원문 : https://aclanthology.org/2022.findings-emnlp.261/
이 글에 대한 모든 권리는 원문 저자인 Ruochen Xu, Chenguang Zhu, Michael Zeng에게 있음.
############
Narrate Dialogues for Better Summarization
Ruochen Xu, Chenguang Zhu, Michael Zeng
Azure Cognitive Services Research, Microsoft
{ruox, chezhu, nzeng}@microsoft.com
Abstract
Dialogue summarization models aim to generate a concise and accurate summary for multi- party dialogue. The complexity of dialogue, including coreference, dialogue acts, and inter-speaker interactions bring unique challenges to dialogue summarization. Most recent neural models achieve state-of-art performance following the pretrain-then-finetune recipe, where the large-scale language model (LLM) is pre-trained on large-scale single-speaker written text, but later finetuned on multi-speaker dialogue text. To mitigate the gap between pre-training and fine-tuning, we propose several approaches to convert the dialogue into a third-person narrative style and show that the narration serves as a valuable annotation for LLMs. Empirical results on three benchmark datasets show our simple approach achieves higher scores on the ROUGE and a factual correctness metric.
대화 요약 모델은 다자간 대화를 위한 간결하고 정확한 요약을 생성하는 것을 목표로 한다. 핵심 참조, 대화 행위, 화자 간 상호작용을 포함한 대화의 복잡성은 대화 요약에 고유한 문제를 야기한다. 최신 신경 모델은 대규모 언어 모델(LLM)을 대규모 단일 화자 서면 텍스트로 사전 학습시킨 후 나중에 다중 화자 대화 텍스트로 파인튜닝하는 사전 학습 후 파인튜닝 방식을 통해 최첨단 성능을 달성한다. 사전 학습과 파인튜닝 사이의 격차를 완화하기 위해, 대화를 3인칭 내러티브 스타일로 변환하는 다양한 접근 방식을 제안하고 나레이션이 LLM에 유용한 주석 역할을 한다는 것을 보여준다. 세 가지 벤치마크 데이터 세트에 대한 경험적 결과에 따르면 간단한 접근 방식이 ROUGE와 사실 정확도 지표에서 더 높은 점수를 획득하는 것으로 나타났다.
- Introduction
Online dialogues are increasingly important in the modern working environment, emphasizing the need for an automatic system to generate concise and accurate summaries. Neural dialogue summarization has become an emerging research direction in recent years (Feng et al., 2021a) with the creation of several benchmarks (Gliwa et al., 2019; Mehnaz et al., 2021; Fabbri et al., 2021; Zhong et al., 2021; Zhu et al., 2021a). Most works utilized large-scale language models (LLM) and finetune it on downstream dialogue summarization datasets. Despite the strong generalization power of LLM on summarization tasks (Lewis et al., 2020; Zhang et al., 2020a), dialogue summarization holds some unique challenges (Feng et al., 2021a). First, dialogues and their summaries are in different language styles. This discrepancy requires the summarization model to complete the tasks of both style transfer and summarization. The domain discrepancy also exists between the pre-training and fine-tuning stages because LLMs are often pre-trained on the web corpus where the majority of text is in written language. The dialogues, on the other hand, are in spoken language. Second, the amount of training data is generally smaller than news summarization. For instance, the widely used SAMSum dataset (Gliwa et al., 2019) for dialogue summarization contains about 16k annotations, while the CNN/DailyMail dataset (Nallapati et al., 2016) is a magnitude larger at size of 300k. Third, dialogues contain complex dialogue acts with frequent topic changes and event occurrences. News or academic articles follow certain patterns in writing and could be exploited for summarization (Zhu et al., 2021b). On the other hand, key information is scattered in the dialogues. To generate comprehensive summaries, a model needs to identify salient information across the dialogue and rephrase the terms.
