했다.
In meetings that involve more than two people, there are dependencies. e.g., someone else needs to address a task before I can do my task. It would be nice to have this dependency.
두 명 이상이 참여하는 회의에서는 종속성이 존재한다. 예를 들어, 다른 사람이 작업을 처리해야 내가 작업을 수행할 수 있다. 이 종속성이 있으면 좋을 것 같다.
Moreover, participants indicated more willingness to contribute to collaborative notes. They indicated adding and editing them if it was shared and attached to the meeting (P06) and putting more effort into them if it was needed to be shared with [Product team] collaborators (P05). For more accountability, (P06) further suggested to assign people in notes, and notify via email to include people who might miss it otherwise. Another interesting sharing behavior we observed was the tendency to ensure a higher quality of the TODO list if they are going to share (P07), and a higher likelihood to edit the notes if they are part of a shared meeting board
또한, 참가자들은 협업 노트에 더 많은 기여를 하겠다는 의사를 밝혔다. 회의에 공유되어 첨부된 경우 노트를 추가 및 편집하고(P06), [제품 팀] 공동 작업자들과 공유해야 하는 경우 노트에 더 많은 노력을 기울인다고 답했다(P05). 책임감을 높이기 위해 (P06) 노트에 공유할 사람을 지정하고, 그렇지 않을 경우 놓칠 수 있는 사람들을 포함하도록 이메일을 통해 알리는 것도 제안했다. 저희가 관찰한 또 다른 흥미로운 공유 행동은 공유할 경우 TODO 목록의 품질을 높이려는 경향(P07)과 공유 회의 게시판의 일부인 경우 노트를 편집할 가능성이 높다는 점이다.
If it was shared? Yes. If it was shared and attached to the meeting, I would consider it. [...] If it was shared or persistent and I was the meeting owner. I might consider doing it as a resource for other people. ( P05)
공유된 경우? 예. 공유되었고 미팅에 첨부되어 있었다면 고려할 것이다. [...] 공유되었거나 지속적이고 내가 미팅 소유자인 경우. 다른 사람들을 위한 리소스로 사용하는 것을 고려할 수 있다. ( P05)
Further two participants indicated performing a more thorough oversight on the summaries before sharing if they shared it with their superiors
추가로 두 명의 참가자는 상사와 공유할 경우 공유하기 전에 요약본을 더 철저히 검토한다고 답했다.
Good enough but depends on who I’m sharing with. If closest collaborator who was in the meeting... If I wanted to share with <product team> collaborators, I’d put more effort into [editing the notes]. ( P07)
충분하지만 누구와 공유하느냐에 따라 다르다. 회의에 참석했던 가장 가까운 공동 작업자라면... <제품팀> 협업자들과 공유하고 싶다면 [노트 편집]에 더 많은 노력을 기울일 것이다. ( P07)
Sharing modalities. Only one participant noticed the “share” button on the top. Participants had different and strong expectations of sharing the notes with attendees and others. Five wanted to share via meeting chat while three wanted to share via email and three mentioned sharing directly to a task management tool. Four pointed out that they might want to only share some tasks/notes
공유 방식. 상단의 '공유' 버튼을 알아본 참가자는 단 한 명뿐이었다. 참가자들은 참석자 및 다른 사람들과 노트를 공유하는 방식에 대해 서로 다른 강한 기대감을 가지고 있었다. 5명은 미팅 채팅을 통해 공유하고 싶어 했고, 3명은 이메일을 통해, 3명은 작업 관리 도구로 바로 공유하기를 원했다. 4명은 전체 노트가 아닌 일부 작업/노트만 공유하고 싶다고 지적했다. 4명은 워드 문서에 댓글을 다는 것처럼 노트/작업에 직접 댓글을 남기고 싶다고 언급했다.
P05 imagined the shared summary document connected to people’s organizational workflows such as part of the meeting calendars so that it is easy for people to keep track of the summaries. Along similar lines, P01 suggested that shared notes can also act as planning boards for teams, capturing team dependencies, and next tasks for the team.
P05는 공유 요약 문서가 회의 일정의 일부와 같이 사람들의 조직 워크플로우에 연결되어 사람들이 요약을 쉽게 추적할 수 있도록 하는 상상을 했다. 비슷한 맥락에서 P01은 공유 노트가 팀의 계획 보드 역할을 하여 팀의 종속성과 팀의 다음 작업을 파악할 수 있다고 제안했다.
In meetings that involve more than two people, there are dependencies. e.g., someone else needs to address a task before I can do my task. It would be nice to have this dependency
두 명 이상이 참여하는 회의에서는 종속성이 존재한다. 예를 들어, 다른 사람이 작업을 처리해야 내가 작업을 수행할 수 있다. 이 종속성을
5.3 Hierarchical view
Chapters help get a quick meeting overview. One of the major reasons participants appreciated the hierarchical view was its ability to provide quick overview of the meeting. Six participants indicated this overview useful for quick recap. This overview helped a participant who missed the meeting, and wants to understand in five minutes (P04). Topic segmentation and progressive details specifically helped participants easily navigate different parts of the meeting. It helped P06 skip the poster session discussion, and scan the analysis discussion that they cared about. Hierarchical view was more intuitive and looked more like a meeting to participants (P01). P05 was able to explore and understand the hierarchy on their own
챕터는 회의 개요를 빠르게 파악하는 데 도움이 된다. 참가자들이 계층적 보기를 높이 평가한 주요 이유 중 하나는 회의에 대한 빠른 개요를 제공하는 기능 때문이었다. 6명의 참가자가 이 개요가 회의 내용을 빠르게 요약하는 데 유용하다고 말했다. 이 개요는 미팅을 놓친 참가자가 5분 안에 이해하고자 할 때 도움이 되었다(P04). 주제 세분화 및 진행 세부 정보는 참가자가 회의의 여러 부분을 쉽게 탐색하는 데 특히 도움이 되었다. P06은 포스터 세션 토론을 건너뛰고 관심 있는 분석 토론을 스캔하는 데 도움이 되었다. 계층적 보기는 더 직관적이었고 참가자들에게 회의처럼 보였다(P01). P05는 스스로 계층 구조를 탐색하고 이해할 수 있었다.
This looks like a navigation tool which is more valuable. [...] This is two levels. It seems right to me. I see some duplication. You have a main topic, a secondary topic, and then transcript. [...] This seems way more useful to me. Even though there are errors, I can try to make sense of this.
이것은 더 가치있는 탐색 도구처럼 보인다. [...] 이것은 두 가지 수준이다. 제게는 맞는 것 같다. 약간의 중복이 보인다. 주요 주제, 보조 주제, 그리고 대본이 있다. [...] 이것이 저에게는 훨씬 더 유용해 보인다. 오류가 있더라도 이해하려고 노력할 수 있다.
Three participants indicated errors in the chapters, but it did not affect their recall when they looked at the chapter headings and skimmed the chapter contents. This suggests that chapters helped to aid participant’s recall of meeting attendance beyond simply providing a record of what happened in the meeting [disc]. P07 said
세 명의 참가자가 챕터에서 오류를 지적했지만, 챕터 제목을 보고 챕터 내용을 훑어보았을 때 회상에는 영향을 미치지 않았다. 이는 챕터가 단순히 회의에서 일어난 일[디스크]에 대한 기록을 제공하는 것 이상으로 참가자가 회의 참석을 회상하는 데 도움이 되었음을 시사한다. P07은 다음과 같이 말했다.
I like the chapters or headers. Even just looking at the headers, I remember much more about the meeting at a glance. [...] I like this more than [the highlights experience]. It gives more topics of what we discussed. It is more aligned with what we discussed.[...] [The highlights experience] is good for giving a rough understanding – a glance of the TODOs. I’d glance at [the highlights experience] and AI Tasks, then I’d go to the hierarchical and go into the sections we discussed. It is easy for me to focus on the sections I care about.
챕터나 헤더가 마음에 든다. 헤더만 봐도 회의에 대해 한 눈에 훨씬 더 많은 것을 기억할 수 있다. [...] 저는 [하이라이트 경험]보다 이 부분이 더 마음에 든다. 우리가 논의한 주제를 더 많이 알려주거든요. 우리가 논의한 내용과 더 일치한다. [...] [하이라이트 경험]은 대략적인 이해, 즉 할 일을 한 눈에 파악하는 데 좋다. 저는 [하이라이트 경험]과 AI 작업을 한 눈에 살펴본 다음 계층 구조로 이동하여 논의한 섹션으로 이동한다. 이렇게 하면 관심 있는 섹션에 집중하기가 쉬워진다.
We also observed that participant’s recall of the meeting was impacted if the chapters contained more errors. Two participants faced difficulty in getting a quick overview because they observed many titles that did not make grammatical sense or were out of context. P06 noticed these errors as they had a number of poorly worded titles in their meeting recap
또한 챕터에 오류가 많을 경우 참가자의 회의 회상에도 영향을 미치는 것으로 나타났다. 두 명의 참가자는 문법에 맞지 않거나 문맥에 맞지 않는 제목을 많이 발견하여 빠른 개요를 파악하는 데 어려움을 겪었다. P06은 회의 요약에 잘못된 제목이 많았기 때문에 이러한 오류를 발견했다.
We have the accuracy problem. Some are better than the others. <Points out an accurate and important chapter> The idea of these headers is very useful.
정확도 문제가 있다. 어떤 것은 다른 것보다 낫다. <정확하고 중요한 챕터 지적> 이러한 헤더의 아이디어는 매우 유용하다.