온라인 대화는 현대의 업무 환경에서 점점 더 중요해지고 있으며, 간결하고 정확한 요약을 생성하는 자동 시스템의 필요성이 강조되고 있다. 신경 대화 요약은 최근 몇 년 동안 여러 벤치마크가 만들어지면서 새로운 연구 방향이 되었다(Feng et al., 2021a)(Gliwa et al., 2019; Mehnaz et al., 2021; Fabbri et al., 2021; Zhong et al., 2021; Zhu et al., 2021a). 대부분의 연구는 대규모 언어 모델(LLM)을 활용하고 다운스트림 대화 요약 데이터 세트에서 이를 파인튜닝했다. 요약 작업에 대한 LLM의 강력한 일반화 능력에도 불구하고(Lewis et al., 2020; Zhang et al., 2020a), 대화 요약에는 몇 가지 고유한 과제가 있다(Feng et al., 2021a). 첫째, 대화와 그 요약은 서로 다른 언어 스타일로 되어 있다. 이러한 불일치로 인해 요약 모델은 스타일 전달과 요약이라는 두 가지 작업을 모두 완료해야 한다. 사전 학습과 파인튜닝 단계 사이에도 도메인 불일치가 존재하는데, 그 이유는 대부분의 텍스트가 서면 언어인 웹 말뭉치에 대해 LLM이 사전 학습되는 경우가 많기 때문이다. 반면에 대화는 음성 언어로 되어있다. 둘째, 훈련 데이터의 양이 일반적으로 뉴스 요약보다 적다. 예를 들어, 대화 요약에 널리 사용되는 SAMSum 데이터셋(Gliwa 외., 2019)은 약 1.6만 개의 주석을 포함하고 있는 반면, CNN/DailyMail 데이터셋(Nallapati 외., 2016)은 그보다 훨씬 큰 30만 개의 주석을 포함하고 있다. 셋째, 대화에는 주제 변경과 사건 발생이 빈번한 복잡한 대화 행위가 포함되어 있다. 뉴스나 학술 기사는 글쓰기에서 일정한 패턴을 따르기 때문에 요약에 악용될 수 있다(Zhu et al., 2021b). 반면에 대화에는 핵심 정보가 흩어져 있다. 포괄적인 요약을 생성하려면 모델은 대화 전체에서 두드러진 정보를 식별하고 용어를 다시 표현해야 한다.
To address these challenges, existing works incorporate external models or tools to help with the dialogue summarization (Liu and Chen, 2021; Feng et al., 2021b; Wu et al., 2021; Liu et al., 2021b). However, they either annotate the dialogues on the token or utterance level, such as coreference res- olution (Liu et al., 2021b), personal named entity (Liu and Chen, 2021), utterance intent (Wu et al., 2021), or redundant utterance identification (Feng et al., 2021b). In this work, we propose a dialogue- level annotation describing "What happened in the dialogue?" in natural language. The narrated dialogues effectively close the domain gap between pretrain and finetune, as well as between dialogues and summaries. It also helps with data sparsity since the model could effectively transfer knowledge from out-of-domain annotations such as news summarization datasets. The narrative description of dialogues serves as an effective annotator to label coreference, dialogue acts, events, and user intents. Since the narration are in natural language just as the dialogues themselves, we simply replace colon is used to separate the speaker from the utterance. The format has been treated as the default for some widely used datasets. To better format the turns in a dialogue so that they will be closer to a narrative sentence, we convert the style of a turn using two categories of methods: rule-based transfer and model-based transfer. After conversion, we follow the standard finetune strategy of large-scale language models on the converted dialogue and the original summarization.
이러한 문제를 해결하기 위해 기존 연구에서는 대화 요약에 도움이 되는 기업 내 외부 모델 또는 도구를 사용했다(Liu and Chen, 2021; Feng et al., 2021b; Wu et al., 2021; Liu et al., 2021b). 그러나 이들은 토큰 또는 발화 수준에서 대화에 주석을 달거나, 핵심 참조 해결(Liu et al., 2021b), 개인 명명 엔티티(Liu and Chen, 2021), 발화 의도(Wu et al., 2021) 또는 중복 발화 식별(Feng et al., 2021b)과 같은 방식으로 주석을 달았다. 본 연구에서는 "대화에서 무슨 일이 일어났습니까?"를 자연어로 설명하는 대화 수준 주석을 제안한다. 나레이션이 포함된 다이아로그는 사전 훈련과 파인튜닝, 대화와 요약 사이의 영역 간극을 효과적으로 좁힌다. 또한 뉴스 요약 데이터 세트와 같은 도메인 외부 주석에서 지식을 효과적으로 전달할 수 있으므로 데이터 희소성에도 도움이 된다. 대화에 대한 내러티브 설명은 핵심 참조, 대화 행위, 이벤트 및 사용자 의도에 레이블을 지정하는 효과적인 주석 역할을 한다. 나레이션은 대화 자체와 마찬가지로 자연어로 되어 있기 때문에 콜론으로 화자와 문장을 구분하기만 하면 된다. 이 형식은 널리 사용되는 일부 데이터 세트의 기본값으로 처리했다. 대화의 차례 형식을 내러티브 문장에 더 가깝게 만들기 위해, 규칙 기반 전환과 모델 기반 전환이라는 두 가지 범주의 방법을 사용하여 차례 스타일을 변환한다. 변환 후에는 변환된 대화와 원본 요약에 대해 대규모 언어 모델의 표준 파인튜닝 전략을 따른다.
- Rule-Based Transfer
Quote To make the dialogue input similar to the web corpus on which large-scaled language models are pretrained, we firstly make dialogue more like written style by simply adding quotation marks ’"’ to quote the utterance. Specifically, we use the template of <s i said, "u i ".> as the input format for each turn. In the case where the utterance u i contains a question mark, we change the template to <s i asked, "u i ".> to reflect the fact that the speaker is asking a question or concatenate the narration with the dialogue text. As as result, our frame can be plug-and-play with most LLMs without any modification on the model architecture.
인용 대규모 언어 모델이 사전 학습된 웹 말뭉치와 유사한 대화 입력을 만들기 위해 먼저 발화를 인용할 때 따옴표 '"'를 추가하여 대화 형식을 글과 비슷하게 만들었다. 구체적으로는 각 턴의 입력 형식으로 <s i said, "u i ".> 템플릿을 사용한다. 발화 u i에 물음표가 포함된 경우 화자가 질문하고 있다는 사실을 반영하거나 대화 텍스트와 나레이션을 연결하기 위해 템플릿을 <s i asked, "u i ".>로 변경한다. 그 결과, 우리의 프레임은 모델 아키텍처를 수정하지 않고도 대부분의 LLM에 플러그 앤 플레이할 수 있다.
We empirically verified the effectiveness of different narrating methods on three benchmark datasets in both supervised and zero-shot settings. Our best narrating method, despite being very simple, outperforming complex and strong baselines on both ROUGE (Lin, 2004) and FactCC (Kryscin- ski et al., 2020) scores.
유니티는 세 가지 벤치마크 데이터 세트에 대해 감독 및 제로샷 설정에서 다양한 나레이션 방법의 효과를 경험적으로 검증했다. 가장 우수한 나레이션 방법은 매우 단순함에도 불구하고 ROUGE(Lin, 2004) 및 FactCC(Kryscinski et al., 2020) 점수 모두에서 복잡하고 강력한 기준선보다 우수한 성능을 보였다.

Figure 1: Example of the prompt for dialog-to-narrative conversion with InstructGPT model. The narrative types are rephrase, plot and event from the top to bottom.
그림 1: InstructGPT 모델을 사용한 대화에서 내러티브로 변환하기 위한 프롬프트의 예. 내러티브 유형은 위에서부터 순서대로 재구문, 플롯 및 이벤트이다.