People think of meetings in hierarchy. All participant’s manner of exploration of the hierarchical experience suggested a progressive, breadth-first exploration strategy. They would consider a relevant part of the meeting, locate its chapter heading (breadth scan), and explore the chapter by expanding it (depth scan), and looking at the notes that are part of the chapter. If necessary, they would then expand a low level summary to see the raw transcript that was being summarized. [disc - organization and sensemaking - how error and sensemaking interact]
사람들은 회의를 계층적으로 생각한다. 모든 참가자가 계층적 경험을 탐색하는 방식은 점진적이고 폭을 우선시하는 탐색 전략을 제안했다. 참가자들은 회의의 관련 부분을 고려하고, 해당 장의 제목을 찾은 다음(폭 스캔), 해당 장을 확장하고(깊이 스캔), 해당 장의 일부인 메모를 살펴봄으로써 해당 장을 탐색했다. 그런 다음 필요한 경우 낮은 수준의 요약을 확장하여 요약 중인 원시 녹취록을 확인한다. [디스크 - 정리와 감각 만들기 - 오류와 감각 만들기가 상호 작용하는 방식]
P02 and P04’s words exemplify this approach
P02와 P04의 말이 이러한 접근 방식을 잘 보여준다.
This (the hierarchical view) will definitely help me find what’s most helpful to me. It reasonably aggregates by topic. I might just want to see... <selects a section>. With this [chapter], I can look at the context. ( P02)
I’m getting a summary flow of the meeting. [...] We had an attendee who missed a meeting recently. I think they could understand this in 5 minutes. I love the progressive detail. [...] I can understand this really quickly. ( P04)
이(계층적 보기)는 저에게 가장 도움이 되는 것을 찾는 데 확실히 도움이 될 것이다. 주제별로 합리적으로 집계된다. 그냥 보고 싶을 때... <섹션 선택>. 이 [챕터]를 통해 맥락을 살펴볼 수 있다. ( P02)
회의의 요약 흐름을 파악할 수 있다. [...] 최근에 회의에 불참한 참석자가 있었다. 5분이면 이 내용을 이해할 수 있을 것 같아요. 점진적인 디테일이 마음에 들어요. [...] 정말 빨리 이해할 수 있어요. ( P04)
Participants could easily expand chapters to get more context. The navigation provided by the hierarchical view also allowed participants to get more context if they needed to delve deeper into the subject (see Section 3.3). Five participants used this context to expand discussions, understanding who said what, and locating important notes and tasks. It helped P02 understand the explanation in the Q&A section of their meeting better
참가자들은 쉽게 챕터를 확장하여 더 많은 컨텍스트를 얻을 수 있었다. 계층적 보기에서 제공하는 탐색 기능을 통해 참가자들은 주제를 더 깊이 파고들어야 할 경우 더 많은 컨텍스트를 얻을 수 있었다(섹션 3.3 참조). 5명의 참가자가 이 컨텍스트를 사용하여 토론을 확장하고, 누가 무엇을 말했는지 이해하고, 중요한 메모와 작업을 찾았다. P02가 회의의 Q&A 섹션에서 설명을 더 잘 이해하는 데 도움이 되었다.
(Picks a star) It explains the main difference between one project and another. Compared to other things, I’d say this is the main difference. Oh this is important. (clicks the star bullet next to the other item) This is a very good question and answer, I don’t know why this wasn’t flagged at all.
(별표 하나를 골라) 한 프로젝트와 다른 프로젝트의 주요 차이점을 설명한다. 다른 것들과 비교했을 때 이것이 가장 큰 차이점이라고 말하고 싶다. 아, 이게 중요하네요. (다른 항목 옆에 있는 별표 클릭) 아주 좋은 질문과 답변이다. 왜 이 항목에 플래그가 전혀 지정되지 않았는지 모르겠네요.
P04 first glanced at the headings, then drilled down on the second chapter to open the notes, then further into the notes to look at the context of the note
P04는 먼저 제목을 훑어본 다음, 두 번째 챕터로 내려가 노트를 열고, 노트를 더 자세히 들여다보며 노트의 맥락을 살펴본다.
I like that it segments the meeting into topics of discussion. I can hone into what I want. If I’m trying to recall or share, they get a high level view in less than a minute. Then you can drill down. It turns a transcript from a sequential into a random access. I can jump anywhere to get what I want.
미팅을 토론 주제로 세분화할 수 있다는 점이 마음에 든다. 제가 원하는 것에 집중할 수 있다. 제가 기억하거나 공유하려는 내용이 있으면 1분 이내에 높은 수준의 보기를 얻을 수 있다. 그런 다음 드릴다운할 수 있다. 순차적 기록에서 무작위 접근으로 전환할 수 있다. 어디든 이동하여 원하는 것을 얻을 수 있다.
Easy to locate important notes and tasks in chapters. Most participants did not face difficulty in inferring checkboxes and star as “key points” and “action items” respectively. As participants navigated the chapters experience we found that it allowed them to quickly favor navigation to chapters that contained more tasks and assign it to relevant people.
챕터에서 중요한 노트와 작업을 쉽게 찾을 수 있다. 대부분의 참가자들은 체크박스와 별표를 각각 '핵심 사항'과 '작업 항목'으로 유추하는 데 어려움을 겪지 않았다. 참가자들이 챕터 환경을 탐색하면서 더 많은 작업이 포함된 챕터로 빠르게 이동하고 관련 담당자에게 작업을 할당할 수 있다는 사실을 발견했다.
I’m choosing [this chapter] because it has a lot of action items. [Picks an action item] This one I’d actually assign to [other person]. It’s accurate. He said it himself. ( P03)
이 챕터]에는 실천 항목이 많기 때문에 [이 챕터]를 선택한다. [작업 항목 선택] 이것은 실제로 [다른 사람]에게 할당할 것이다. 정확해요. 그가 직접 말했어요. ( P03)
Not just navigation, flagging important notes and tasks in the hierarchical experience allowed participants to quickly lookup the context by reading the prior and following summaries, helping them decide the relevance of the task more easily than the highlights view. P05 opened the section with most tasks and mentioned
탐색뿐 아니라 계층적 환경에서 중요한 노트와 작업에 플래그를 지정하면 참가자들이 이전과 이후의 요약을 읽으며 맥락을 빠르게 찾아볼 수 있어 하이라이트 보기보다 작업의 관련성을 더 쉽게 판단할 수 있었다. P05는 가장 많은 작업이 있는 섹션을 열고 다음과 같이 언급했다.
I’m choosing [this chapter] because it has a lot of action items. <Picks an action item> This one I’d actually assign to [other person]. It’s accurate. He said it himself.
이 챕터]를 선택한 이유는 실천 항목이 많기 때문이다. <작업 항목 선택> 이것은 실제로 [다른 사람]에게 할당할 것이다. 정확해요. 그가 직접 말했어요.
Overall, we found that participants considered highlights view and hierarchical view as compli- mentary. While highlights helped participants quickly look at their tasks, they did not find the notes very useful due to their limited coverage. On the other hand, participants preferred the hierarchical experience for its ability to quickly provide a meeting timeline like experience (revisit). P02 said
전반적으로 참가자들은 하이라이트 보기와 계층적 보기를 불편하다고 생각하는 것으로 나타났다. 하이라이트 보기는 참가자들이 업무를 빠르게 살펴보는 데 도움이 되었지만, 노트의 범위가 제한되어 있어 그다지 유용하지 않다고 생각했다. 반면, 참가자들은 경험(재방문)과 같은 회의 타임라인을 빠르게 제공할 수 있다는 점에서 계층적 환경을 선호했다. P02는 다음과 같이 말했다.
If I want to look at tasks, I would prefer the [highlights view]. It’s easy to look at it and add more tasks. [...] If I want to read the summary of the meeting or identify some part of the notes to share, I would look at the hierarchical version.
작업을 보고 싶을 때는 [하이라이트 보기]를 선호한다. 보기가 편하고 작업을 더 추가하기 쉽다. [...] 회의 요약을 읽거나 공유할 노트의 일부를 확인하고 싶을 때는 계층 보기를 사용한다.
6. DISCUSSION
Our user studies indicate that all participants find both recap experiences useful for different reasons. Most of our participants found complimentary value between experiences for different use cases. For example, it was a common theme that the highlights view was most useful for recap for meetings one attended, and hierarchical view was most useful for meetings one missed entirely. This confirms prior findings of varying recap needs [79] and also aligns with Nathan et al.’s [56] finding that annotations regardless of whether it was their own or others helped recall.
사용자 연구에 따르면 모든 참가자는 서로 다른 이유로 두 가지 요약 경험이 모두 유용하다고 생각했다. 대부분의 참가자들은 서로 다른 사용 사례에서 두 경험 간의 상호 보완적인 가치를 발견했다. 예를 들어, 참석했던 미팅을 요약할 때는 하이라이트 보기가 가장 유용하고, 완전히 놓친 미팅을 요약할 때는 계층적 보기가 가장 유용하다는 것이 공통된 주제였다. 이는 다양한 요약 니즈에 대한 이전 연구 결과[79]를 확인시켜 주며, 본인 또는 타인의 주석이 회상에 도움이 된다는 Nathan 등의 연구 결과[56]와도 일치한다.
6.1 DR1: Personal note-taking / Highlights view
When describing our design rationale for the highlights view, we argued that a meeting recap should be as short as possible and focus on outcomes to serve the users’ needs efficiently – mimicking personal note-taking. Participants generally agreed that they preferred this approach for recap when they were reviewing a meeting that they had attended–specifically noting the value of being able to see tasks at a quick glance.
하이라이트 보기의 설계 근거를 설명할 때, 우리는 회의 요약이 가능한 한 짧고 결과에 집중해야 사용자의 요구를 효율적으로 충족시킬 수 있으며, 이는 개인 노트 필기와 유사하다고 주장했다. 참가자들은 대체로 자신이 참석했던 회의를 검토할 때 이 요약 방식을 선호한다는 데 동의했으며, 특히 작업을 한 눈에 볼 수 있다는 점에 주목했다.
However, determining relevance was a big issue for ML models when picking and choosing what to represent in a summary. Some participants noted that main points of discussion were not included in the suggested notes while for some participants, the model generated no notes when it couldn’t detect any utterance as important with high enough confidence. Some participants also reflected on their expectation that notes and tasks would be presented in priority order and their desire to re-order the notes that we suggested to them. To show the most relevant summaries when aiming for the most important items, models need to personalize to individual user needs to provide a good recap experience.
그러나 요약에 표시할 내용을 고르고 선택할 때 관련성을 판단하는 것은 ML 모델에 있어 큰 문제였다. 일부 참가자는 토론의 주요 요점이 제안된 노트에 포함되지 않는다고 지적했고, 일부 참가자의 경우 모델이 충분히 높은 신뢰도로 중요한 발언을 감지하지 못하면 노트가 생성되지 않는 경우도 있었다. 또한 일부 참가자들은 노트와 작업이 우선순위에 따라 표시되기를 기대했고, 제안된 노트의 순서를 바꾸고 싶다는 의견을 제시하기도 했다. 가장 중요한 항목에 가장 관련성이 높은 요약을 표시하려면 모델은 개별 사용자의 요구에 맞게 개인화되어 좋은 요약 경험을 제공해야 한다.
The interactions we provided for users show promise in gathering high quality training data to further align [14] the models with users expectations. Users found editing notes and tasks straightforward–especially when using the “show context” option to see the raw dialog, and users reported that the meaning our models should learn from their work was consistent (high alignment). However, users struggled to add notes that were missing without doing the difficult work of going back to the transcript to remember what happened in the meeting (situatedness). This suggests that they would be less likely to add notes and tasks that our models missed, thus their interactions would be less informative for improving the recall of key point and action item detection. The concerns raised about deletion of notes and tasks suggest that more work is needed in order to find a consistent way for users to express when an item should not have been included in the highlights.
사용자에게 제공한 상호작용은 고품질의 학습 데이터를 수집하여 모델을 사용자의 기대에 더 잘 맞출 수 있는 가능성을 보여주었다[14]. 사용자들은 특히 '컨텍스트 표시' 옵션을 사용하여 원시 대화 상자를 볼 때 노트와 작업을 편집하는 것이 간단하다는 것을 알았고, 사용자들은 모델이 작업을 통해 학습해야 하는 의미가 일관적이라고 보고했다(높은 정렬). 그러나 사용자들은 회의에서 무슨 일이 있었는지 기억하기 위해 녹취록으로 되돌아가는 어려운 작업을 하지 않고는 누락된 메모를 추가하는 데 어려움을 겪었다(위치 지정성). 이는 사용자가 모델이 놓친 메모와 작업을 추가할 가능성이 적다는 것을 의미하며, 따라서 상호작용이 핵심 사항 및 실행 항목 감지의 기억력을 향상시키는 데 도움이 되지 못한다는 것을 의미한다. 메모와 작업 삭제에 대한 우려는 사용자가 하이라이트에 포함되지 않았어야 하는 항목을 일관성있게 표현할 수 있는 방법을 찾기 위해 더 많은 작업이 필요하다는 것을 시사한다.
6.2 DR2: Meeting minutes / Hierarchical view
When describing our design rationale for the hierarchical view, we argued that a meeting recap should summarize the entire meeting including discussions and outcomes within a hierarchical structure (drawing from Zacks et al.[85] and the practice of generating meeting minutes [13]) to enable broad use cases and contextual navigation. Participants were generally positive about the hierarchical view and some even specifically said that the experience reflected how they imagined a meeting–reflecting the insights from Zacks et al.[85].
계층적 보기에 대한 설계 근거를 설명할 때, 우리는 광범위한 사용 사례와 맥락적 탐색을 가능하게 하기 위해 회의 요약이 계층적 구조 내에서 토론과 결과를 포함한 전체 회의를 요약해야 한다고 주장했다(Zacks 등[85]과 회의록 생성 관행[13]에서 도출). 참가자들은 계층적 보기에 대해 대체로 긍정적이었으며, 일부는 이 경험이 자신이 상상하는 회의의 모습을 반영한다고 구체적으로 말하기도 했다[85].
Participants found the process of drilling down into the meeting summary to be intuitive. Despite the limitations in the model’s ability to generate accurate titles for each section that made sense to participants, they found them to be close enough to support their information seeking needs– allowing them to identify and expand low level summaries of the meeting that were relevant to their recap needs. It was apparent that the complete summary also helped participants put the “key points” and “action items” that the system flagged into the context of the discussion from which they arose.
참가자들은 회의 요약을 드릴다운하는 과정이 직관적이라고 평가했다. 참가자들이 이해할 수 있는 각 섹션의 정확한 제목을 생성하는 모델 기능의 한계에도 불구하고, 참가자들은 이 모델이 자신의 정보 검색 니즈에 충분히 근접하여 요약 니즈와 관련된 회의의 낮은 수준의 요약을 식별하고 확장할 수 있다는 것을 발견했다. 또한 전체 요약은 참가자들이 시스템이 표시한 '핵심 사항'과 '실행 항목'을 토론의 맥락에서 파악하는 데 도움이 되는 것으로 나타났다.
The interactions we provided for users in this situation also show promise for gathering useful training data. Users found editing of summaries to be intuitive. They were able better understand the tasks we summarized for them in the context of nearby low-level summaries. In this case, adding a note was not relevant, but selecting or unselecting highlights from the meeting mostly intuitive. Again participants reflected on being more likely to do so if their work would benefit others, but many also reflected that they would correct the which summaries were highlighted if they felt that the AI behind the highlights would learn quickly from their corrections.
이러한 상황에서 사용자에게 제공한 상호작용은 유용한 학습 데이터를 수집할 수 있는 가능성을 보여주었다. 사용자들은 요약 편집이 직관적이라는 것을 알게 되었다. 사용자들은 근처의 하위 수준 요약의 맥락에서 요약된 작업을 더 잘 이해할 수 있었다. 이 경우 메모를 추가하는 것은 관련이 없었지만 회의에서 하이라이트를 선택하거나 선택 취소하는 것은 대부분 직관적이었다. 이번에도 참가자들은 자신의 작업이 다른 사람들에게 도움이 된다면 그렇게 할 가능성이 높다고 답했지만, 하이라이트 뒤에 있는 AI가 자신의 수정을 통해 빠르게 학습할 수 있다면 어떤 요약이 강조 표시되었는지 수정하겠다는 의견도 많았다.
6.3. Design implications
Our evaluation points to several important considerations for better meeting recap systems and designing scalable evaluations.
우리의 평가는 더 나은 미팅 요약 시스템과 확장 가능한 평가를 설계하기 위한 몇 가지 중요한 고려 사항을 지적한다.
Dialogue summarization improves recap sense-making. Dialogue summarization enables a level of automation in recap support that was previously impossible but yet called for [79] – generation of contextual summaries that resemble human note-taking. Prior meeting recap ap- proaches that relied on raw transcripts were difficult for meeting attendees to use due to information overload. In contrast, all our participants found the generated summaries to be understandable, despite imperfections and found them helpful when recalling parts of their meeting. This allowed our participants to focus on higher order needs with the recap, such as how they would use the recap to plan their upcoming tasks, or the possible ways in which they might share the summary to collaborate. Such observations were limited in prior studies where the cognitively demanding task of sensemaking from transcripts prevented participants from thinking how the recap could apply to their work [35, 79].
대화 요약은 요약의 이해도를 향상시킨다. 대화 요약은 이전에는 불가능했던 요약 지원의 자동화 수준, 즉 사람이 메모를 작성하는 것과 유사한 문맥 요약의 생성을 가능하게 한다[79]. 원시 녹취록에 의존하던 이전의 회의 요약 지원 방식은 정보 과부하로 인해 회의 참석자가 사용하기 어려웠다. 반면, 모든 참가자는 불완전함에도 불구하고 생성된 요약본이 이해하기 쉬웠고 회의 내용을 기억할 때 도움이 되었다고 평가했다. 덕분에 참가자들은 요약본을 사용하여 다음 작업을 계획하는 방법이나 요약본을 공유하여 협업할 수 있는 방법과 같은 고차원적인 요구사항에 집중할 수 있었다. 이러한 관찰은 이전 연구에서 제한적으로 관찰되었는데, 참가자들은 녹취록에서 인지적으로 까다로운 감각화 작업으로 인해 요약이 자신의 업무에 어떻게 적용될 수 있는지 생각하지 못했다[35, 79].
A hybrid approach. One of our key insights from comparing the highlights and hierarchical experiences was that they were both valuable in different ways complimenting each other. As mentioned earlier, many participants reflected that the quick access to tasks was valuable to them when recapping a meeting they attended while seeing the whole meeting summary was useful for meeting that they did not attend. Highlights requires models to understand personal relevance to generate the most important summaries, while hierarchical generates minutes from the full meeting, so it serves as a common document for all attendees. Nathan et al [56] and Whittaker et al [79] both hypothesized that a personal summary could act as a personal todo list, while a group summary could be useful for collaborations and public contractual obligations. This exploratory finding also aligns with cognitive fit theory [69] that the most useful representation of the summary will be the one that matches the structure of the task that the participants hope to achieve from the recap.
하이브리드 접근 방식. 하이라이트와 계층적 경험을 비교하면서 얻은 주요 인사이트 중 하나는 두 가지가 서로를 보완하는 다양한 방식으로 가치가 있다는 것이었다. 앞서 언급했듯이, 많은 참가자들은 자신이 참석한 미팅을 요약할 때 작업에 빠르게 액세스할 수 있다는 점이 유용하다고 답한 반면, 전체 미팅 요약을 볼 수 있다는 점은 참석하지 않은 미팅에 유용하다고 답했다. 하이라이트는 가장 중요한 요약을 생성하기 위해 개인별 관련성을 이해하는 모델을 필요로 하는 반면, 계층 구조는 전체 회의록을 생성하므로 모든 참석자에게 공통 문서 역할을 한다. Nathan 외[56]와 Whittaker 외[79]는 개인 요약은 개인 할 일 목록으로, 그룹 요약은 협업 및 공공 계약 의무에 유용할 수 있다는 가설을 세웠다. 이러한 탐색적 발견은 요약의 가장 유용한 표현은 참가자가 요약을 통해 달성하고자 하는 작업의 구조와 일치하는 것이라는 인지적 적합성 이론[69]과도 일치한다.