-
Methods
We define a dialogue D to be a sequence of turns, where the i-th turn consists of a speaker si and a utterance ui:
대화 D를 차례의 시퀀스로 정의하고, 여기서 i번째 차례는 화자 si와 발화 ui로 구성된다:
D = {(s1, u1), . . . , (sn, un)}
A turn in a dialogue is usually represented in the textual format as follows: "si : ui", where a ten contains first and second personal pronouns, e.g. the speakers use "I" to refer to themselves and "you" to refer to other people in the dialogue. To make the dialogue more like a written style, we replace the first and second-person pronouns with the resolved speaker names. Similarly, we use the template of <si said/asked that pron_resol(ui)> as the input format for each turn, where pron_resol(ui) is a pronoun resolution function that replaces all the pronouns of a first and second person with resolved speaker names. The replacement will result the lack of verb agreement. Empirically, we found the ungrammatical transcripts after rule-based conversion have little impact on the grammar correctness of the generated summary. We hypothesize that it was because that our summarization models are pretrained and finetuned to always generate gram- matically correct English text. Therefore, they can generalize to generate the same even if the input narratives have some grammar errors. The detailed template is shown in appendix A.1.1.
대화의 차례는 일반적으로 다음과 같이 텍스트 형식으로 표시된다:"시 : 유이", 여기서 10에는 1, 2인칭 대명사가 포함된다. 예를 들어 화자는 대화에서 자신을 지칭할 때는 "나"를, 다른 사람을 지칭할 때는 "너"를 사용한다. 대화를 글쓰기 스타일과 비슷하게 만들기 위해 1인칭 및 2인칭 대명사를 확인된 화자 이름으로 바꾼다. 마찬가지로, 각 턴의 입력 형식으로 <si said/asked that pron_resol(ui)> 템플릿을 사용하는데, 여기서 pron_resol(ui)은 일인칭과 이인칭의 모든 대명사를 확인된 화자 이름으로 대체하는 대명사 확인 함수이다. 이렇게 대체하면 동사의 일치 여부가 부족해진다. 경험적으로, 규칙 기반 변환 후 비문법적인 성적표는 생성된 요약의 문법 정확도에 거의 영향을 미치지 않는 것으로 나타났다. 이는 요약 모델이 항상 문법적으로 정확한 영어 텍스트를 생성하도록 사전 학습되고 파인튜닝되었기 때문이라는 가설을 세웠다. 따라서 입력된 내러티브에 약간의 문법 오류가 있더라도 동일하게 생성하도록 일반화할 수 있다. 자세한 템플릿은 부록 A.1.1에 나와 있다.
- Model-Based Transfer
Apart from personal pronouns resolution, there are still many characteristics making dialogue summarization challenging. For instance, dialogue transcription contains informal spoken language, which could be informal and noisy. In addition, dialogue is often not well structured with rapid topic changes and unexpected interruptions. To address these challenges, we introduce a model-based method to convert dialogue into well-written narratives that are easier to read and understand.
인칭 대명사 해결 외에도 대화 요약에 어려움을 주는 많은 특성이 여전히 존재한다. 예를 들어, 대화 내용에는 비공식적인 구어가 포함되어 있어 비공식적이고 시끄러울 수 있다. 또한 급격한 주제 변경과 예기치 않은 중단으로 인해 대화가 제대로 구조화되지 않는 경우가 많다. 이러한 문제를 해결하기 위해 대화를 읽고 이해하기 쉬운 잘 쓰여진 내러티브로 변환하는 모델 기반 방법을 도입했다.
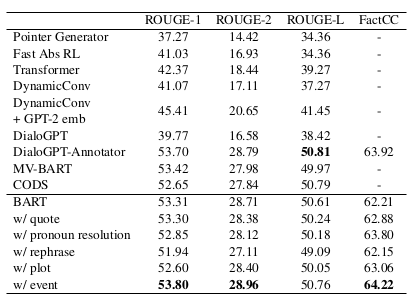
Table 1: Supervised fine tuning result on SAMSum test split. The whole train split is used to finetune a Bart- large model. Baselines performance are taken from works of Wu et al. (2021) and Feng et al. (2021b)
표 1: SAMSum 테스트 분할에 대한 지도 파인튜닝 결과. 전체 훈련 분할은 Bart-대형 모델을 파인튜닝하는 데 사용된다. 기준선 성능은 Wu 외(2021) 및 Feng 외(2021b)의 연구에서 가져왔다.