Access to source dialog and audio/video supports recall. All participants used the ability to expand the “context” of a summary into the original dialog in order to make sense of a suggested note, suggested task, or a low-level summary (see Figure 1 for the context affordance). Many participant also requested deep links to video recordings to quickly review the actual discussion. These observations agree with prior findings on audio indexes explored by Geyer et al and Moran et al [24, 53] that enabled participants to make better sense of their notes when they were associated with timestamped audio recordings. Access to original meeting artefacts is also helpful to enable participants to correct any issues with the model generated summaries. Whittaker et al [78] showed that access to verbatim speech in the meeting browser was found to boost participant’s confidence in their own recall, as well as helped them correct any mistakes in their manual notes.
소스 대화창과 오디오/비디오에 대한 액세스는 리콜을 지원한다. 모든 참가자들은 제안된 노트, 제안된 작업 또는 낮은 수준의 요약을 이해하기 위해 요약의 '맥락'을 원본 대화창으로 확장하는 기능을 사용했다(맥락 어포던스는 그림 1 참조). 또한 많은 참가자들이 실제 토론 내용을 빠르게 검토하기 위해 비디오 녹화에 대한 딥 링크를 요청했다. 이러한 관찰 결과는 Geyer 등[24, 53]과 Moran 등[24, 53]이 조사한 오디오 인덱스에 대한 이전 연구 결과와 일치하며, 참가자들은 타임스탬프가 찍힌 오디오 녹음과 연결되었을 때 노트를 더 잘 이해할 수 있었다. 원본 회의 아티팩트에 대한 액세스는 참가자가 모델에서 생성된 요약의 문제를 수정하는 데에도 도움이 된다. Whittaker 등[78]의 연구에 따르면 회의 브라우저에서 축어체 연설에 액세스하면 참가자의 기억력에 대한 자신감이 높아질 뿐만 아니라 수동 노트의 실수를 수정하는 데 도움이 되는 것으로 나타났다.
Non-text artefacts like visual content enhances sense-making. Dialogue summarization does not capture other meeting artifacts like presentation slides, hand gestures, whiteboard illustrations– all of which have been shown to contribute to sense-making [52] in the very early meeting recap browsers explored previously. We saw at least one participant intentionally reference non-speech meeting content in their explorations of our system. Combining dialogue summaries with additional artefacts like slides, attached files can provide additional value that early meeting browsers could not identify because of the distractions produced by using utterances as recap units [72].
시각적 콘텐츠와 같은 비텍스트 인공물은 감각을 향상시킨다. 대화 요약은 프레젠테이션 슬라이드, 손동작, 화이트보드 그림과 같은 다른 회의 아티팩트(앞서 살펴본 초기의 회의 요약 브라우저에서 감각 형성에 기여하는 것으로 나타났다[52])는 캡처하지 않는다. 적어도 한 명의 참가자가 시스템을 탐색하는 과정에서 의도적으로 음성 이외의 회의 콘텐츠를 참조하는 것을 보았다. 대화 요약과 슬라이드, 첨부 파일과 같은 추가 아티팩트를 결합하면 발언을 요약 단위로 사용함으로써 발생하는 산만함 때문에 초기 미팅 브라우저에서 식별할 수 없었던 추가적인 가치를 제공할 수 있다[72].
Meeting recap as a natural artifact for collaboration. Prior meeting recap systems [7, 20] focused on effective individual recap, but their collaboration aspect was under-explored. This is because hybrid interfaces comprising text, audio and video elements or summaries represented as a collection of important utterances from the meeting do not lend themselves well to sense- making and collaboration. As an exception, Geyer et al [24] designed a customized system to associate domain specific artifact with indexes in meetings for later collaboration. However, their evaluations highlight the difficulty of using the recap system’s artifacts outside of the system due to recap being part of a highly customized interface.
협업을 위한 자연스러운 결과물로서의 회의 요약. 이전의 회의 요약 시스템[7, 20]은 효과적인 개별 요약에 중점을 두었으나 협업 측면은 충분히 고려되지 않았다. 텍스트, 오디오, 비디오 요소로 구성된 하이브리드 인터페이스나 회의에서 나온 중요한 발언을 모아 요약하는 방식은 의미 도출과 협업에 적합하지 않기 때문이다. 예외적으로 Geyer 등[24]은 추후 협업을 위해 회의에서 도메인별 아티팩트를 인덱스와 연결할 수 있는 맞춤형 시스템을 설계했다. 그러나 이들의 평가에 따르면 요약은 고도로 맞춤화된 인터페이스의 일부이기 때문에 요약 시스템의 아티팩트를 시스템 외부에서 사용하는 것이 어렵다는 점이 강조되었다.
For the first time, through our system, we were able to generate recap in the form of a document, that resembled how a person would take notes, and very similar to text documents authored in organizations [58]. Thus, all our participants expressed their desire to engage with meeting content after the meeting took place. Their expressed sharing behaviors has implications for design such as starting a conversation around a specific point raised in the meeting–to get clarifications and extend discussions. Two participants imagined the hierarchical view as a document that could have comments added to it like a Word document or a Google document by highlighting a section of the text. One participant imagined sending parts of the recap to a chat or email thread for a follow-up discussion. We hypothesize such a high interest in asynchronous collaboration with recap due to its familiarity with handwritten notes, and documents that are easily shareable without needing any additional technological affordance.
처음으로 우리 시스템을 통해 사람이 메모하는 방식과 유사하고 조직에서 작성하는 텍스트 문서와 매우 유사한 문서 형태의 요약본을 생성할 수 있었다[58]. 따라서 모든 참가자들은 회의가 끝난 후에도 회의 콘텐츠에 참여하고 싶다는 의사를 표명했다. 이들이 표현한 공유 행동은 회의에서 제기된 특정 요점을 중심으로 대화를 시작하여 설명을 얻고 토론을 확장하는 등 디자인에 시사하는 바가 있다. 두 명의 참가자는 계층 보기를 Word 문서나 Google 문서처럼 텍스트의 섹션을 강조 표시하여 댓글을 추가할 수 있는 문서로 상상했다. 한 참가자는 요약의 일부를 채팅이나 이메일 스레드로 전송하여 후속 토론을 진행하는 것을 상상했다. 요약본에 대한 비동기 협업에 대한 높은 관심은 손으로 쓴 노트와 친숙하고 추가적인 기술적 장치 없이도 쉽게 공유할 수 있는 문서가 있기 때문인 것으로 추정된다.
Using meeting recap as a collaborative document facilitates the use of the meeting in the context of increasing remote work and cross-timezone collaboration. With such functionality, it could be possible to both miss a meeting and be an active participant in the discussion started by that meeting through consuming the recap and continuing the discussions asynchronously [62].
회의 요약을 협업 문서로 사용하면 원격 근무와 시간대 간 협업이 증가하는 상황에서 회의 활용이 용이해진다. 이러한 기능을 사용하면 회의에 참석하지 않으면서도 회의 요약을 소비하고 비동기적으로 토론을 계속함으로써 해당 회의에서 시작된 토론에 적극적으로 참여할 수 있다[62].
Privacy and transparency implications. Meeting recap supports an inherently collaborative workspace. Transparency imposed by meeting recap can change existing work practices [68], a dimension previously overlooked in recap studies. E.g., while a mis-attributed action item is not bad for individual recap, wrongly attributed action items could impact group dynamics and obligations. Moreover, our participants indicated disappointment at being referred by the wrong pronoun, which when made transparent to the group in a recap can be even more detrimental, especially for culturally sensitive groups [8]. Two of our participants indicated concerns with recording meetings to generate recap. Since meeting recap makes meeting discussions explicit, permanent and easily shareable, it has the potential to change work obligations similar to how algorithmic support to Wikipedia processes changed Wikipedia work practices [27]. Anyone can easily look at the recap document to assess work and recap documents as collaborative artifacts implies that people’s group discussions could be more broadly accessible [41]. Future work should understand how meeting recap technologies can consentfully integrate in work practices.
개인정보 보호 및 투명성에 미치는 영향.회의 요약은 본질적으로 협업적인 업무 공간을 지원한다.회의 요약으로 인한 투명성은 기존 업무 관행[68]을 변화시킬 수 있으며, 이는 이전에는 요약 연구에서 간과되었던 측면이다.예를 들어, 잘못 귀속된 작업 항목은 개인 요약에는 나쁘지 않지만, 잘못 귀속된 작업 항목은 그룹의 역학 관계와 의무에 영향을 미칠 수 있다.또한, 참가자들은 잘못된 대명사로 언급된 것에 대해 실망감을 표시했는데, 이는 요약에서 그룹에 투명하게 공개될 경우 특히 문화적으로 민감한 그룹의 경우 더욱 해로울 수 있다[8].참가자 중 두 명은 요약본을 작성하기 위해 회의를 녹음하는 것에 대해 우려를 표명했다. 회의 요약은 회의 논의를 명시적이고 영구적이며 쉽게 공유할 수 있도록 하기 때문에, 위키백과 프로세스에 대한 알고리즘 지원이 위키백과 업무 관행을 바꾼 것과 유사하게 업무 의무를 변화시킬 수 있는 잠재력을 가지고 있다[27]. 누구나 쉽게 요약 문서를 보고 업무를 평가할 수 있고, 협업 아티팩트로서 요약 문서를 사용할 수 있다는 것은 사람들의 그룹 토론에 더 광범위하게 접근할 수 있음을 의미한다[41]. 향후 연구에서는 회의 요약 기술이 업무 관행에 어떻게 동의하에 통합될 수 있는지 이해해야 한다.
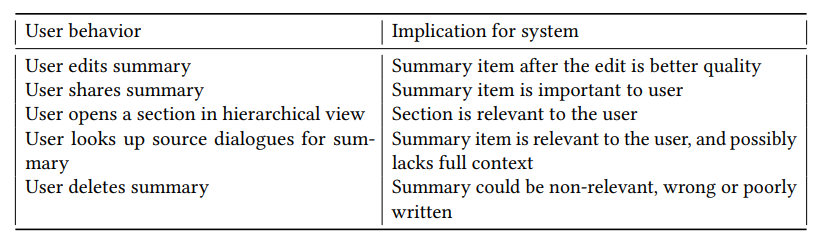
Table 4. User interactions with the UX that can be used to provide feedback signals to the model on summary quality.
표 4. 요약 품질에 대한 피드백 신호를 모델에 제공하는 데 사용할 수 있는 UX와의 사용자 상호 작용.
Designing to learn. The models we used to construct these recap experiences were all trained on crowd-sourced data–data gathered by asking crowd workers to summarize and label “key points”/“action items” from meetings that they did not attend. There will always be a gap between the understanding of someone who attends a meeting and is part of the social context in which the meeting was planned and executed and someone who is merely reading the transcript. Under- standing meetings through transcripts is akin to the problem of grounding and overhearers [65] which suggests that labelers will never perfectly capture what participants understand because conversations utilize implications and grounding. Thus models built on the labelers they produce are rarely well aligned [14] with the intended use [83]. At best, current AI systems trained from a crowd-level understanding of relevance yields generalist models, i.e., they work well on instances of high consensus, but their performance will go down if users disagree on instances [80].
학습을 위한 디자인. 이러한 요약 경험을 구축하는 데 사용한 모델은 모두 크라우드 소싱 데이터(크라우드 워커에게 참석하지 않은 회의의 '핵심 사항'/'실행 항목'을 요약하고 레이블을 지정하도록 요청하여 수집한 데이터)를 기반으로 학습되었다.회의에 참석하여 회의가 계획되고 실행된 사회적 맥락의 일부인 사람과 단순히 속기록을 읽는 사람의 이해 사이에는 항상 차이가 있을 것이다.녹취록을 통한 회의의 이해 부족은 근거와 엿듣는 사람의 문제와 유사하며[65], 대화는 함축과 근거를 활용하기 때문에 라벨러가 참가자가 이해하는 것을 완벽하게 포착할 수 없음을 시사한다.따라서 생성된 라벨러를 기반으로 구축된 모델은 의도된 용도와 잘 일치하는 경우가 드물다[14][83].관련성에 대한 군중 수준의 이해를 바탕으로 학습된 현재의 AI 시스템은 기껏해야 일반론적 모델, 즉 합의가 높은 사례에서는 잘 작동하지만 사용자가 사례에 동의하지 않으면 성능이 저하된다[80].
Systems can re-train and get better from in-context data if the feedback is of high quality [21]. ML models can learn from in-context interactions but the interactions may not always have consistent meaning (alignment). We found this in our interviews with participant’s indicating varying degrees of consistency in meaning for adding, editing, and deleting suggested notes and tasks. All participants agreed that adding notes or tasks had consistent meaning (alignment), i.e, they will add notes/tasks or tasks that is relevant to them and that the AI should learn to produce. Editing notes/tasks also had consistent meaning for them, implying that participants would edit notes to more accurately reflect the discussion and that the AI could learn from their cues to do better as well. Most participants suggested they would be more likely to edit the notes if their edits benefited others or if they were planning to share them out with the group (quantity).
피드백의 품질이 높으면 시스템은 컨텍스트 내 데이터를 통해 재학습하고 더 나은 결과를 얻을 수 있다[21]. ML 모델은 In-context 상호 작용을 통해 학습할 수 있지만 상호 작용이 항상 일관된 의미(정렬)를 갖는 것은 아니다. 우리는 참가자들과의 인터뷰에서 제안된 노트와 작업의 추가, 편집, 삭제에 대한 의미의 일관성이 다양하다는 점을 발견했다.모든 참가자들은 노트나 작업을 추가하는 것이 일관된 의미(정렬)를 갖는다는 데 동의했다. 즉, 자신과 관련된 노트/작업이나 작업을 추가할 것이고 AI가 학습해서 생성해야 한다는 것이다.노트/작업 편집 역시 일관된 의미를 지니고 있었는데, 이는 참가자들이 토론 내용을 보다 정확하게 반영하기 위해 노트를 편집할 것이며, AI도 참가자들의 단서를 통해 더 나은 작업을 학습할 수 있다는 것을 의미했다.대부분의 참가자들은 자신의 편집이 다른 사람들에게 도움이 되거나 그룹과 공유할 계획(수량)이 있는 경우 노트를 편집할 가능성이 더 높다고 답했다.
Deleting notes was more nuanced for participants, as participants expressed various reasons for deleting the notes – not relevant to their task, unclear to make sense, or low relevance. Therefore, when designing an AI to learn from user’s actions it is useful to first elicit the reasons behind user’s actions. Feedback from addition, and edits to the summaries could be directly used to re-train models to improve precision, recall, and the accuracy of summarized dialog. But feedback related to items that should not have been suggested as note/highlights or should not have been called out as tasks should be gathered in a way that makes the user intention less ambiguous. Table 4 summarizes possible user behaviors and their implications for improving the quality of the system from feedback.
노트를 삭제하는 것에 대해서는 참가자들이 업무와 관련이 없다, 이해가 되지 않는다, 관련성이 낮다 등 다양한 이유를 제시해 미묘한 차이를 보였다. 따라서 사용자의 행동으로부터 학습하는 AI를 설계할 때는 먼저 사용자 행동의 이면에 숨어 있는 이유를 파악하는 것이 유용한다. 요약에 대한 추가 및 편집 피드백은 모델을 재학습하여 정확도, 기억력 및 요약된 대화의 정확도를 개선하는 데 직접 사용할 수 있다. 그러나 메모/주요 사항으로 제안되어서는 안 되는 항목이나 작업으로 호출되어서는 안 되는 항목과 관련된 피드백은 사용자 의도를 덜 모호하게 만드는 방식으로 수집해야 한다. 표 4에는 피드백을 통해 시스템 품질을 개선하기 위해 가능한 사용자 행동과 그 함의가 요약되어 있다.
7. CONCLUSION, LIMITATIONS AND FUTURE WORK
With more meetings happening in organizations and an increasing proportion of them turning to hybrid or online, effective meeting recap can provide participants a way to strategize their meeting workload more effectively. We propose design of a meeting recap system with two different experiences that target different but complementary use cases – 1) quick highlights recap, 2) Full meeting minutes segmented into chapters. We perform preliminary evaluation of the experiences with users in a within subjects design. Our findings suggest that participants find value in both highlights, as well as the hierarchical experience. Future work can build on these findings to design and evaluate recaps at a larger scale.
조직에서 더 많은 회의가 개최되고 하이브리드 또는 온라인으로 전환하는 회의의 비율이 증가함에 따라 효과적인 회의 요약은 참가자들이 회의 업무량을 보다 효과적으로 전략화할 수 있는 방법을 제공할 수 있다. 우리는 서로 다르지만 상호 보완적인 사용 사례를 목표로 하는 두 가지 경험, 즉 1) 빠른 하이라이트 요약과 2) 챕터로 세분화된 전체 회의록으로 구성된 회의 요약 시스템의 설계를 제안한다. 우리는 주제 내 디자인에서 사용자와 함께 경험에 대한 예비 평가를 수행했다. 연구 결과에 따르면 참가자들은 하이라이트와 계층적 경험 모두에서 가치를 발견하는 것으로 나타났다. 향후 연구에서는 이러한 결과를 바탕으로 더 큰 규모의 요약본을 설계하고 평가할 수 있다.
We recruited participants from the research organization where we conducted the research to perform preliminary evaluations and many of our meetings were progress update meetings that involved reporting of analyses, and next steps. All our participants had a basic minimum technical background due to employment at the organization which limited our ability to explore how users from diverse backgrounds will use recap. We observed the difficulty in studying in-context usefulness of meeting recap. Our study required participants to record their meetings and share it with the system to generate recap and discuss the same in the interviews. Recording is not a commonly accepted practice in the organization, and many participants were not comfortable either discussing their personal meetings or seeking consent from other meeting participants to record and share their meeting. These concerns are likely to come up in other contexts as well [2]. To get meetings from diverse backgrounds, such as finance, human resources, scientific collaborations, and health future research should carefully think of how to manage the privacy aspect of studying recap [41]. All the participants in our study attended their respective meetings and had fresh context of their meetings. While prior work suggests non-attendees benefit as much as attendees from notes created during meetings [56], understanding the perspectives of attendees weeks after the meeting and non-attendees could uncover additional insights (e.g., need for richer context). This is because, loss of context with time, or no-context when not attending the meeting impacts recall [34]. Our study provides early stage insights into the usefulness of a meeting recap system that generates high quality personal style notes but future research should study recap needs in a longitudinal setup, both qualitatively and quantitatively. We evaluated both are design rationales in the same sequence of highlights then hierarchical. While the sequence can have an effect on the findings, it would be minimal due to the exploratory nature of our study. Future work aiming to draw statistical conclusions should consider randomized sequence for evaluating the representations.