To the best of our knowledge, there is no existing parallel corpus between dialogue and its narrative equivalence. Therefore, we generate narratives by leveraging the strong zero-shot capability of InstructGPT (Ouyang et al., 2022) to follow instructions for a certain task.
우리가 아는 한, 대화와 이야기 동등성 사이의 병렬 코퍼스는 없다. 따라서 우리는 특정 작업에 대한 지침을 따르기 위해 InstructGpt의 강력한 제로 샷 기능을 활용하여 이야기를 생성한다 (Ouyang et al., 2022).
An example of the prompt and model-generated text from InstructGPT is shown in figure 1. To construct the prompt, we first index the turns in the original dialogue with a prefix number starting from 1. The indices are empirically found to help generate comprehensive narratives in our preliminary experiments.
그림 1에는 InstructGPT에서 생성된 프롬프트와 모델 생성 텍스트의 예가 나와 있다. 프롬프트를 구성하기 위해 먼저 1부터 시작하는 접두사 번호로 원본 대화의 차례를 색인화했다. 이 색인은 예비 실험에서 포괄적인 이야기를 생성하는 데 도움이 되는 것으로 경험적으로 밝혀졌다.
Another trick we applied during prompt construction is the bootstrap text. As shown in the first example of figure 1, the bootstrap text "1. Nickola asked" has two purposes: First, the index constrains the language model to follow the same pattern and generate narratives one by one according to the indices of the original dialogue. Second, "Nickola asked" constrains the following generation to be a third-person narrative. Similar to the rule-based conversion, we replace "asked" with "said" if there is no question mark in the first turn.
프롬프트 구성 시 적용한 또 다른 트릭은 부트스트랩 텍스트이다. 그림 1의 첫 번째 예에서 볼 수 있듯이 부트스트랩 텍스트 "1. 니콜라가 물었다"는 두 가지 목적을 가지고 있다: 첫째, 인덱스는 언어 모델이 동일한 패턴을 따르고 원본 대화의 이야기에 따라 하나씩 내러티브를 생성하도록 제한한다. 둘째, "니콜라가 물었다"는 다음 세대가 3인칭 내러티브가 되도록 제한한다. 규칙 기반 변환과 마찬가지로 첫 번째 턴에 물음표가 없는 경우 "물었다"를 "말했다"로 대체한다.
To capture various aspects of the dialogue, we propose three model-based narratives: 1) rephrase
2) plot and 3) event. The corresponding instruction and bootstrap text for each type are shown in figure 1. For rephrasing, we aim to narrate the dialog turn-by-turn. For plot narrative, we repurpose the terminology "plot" in film and play to gener ate the sequence of interconnected events within the dialogue. For the event narrative, we directly generated the itemized salient events that happened in the dialogue. For rephrasing, we replace the dialogue with the generated text. For the plot and event, since they are shorter and more concise, we concatenate them with the default dialogue format.
대화의 다양한 측면을 포착하기 위해 세 가지 모델 기반 이야기를 제안한다: 1) 리프레이즈
2) 플롯 및 3) 이벤트. 각 유형에 해당하는 지침과 부트스트랩 텍스트는 그림 1에 나와 있다. 리프레이징의 경우, 대화를 차례대로 나레이션하는 것을 목표로 한다. 플롯 내러티브의 경우, 영화와 연극에서 '줄거리'라는 용어를 재사용하여 대화 내에서 상호 연결된 사건의 순서를 생성한다. 이벤트 내러티브의 경우 대화에서 발생한 주요 사건을 항목별로 직접 생성했다. 문구 변경의 경우, 생성된 텍스트로 대화를 대체했다. 줄거리와 이벤트의 경우 더 짧고 간결하기 때문에 기본 대화 형식을 사용하여 연결한다.
-
Experiment
We conduct through experiment on three dialogue summarization datasets: SAMSum (Gliwa et al., 2019), DialogSum (Chen et al., 2021), and ADSC (Misra et al., 2015) under both supervised and zero- shot settings. The properties and statistics of the datasets used in our experiment is shown in table 2.