우리는 연구를 수행한 연구 조직에서 참가자를 모집하여 예비 평가를 수행했으며, 대부분의 회의는 분석 보고 및 다음 단계를 포함하는 진행 상황 업데이트 회의였다. 모든 참가자는 해당 조직에 근무하기 때문에 기본적인 최소한의 기술적 배경을 가지고 있었기 때문에 다양한 배경을 가진 사용자가 리캡을 어떻게 사용할지 조사하는 데 한계가 있었다. 우리는 회의 요약의 맥락 내 유용성을 연구하는 데 어려움이 있음을 관찰했다. 우리 연구에서는 참가자들이 회의를 녹화하고 이를 시스템과 공유하여 요약본을 생성하고 인터뷰에서도 동일한 내용을 논의하도록 했다. 녹화는 조직에서 일반적으로 받아들여지는 관행이 아니며, 많은 참가자가 개인 회의에 대해 논의하거나 다른 회의 참가자의 동의를 구하여 회의를 녹음하고 공유하는 것에 대해 불편해했다. 이러한 우려는 다른 상황에서도 발생할 가능성이 높다[2]. 금융, 인사, 과학적 협업, 건강 등 다양한 배경을 가진 사람들이 모이는 회의를 진행하려면 회의 내용을 요약할 때 개인정보 보호 측면을 어떻게 관리할지 신중하게 고려해야 한다[41]. 본 연구에 참여한 모든 참가자는 각자의 회의에 참석했으며 회의에 대한 새로운 맥락을 가지고 있었다. 선행 연구에 따르면 비참석자도 회의 중에 작성된 노트를 통해 참석자만큼이나 많은 이점을 얻을 수 있지만[56], 회의가 끝난 지 몇 주 후 참석자와 비참석자의 관점을 이해하면 추가적인 인사이트(예: 더 풍부한 컨텍스트의 필요성)를 발견할 수 있을 것이다. 시간이 지남에 따라 컨텍스트가 사라지거나 회의에 참석하지 않았을 때 컨텍스트가 없으면 회상력에 영향을 미치기 때문이다[34]. 본 연구는 고품질의 개인 스타일 노트를 생성하는 회의 요약 시스템의 유용성에 대한 초기 단계의 인사이트를 제공하지만, 향후 연구에서는 종단적 설정에서 질적, 양적으로 요약에 대한 니즈를 연구해야 한다. 우리는 두 가지 모두 동일한 하이라이트 순서에 따라 계층적으로 설계한 이유를 평가했다. 순서가 조사 결과에 영향을 미칠 수 있지만, 본 연구의 탐색적 특성으로 인해 그 영향은 미미할 것이다. 통계적 결론을 도출하고자 하는 향후 연구에서는 표현을 평가할 때 무작위 순서를 고려해야 한다.
Meeting recap is a challenging domain where ML models trained through crowdwork are less aligned with the needs of target audience (e.g., organization workers) [70, 81]. This creates the need for designing interfaces that generate useful training data so that models can be improved as part of “natural” use [80]. Our findings also provide preliminary insights for designs that allow participants to easily interact with the notes that reflects their preferences, so it can also be used to generate useful training data. Quick edit suggestions, or memory aids to recall missing notes are examples of such design ideas. Future work can setup quantitative experiments to validate the quality of training data gathered from user interactions in a complex meeting recap like application.
회의 요약은 크라우드워크를 통해 학습된 ML 모델이 대상 고객(예: 조직 구성원)의 요구사항에 덜 부합하는 어려운 영역이다[70, 81]. 따라서 "자연스러운" 사용의 일환으로 모델을 개선할 수 있도록 유용한 학습 데이터를 생성하는 인터페이스를 설계해야 할 필요성이 생긴다[80]. 또한 이번 연구 결과는 참가자들이 선호도를 반영한 노트와 쉽게 상호작용할 수 있는 디자인에 대한 예비 인사이트를 제공하므로 유용한 학습 데이터를 생성하는 데에도 활용할 수 있다. 빠른 편집 제안이나 누락된 노트를 기억할 수 있는 기억 보조 기능이 이러한 디자인 아이디어의 예이다. 향후 연구에서는 애플리케이션과 같은 복잡한 회의 요약에서 사용자 상호작용을 통해 수집된 학습 데이터의 품질을 검증하기 위한 정량적 실험을 설정할 수 있다.
From a collaboration perspective, our findings suggest the use of notes for more than just meeting recap. Future work can explore the ways meeting participants can potentially engage in the discussions around notes, and its impact on generated ideas, consensus or information exchange between participants.
협업의 관점에서 볼 때, 우리의 연구 결과는 노트가 단순한 회의 요약 이상의 용도로 사용될 수 있음을 시사한다. 향후 연구에서는 회의 참가자들이 노트와 관련된 토론에 잠재적으로 참여할 수 있는 방법과 노트가 아이디어 창출, 합의 또는 참가자 간의 정보 교환에 미치는 영향에 대해 탐구할 수 있다.
REFERENCES
[1] Anita Acai, Ranil R Sonnadara, and Thomas A O’Neill. 2018. Getting with the times: a narrative review of the literature on group decision making in virtual environments and implications for promotions committees. Perspectives on Medical Education 7, 3 (2018), 147–155.
[2] Mark S Ackerman. 2000. The intellectual challenge of CSCW: the gap between social requirements and technical feasibility. Human–Computer Interaction 15, 2-3 (2000), 179–203.
[3] Mehdi Allahyari, Seyedamin Pouriyeh, Mehdi Assefi, Saeid Safaei, Elizabeth D Trippe, Juan B Gutierrez, and Krys Kochut. 2017. Text summarization techniques: a brief survey. arXiv preprint arXiv:1707.02268 (2017).
[4] Joseph A Allen, Nale Lehmann-Willenbrock, and Steven G Rogelberg. 2015. The Cambridge handbook of meeting science. Cambridge University Press.
[5] Paul André, Robert E. Kraut, and Aniket Kittur. 2014. Effects of Simultaneous and Sequential Work Structures on Distributed Collaborative Interdependent Tasks. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (Toronto, Ontario, Canada) (CHI ’14). Association for Computing Machinery, New York, NY, USA, 139–148. https://doi.org/10.1145/2556288.2557158
[6] Barry Arons. 1992. Techniques, perception, and applications of time-compressed speech. In Proceedings of 1992 Conference. 169–177.
[7] Satanjeev Banerjee, Carolyn Rosé, and Alexander I Rudnicky. 2005. The necessity of a meeting recording and playback system, and the benefit of topic–level annotations to meeting browsing. In IFIP Conference on Human-Computer Interaction. Springer, 643–656.
[8] Stacy M Branham, Anja Thieme, Lisa P Nathan, Steve Harrison, Deborah Tatar, and Patrick Olivier. 2014. Co-creating & identity-making in CSCW: revisiting ethics in design research. In Proceedings of the companion publication of the 17th ACM conference on Computer supported cooperative work & social computing. 305–308.
[9] Virginia Braun and Victoria Clarke. 2006. Using thematic analysis in psychology. Qualitative research in psychology 3, 2 (2006), 77–101.
[10] Susan L. Bryant, Andrea Forte, and Amy Bruckman. 2005. Becoming Wikipedian: Transformation of Participation in a Collaborative Online Encyclopedia. In Proceedings of the 2005 International ACM SIGGROUP Conference on Supporting Group Work (Sanibel Island, Florida, USA) (GROUP ’05). Association for Computing Machinery, New York, NY, USA, 1–10. https://doi.org/10.1145/1099203.1099205
[11] Hongshen Chen, Xiaorui Liu, Dawei Yin, and Jiliang Tang. 2017. A Survey on Dialogue Systems: Recent Advances and New Frontiers. SIGKDD Explor. Newsl. 19, 2 (nov 2017), 25–35. https://doi.org/10.1145/3166054.3166058
[12] Yulong Chen, Yang Liu, Liang Chen, and Yue Zhang. 2021. DialogSum: A Real-Life Scenario Dialogue Summarization Dataset. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. Association for Computational Linguistics, Online, 5062–5074. https://doi.org/10.18653/v1/2021.findings-acl.449
[13] Patrick Chiu, John Boreczky, Andreas Girgensohn, and Don Kimber. 2001. LiteMinutes: an Internet-based system for multimedia meeting minutes. In Proceedings of the 10th international conference on World Wide Web. 140–149.
[14] Brian Christian. 2020. The alignment problem: Machine learning and human values. WW Norton & Company.
[15] Amir Cohen, Amir Kantor, Sagi Hilleli, and Eyal Kolman. 2021. Automatic Rephrasing of Transcripts-based Action Items. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. Association for Computational Linguistics, Online, 2862–2873. https://doi.org/10.18653/v1/2021.findings-acl.253
[16] Deborah Cotton and Karen Gresty. 2006. Reflecting on the think-aloud method for evaluating e-learning. British Journal of Educational Technology 37, 1 (2006), 45–54.
[17] Richard C. Davis, Jason A. Brotherton, James A. Landay, Morgan N. Price, and Bill N. Schilit. 1998. NotePals: Lightweight Note Taking by the Group, for the Group. Technical Report UCB/CSD-98-997. EECS Department, University of California, Berkeley. http://www2.eecs.berkeley.edu/Pubs/TechRpts/1998/5354.html
[18] Yue Dong. 2018. A survey on neural network-based summarization methods. arXiv preprint arXiv:1804.04589 (2018).
[19] Karl Duncker and Lynne S Lees. 1945. On problem-solving. Psychological monographs 58, 5 (1945), i.
[20] Patrick Ehlen, Matthew Purver, and John Niekrasz. 2007. A Meeting Browser that Learns.. In AAAI Spring Symposium: Interaction Challenges for Intelligent Assistants. 33–40.
[21] Patrick Ehlen, Matthew Purver, John Niekrasz, Kari Lee, and Stanley Peters. 2008. Meeting Adjourned: Off-Line Learning Interfaces for Automatic Meeting Understanding. In Proceedings of the 13th International Conference on Intelligent User Interfaces (Gran Canaria, Spain) (IUI ’08). Association for Computing Machinery, New York, NY, USA, 276–284. https://doi.org/10.1145/1378773.1378810
[22] Michel Galley, Kathleen R. McKeown, Eric Fosler-Lussier, and Hongyan Jing. 2003. Discourse Segmentation of Multi-Party Conversation. In Proceedings of the 41st Annual Meeting of the Association for Computational Linguistics.
Association for Computational Linguistics, Sapporo, Japan, 562–569. https://doi.org/10.3115/1075096.1075167
[23] W. Geyer, H. Richter, and G.D. Abowd. 2003. Making multimedia meeting records more meaningful. In 2003 International Conference on Multimedia and Expo. ICME ’03. Proceedings (Cat. No.03TH8698), Vol. 2. II–669. https://doi.org/10.1109/ ICME.2003.1221705
[24] Werner Geyer, Heather Richter, and Gregory D Abowd. 2005. Towards a smarter meeting record—capture and access of meetings revisited. Multimedia Tools and Applications 27, 3 (2005), 393–410.
[25] Bogdan Gliwa, Iwona Mochol, Maciej Biesek, and Aleksander Wawer. 2019. SAMSum Corpus: A Human-annotated Dialogue Dataset for Abstractive Summarization. In Proceedings of the 2nd Workshop on New Frontiers in Summarization.
Association for Computational Linguistics, Hong Kong, China, 70–79. https://doi.org/10.18653/v1/D19-5409
[26] Barbara J. Grosz and Candace L. Sidner. 1986. Attention, Intentions, and the Structure of Discourse. Computational Linguistics 12, 3 (1986), 175–204. https://aclanthology.org/J86-3001
[27] Aaron Halfaker, Jonathan Morgan, Amir Sarabadani, and Adam Wight. 2016. ORES: Facilitating re-mediation of Wikipedia’s socio-technical problems. Working Paper, Wikimedia Research (2016).
[28] Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen. 2020. Deberta: Decoding-enhanced bert with disentan- gled attention. arXiv preprint arXiv:2006.03654 (2020).
[29] Marti A. Hearst. 1997. Text Tiling: Segmenting Text into Multi-paragraph Subtopic Passages. Computational Linguistics
23, 1 (1997), 33–64. https://aclanthology.org/J97-1003
[30] Karen Holtzblatt. 2009. Contextual design. In Human-Computer Interaction. CRC press, 71–86.
[31] A. Janin, D. Baron, J. Edwards, D. Ellis, D. Gelbart, N. Morgan, B. Peskin, T. Pfau, E. Shriberg, A. Stolcke, and C. Wooters. 2003. The ICSI Meeting Corpus. In 2003 IEEE International Conference on Acoustics, Speech, and Signal Processing, 2003.
Proceedings. (ICASSP ’03)., Vol. 1. I–I. https://doi.org/10.1109/ICASSP.2003.1198793
[32] David G Jansson and Steven M Smith. 1991. Design fixation. Design studies 12, 1 (1991), 3–11.
[33] Qi Jia, Siyu Ren, Yizhu Liu, and Kenny Q Zhu. 2022. Taxonomy of Abstractive Dialogue Summarization: Scenarios, Approaches and Future Directions. arXiv preprint arXiv:2210.09894 (2022).
[34] Vaiva Kalnikaite, Patrick Ehlen, and Steve Whittaker. 2012. Markup as You Talk: Establishing Effective Memory Cues While Still Contributing to a Meeting. In Proceedings of the ACM 2012 Conference on Computer Supported Cooperative Work (Seattle, Washington, USA) (CSCW ’12). Association for Computing Machinery, New York, NY, USA, 349–358. https://doi.org/10.1145/2145204.2145260
[35] Vaiva Kalnikaitundefined and Steve Whittaker. 2008. Cueing Digital Memory: How and Why Do Digital Notes Help Us Remember?. In Proceedings of the 22nd British HCI Group Annual Conference on People and Computers: Culture, Creativity, Interaction - Volume 1 (Liverpool, United Kingdom) (BCS-HCI ’08). BCS Learning and Development Ltd., Swindon, GBR, 153–161.
[36] C. Karen. 2009. Effective meetings. http://www.effectivemeetings.com Accessed Sept. 19th. 2009.
[37] Rick Kazman, Reem Al-Halimi, William Hunt, and Marilyn Mantei. 1996. Four Paradigms for Indexing Video Confer- ences. IEEE MultiMedia 3, 1 (jan 1996), 63–73. https://doi.org/10.1109/93.486705
[38] Rick Kazman, W. Hunt, and Marilyn Tremaine. 1995. Dynamic Meeting Annotation and Indexing. (02 1995).
[39] Muhammad Khalifa, Miguel Ballesteros, and Kathleen McKeown. 2021. A Bag of Tricks for Dialogue Summarization. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Online and Punta Cana, Dominican Republic, 8014–8022. https://doi.org/10.18653/v1/2021.emnlp-main.631
[40] Aniket Kittur, Bongwon Suh, Bryan A. Pendleton, and Ed H. Chi. 2007. He Says, She Says: Conflict and Coordination in Wikipedia. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (San Jose, California, USA) (CHI ’07). Association for Computing Machinery, New York, NY, USA, 453–462. https://doi.org/10.1145/1240624.1240698
[41] Rob Kling, Andy Hopper, and James Katz. 1992. Controversies about Privacy and Open Information in CSCW. In Proceedings of the 1992 ACM Conference on Computer-Supported Cooperative Work (Toronto, Ontario, Canada) (CSCW ’92). Association for Computing Machinery, New York, NY, USA, 15. https://doi.org/10.1145/143457.371594
[42] Tom Knoll, Francesco Moramarco, Alex Papadopoulos Korfiatis, Rachel Young, Claudia Ruffini, Mark Perera, Christian Perstl, Ehud Reiter, Anya Belz, and Aleksandar Savkov. 2022. User-Driven Research of Medical Note Generation Software. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics, Seattle, United States, 385–394. https://doi.org/10.18653/v1/2022.naacl-main.29
[43] Jung In Koh, Samantha Ray, Josh Cherian, Paul Taele, and Tracy Hammond. 2022. Show of Hands: Leveraging Hand Gestural Cues in Virtual Meetings for Intelligent Impromptu Polling Interactions. In 27th International Conference on Intelligent User Interfaces (Helsinki, Finland) (IUI ’22). Association for Computing Machinery, New York, NY, USA, 292–309. https://doi.org/10.1145/3490099.3511153
[44] Jintae Lee and Kum-Yew Lai. 1991. What’s in design rationale? Human–Computer Interaction 6, 3-4 (1991), 251–280.
[45] Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. 2020. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, Online, 7871–7880. https://doi.org/10.18653/v1/2020.acl- main.703
[46] Chin-Yew Lin. 2004. ROUGE: A Package for Automatic Evaluation of Summaries. In Text Summarization Branches Out.
Association for Computational Linguistics, Barcelona, Spain, 74–81. https://aclanthology.org/W04-1013
[47] Mai Skjott Linneberg and Steffen Korsgaard. 2019. Coding qualitative data: A synthesis guiding the novice. Qualitative research journal 19, 3 (2019), 259–270.
[48] Michael Xieyang Liu, Aniket Kittur, and Brad A. Myers. 2021. To Reuse or Not To Reuse? A Framework and System for Evaluating Summarized Knowledge. Proc. ACM Hum.-Comput. Interact. 5, CSCW1, Article 166 (apr 2021), 35 pages. https://doi.org/10.1145/3449240
[49] William C Mann and Sandra A Thompson. 1987. Rhetorical structure theory: Description and construction of text structures. In Natural language generation. Springer, 85–95.
[50] Catherine C. Marshall and A.J. Bernheim Brush. 2002. From Personal to Shared Annotations. In CHI ’02 Extended Abstracts on Human Factors in Computing Systems (Minneapolis, Minnesota, USA) (CHI EA ’02). Association for Computing Machinery, New York, NY, USA, 812–813. https://doi.org/10.1145/506443.506610
[51] Paul Mihas. 2019. Qualitative data analysis. In Oxford research encyclopedia of education.
[52] Thomas P Moran, Leysia Palen, Steve Harrison, Patrick Chiu, Don Kimber, Scott Minneman, William Van Melle, and Polle Zellweger. 1997. “I’ll get that off the audio” a case study of salvaging multimedia meeting records. In Proceedings of the ACM SIGCHI Conference on Human factors in computing systems. 202–209.
[53] Thomas P. Moran, William van Melle, and Patrick Chiu. 1998. Tailorable Domain Objects as Meeting Tools for an Electronic Whiteboard. In Proceedings of the 1998 ACM Conference on Computer Supported Cooperative Work (Seattle, Washington, USA) (CSCW ’98). Association for Computing Machinery, New York, NY, USA, 295–304. https:
//doi.org/10.1145/289444.289504
[54] N. Moratanch and S. Chitrakala. 2017. A survey on extractive text summarization. In 2017 International Conference on Computer, Communication and Signal Processing (ICCCSP). 1–6. https://doi.org/10.1109/ICCCSP.2017.7944061
[55] Kevin K. Nam and Mark S. Ackerman. 2007. Arkose: Reusing Informal Information from Online Discussions. In Proceedings of the 2007 ACM International Conference on Supporting Group Work (Sanibel Island, Florida, USA) (GROUP ’07). Association for Computing Machinery, New York, NY, USA, 137–146. https://doi.org/10.1145/1316624.1316644
[56] Mukesh Nathan, Mercan Topkara, Jennifer Lai, Shimei Pan, Steven Wood, Jeff Boston, and Loren Terveen. 2012. In Case You Missed It: Benefits of Attendee-Shared Annotations for Non-Attendees of Remote Meetings. In Proceedings of the ACM 2012 Conference on Computer Supported Cooperative Work (Seattle, Washington, USA) (CSCW ’12). Association for Computing Machinery, New York, NY, USA, 339–348. https://doi.org/10.1145/2145204.2145259
[57] Niina Nurmi. 2011. Coping with coping strategies: How distributed teams and their members deal with the stress of distance, time zones and culture. Stress and Health 27, 2 (2011), 123–143.
[58] Samuli Pekkola. 2003. Designed for Unanticipated Use: Common Artefacts as Design Principle for CSCW Applications. In Proceedings of the 2003 ACM International Conference on Supporting Group Work (Sanibel Island, Florida, USA) (GROUP ’03). Association for Computing Machinery, New York, NY, USA, 359–368. https://doi.org/10.1145/958160.958218
[59] Archiki Prasad, Trung Bui, Seunghyun Yoon, Hanieh Deilamsalehy, Franck Dernoncourt, and Mohit Bansal. 2023. MeetingQA: Extractive Question-Answering on Meeting Transcripts. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Toronto,
Canada, 15000–15025. https://aclanthology.org/2023.acl-long.837
[60] Matthew Purver, Konrad P. Körding, Thomas L. Griffiths, and Joshua B. Tenenbaum. 2006. Unsupervised Topic Modelling for Multi-Party Spoken Discourse. In Proceedings of the 21st International Conference on Computational Linguistics and 44th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, Sydney, Australia, 17–24. https://doi.org/10.3115/1220175.1220178
[61] Paul Resnick, Neophytos Iacovou, Mitesh Suchak, Peter Bergstrom, and John Riedl. 1994. GroupLens: An Open Architecture for Collaborative Filtering of Netnews. In Proceedings of the 1994 ACM Conference on Computer Supported Cooperative Work (Chapel Hill, North Carolina, USA) (CSCW ’94). Association for Computing Machinery, New York,
NY, USA, 175–186. https://doi.org/10.1145/192844.192905
[62] Heather Richter, Gregory D. Abowd, Werner Geyer, Ludwin Fuchs, Shahrokh Daijavad, and Steven Poltrock. 2001. Integrating Meeting Capture within a Collaborative Team Environment. In Ubicomp 2001: Ubiquitous Computing, Gregory D. Abowd, Barry Brumitt, and Steven Shafer (Eds.). Springer Berlin Heidelberg, Berlin, Heidelberg, 123–138.
[63] Advait Sarkar, Sean Rintel, Damian Borowiec, Rachel Bergmann, Sharon Gillett, Danielle Bragg, Nancy Baym, and Abigail Sellen. 2021. The Promise and Peril of Parallel Chat in Video Meetings for Work. In Extended Abstracts of the 2021 CHI Conference on Human Factors in Computing Systems (Yokohama, Japan) (CHI EA ’21). Association for Computing Machinery, New York, NY, USA, Article 260, 8 pages. https://doi.org/10.1145/3411763.3451793
[64] Mike Schaekermann, Joslin Goh, Kate Larson, and Edith Law. 2018. Resolvable vs. Irresolvable Disagreement: A Study on Worker Deliberation in Crowd Work. Proc. ACM Hum.-Comput. Interact. 2, CSCW, Article 154 (nov 2018), 19 pages. https://doi.org/10.1145/3274423
[65] Michael F Schober and Herbert H Clark. 1989. Understanding by addressees and overhearers. Cognitive psychology 21, 2 (1989), 211–232.
[66] Deepa Sethi and Manisha Seth. 2009. Interpersonal communication: Lifeblood of an organization. IUP Journal of Soft Skills 3 (2009).
[67] Pao Siangliulue, Kenneth C. Arnold, Krzysztof Z. Gajos, and Steven P. Dow. 2015. Toward Collaborative Ideation at Scale: Leveraging Ideas from Others to Generate More Creative and Diverse Ideas. In Proceedings of the 18th ACM Conference on Computer Supported Cooperative Work and Social Computing (Vancouver, BC, Canada) (CSCW ’15).
Association for Computing Machinery, New York, NY, USA, 937–945. https://doi.org/10.1145/2675133.2675239
[68] C. Estelle Smith, Bowen Yu, Anjali Srivastava, Aaron Halfaker, Loren Terveen, and Haiyi Zhu. 2020. Keeping Community in the Loop: Understanding Wikipedia Stakeholder Values for Machine Learning-Based Systems. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems (Honolulu, HI, USA) (CHI ’20). Association for Computing Machinery, New York, NY, USA, 1–14. https://doi.org/10.1145/3313831.3376783
[69] Cheri Speier. 2006. The influence of information presentation formats on complex task decision-making performance.
International journal of human-computer studies 64, 11 (2006), 1115–1131.
[70] Susan Leigh Star and Karen Ruhleder. 1994. Steps towards an Ecology of Infrastructure: Complex Problems in Design and Access for Large-Scale Collaborative Systems. In Proceedings of the 1994 ACM Conference on Computer Supported Cooperative Work (Chapel Hill, North Carolina, USA) (CSCW ’94). Association for Computing Machinery, New York,
NY, USA, 253–264. https://doi.org/10.1145/192844.193021
[71] Jaime Teevan, Nancy Baym, Jenna Butler, Brent Hecht, Sonia Jaffe, Kate Nowak, Abigail Sellen, Longqi Yang, Marcus Ash, Kagonya Awori, Mia Bruch, Piali Choudhury, Adam Coleman, Scott Counts, Shiraz Cupala, Mary Czerwinski, Ed Doran, Elizabeth Fetterolf, Mar Gonzalez Franco, Kunal Gupta, Aaron L Halfaker, Constance Hadley, Brian Houck,
Kori Inkpen, Shamsi Iqbal, Eric Knudsen, Stacey Levine, Siân Lindley, Jennifer Neville, Jacki O’Neill, Rick Pollak, Victor Poznanski, Sean Rintel, Neha Parikh Shah, Siddharth Suri, Adam D. Troy, and Mengting Wan. 2022. Microsoft New Future of Work Report 2022. Technical Report MSR-TR-2022-3. Microsoft. https://www.microsoft.com/en- us/research/publication/microsoft-new-future-of-work-report-2022/
[72] Mercan Topkara, Shimei Pan, Jennifer Lai, Stephen P Wood, and Jeff Boston. 2010. Tag me while you can: Making online recorded meetings shareable and searchable. IBM Research rep. RC25038 (W1008-057) (2010).
[73] Simon Tucker, Ofer Bergman, Anand Ramamoorthy, and Steve Whittaker. 2010. Catchup: A Useful Application of Time-Travel in Meetings. In Proceedings of the 2010 ACM Conference on Computer Supported Cooperative Work (Savannah, Georgia, USA) (CSCW ’10). Association for Computing Machinery, New York, NY, USA, 99–102. https:
//doi.org/10.1145/1718918.1718937
[74] Don Tuggener, Margot Mieskes, Jan Deriu, and Mark Cieliebak. 2021. Are We Summarizing the Right Way? A Survey of Dialogue Summarization Data Sets. In Proceedings of the Third Workshop on New Frontiers in Summarization. Association for Computational Linguistics, Online and in Dominican Republic, 107–118. https://doi.org/10.18653/v1/2021.newsum- 1.12
[75] Gokhan Tur and Renato De Mori. 2011. Spoken language understanding: Systems for extracting semantic information from speech. John Wiley & Sons.
[76] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Advances in neural information processing systems 30 (2017).
[77] James R. Wallace, Saba Oji, and Craig Anslow. 2017. Technologies, Methods, and Values: Changes in Empirical Research at CSCW 1990 - 2015. Proc. ACM Hum.-Comput. Interact. 1, CSCW, Article 106 (dec 2017), 18 pages. https:
[78] Steve Whittaker, Patrick Hyland, and Myrtle Wiley. 1994. Filochat: Handwritten Notes Provide Access to Recorded Conversations. In Conference Companion on Human Factors in Computing Systems (Boston, Massachusetts, USA) (CHI ’94). Association for Computing Machinery, New York, NY, USA, 219. https://doi.org/10.1145/259963.260380
[79] Steve Whittaker, Simon Tucker, Kumutha Swampillai, and Rachel Laban. 2008. Design and evaluation of systems to support interaction capture and retrieval. Personal and Ubiquitous Computing 12, 3 (2008), 197–221.
[80] Qian Yang. 2017. The role of design in creating machine-learning-enhanced user experience. In 2017 AAAI spring symposium series.
[81] Qian Yang, Justin Cranshaw, Saleema Amershi, Shamsi T. Iqbal, and Jaime Teevan. 2019. Sketching NLP: A Case Study of Exploring the Right Things To Design with Language Intelligence. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems (Glasgow, Scotland Uk) (CHI ’19). Association for Computing Machinery, New York, NY, USA, 1–12. https://doi.org/10.1145/3290605.3300415
[82] Qian Yang, Aaron Steinfeld, Carolyn Rosé, and John Zimmerman. 2020. Re-Examining Whether, Why, and How Human-AI Interaction Is Uniquely Difficult to Design. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems (Honolulu, HI, USA) (CHI ’20). Association for Computing Machinery, New York, NY, USA, 1–13. https://doi.org/10.1145/3313831.3376301
[83] Qian Yang, Aaron Steinfeld, and John Zimmerman. 2019. Unremarkable AI: Fitting Intelligent Decision Support into Critical, Clinical Decision-Making Processes. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems (Glasgow, Scotland Uk) (CHI ’19). Association for Computing Machinery, New York, NY, USA, 1–11. https://doi.org/10.1145/3290605.3300468
[84] Nicole Yankelovich, William Walker, Patricia Roberts, Mike Wessler, Jonathan Kaplan, and Joe Provino. 2004. Meeting Central: Making Distributed Meetings More Effective. In Proceedings of the 2004 ACM Conference on Computer Supported Cooperative Work (Chicago, Illinois, USA) (CSCW ’04). Association for Computing Machinery, New York, NY, USA, 419–428. https://doi.org/10.1145/1031607.1031678
[85] Jeffrey M Zacks, Barbara Tversky, and Gowri Iyer. 2001. Perceiving, remembering, and communicating structure in events. Journal of experimental psychology: General 130, 1 (2001), 29.
[86] Amy X. Zhang and Justin Cranshaw. 2018. Making Sense of Group Chat through Collaborative Tagging and Summa- rization. Proc. ACM Hum.-Comput. Interact. 2, CSCW, Article 196 (nov 2018), 27 pages. https://doi.org/10.1145/3274465
[87] Amy X. Zhang, Lea Verou, and David Karger. 2017. Wikum: Bridging Discussion Forums and Wikis Using Recursive Summarization. In Proceedings of the 2017 ACM Conference on Computer Supported Cooperative Work and Social Computing (Portland, Oregon, USA) (CSCW ’17). Association for Computing Machinery, New York, NY, USA, 2082–2096. https://doi.org/10.1145/2998181.2998235
[88] Yusen Zhang, Ansong Ni, Tao Yu, Rui Zhang, Chenguang Zhu, Budhaditya Deb, Asli Celikyilmaz, Ahmed Hassan Awadallah, and Dragomir Radev. 2021. An Exploratory Study on Long Dialogue Summarization: What Works and What’s Next. In Findings of the Association for Computational Linguistics: EMNLP 2021. Association for Computational Linguistics, Punta Cana, Dominican Republic, 4426–4433. https://doi.org/10.18653/v1/2021.findings-emnlp.377