세 가지 대화 요약 데이터셋을 대상으로 실험을 진행했다: SAMSum(Gliwa et al., 2019), DialogSum(Chen et al., 2021), ADSC(Misra et al., 2015)를 감독 및 제로 샷 설정 모두에서 실험했다. 실험에 사용된 데이터 세트의 속성 및 통계는 표 2에 나와 있다.
- Implementation
For supervised finetuning, we used BART-large model (Lewis et al., 2020) from the implementation of HuggingFace 1. We also tested Pegasus (Zhang et al., 2020b) and T5 (Raffel et al., 2020) in our preliminary experiments, and empirically found that BART achieves the best performance among them. The choice of pretrained language model is also consistent with previous works of Feng et al. (2021b); Chen and Yang (2020); Wu et al. (2021). For zero-shot experiments, we used the BART- large-CNN as the off-the-shelf summarizer. 2. The model is initialized on the BART-large model and finetuned on CNN/DailyMail Dataset (See et al., 2017), a widely used news summarization dataset containing over 300k unique news articles. More details of implementation are included in the appendix A.1.
SFT를 위해, 저희는 허깅페이스 1을 구현한 BART 대형 모델(Lewis et al., 2020)을 사용했다. 또한 예비 실험에서 페가수스(Zhang et al., 2020b)와 T5(Raffel et al., 2020)를 테스트했으며, 경험적으로 BART가 이 중 가장 우수한 성능을 달성한다는 것을 확인했다. 사전 학습된 언어 모델의 선택은 Feng et al. (2021b), Chen and Yang (2020), Wu et al. (2021)의 이전 연구와도 일치한다. 제로 샷 실험에서는 기성품 요약기로 BART- large-CNN을 사용했다. 2. 이 모델은 BART-large 모델에서 초기화되고 30만 개 이상의 고유 뉴스 기사를 포함하는 널리 사용되는 뉴스 요약 데이터셋인 CNN/DailyMail 데이터셋(참조: et al., 2017)에서 파인튜닝된다. 구현에 대한 자세한 내용은 부록 A.1에 포함되어 있다.
- Evaluation and Baselines
We use standard ROUGE (Lin, 2004) metric as automatic metrics, including ROUGE-1, ROUGE-2, and ROUGE-L. For implementation, we followed Gliwa et al. (2019) to use the py-rouge package 3 with stemming. In addition to ROUGE scores, we introduce FactCC (Kryscinski et al., 2020) as an additional metric for factual correctness. A higher FactCC score means that the system summary is more factually consistent with the reference summary.
우리는 표준 ROUGE(Lin, 2004) 메트릭을 자동 메트릭으로 사용하며, 여기에는 ROUGE-1, ROUGE-2 및 ROUGE-L이 포함된다. 구현을 위해 Gliwa 등(2019)의 py-rouge 패키지 3을 스템밍과 함께 사용했다. 사실 정확도에 대한 추가 측정 지표로 ROUGE 점수 외에도 사실 정확도(FactCC)(Kryscinski et al., 2020)를 도입했다. FactCC 점수가 높을수록 시스템 요약이 참조 요약과 사실적으로 더 일치한다는 것을 의미한다.
2https://huggingface.co/facebook/bart-large-cnn 3https://pypi.org/project/py-rouge/

Table 2: Properties and statistics of dialog summarization datasets used in the experiments.
표 2: 실험에 사용된 대화 요약 데이터 세트의 속성 및 통계.
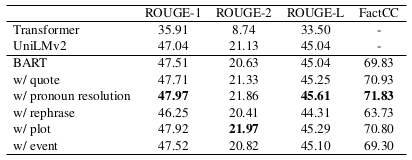
Table 3: Supervised finetuning result on DialogSum test split. The whole train split is used to finetune a Bart- large model. Baseline performance are taken from work of Chen et al. (2021)
표 3: DialogSum 테스트 분할에 대한 지도 파인튜닝 결과. 전체 훈련 분할은 Bart-대형 모델을 파인튜닝하는 데 사용된다. 기준 성능은 Chen 등(2021)의 연구에서 가져왔다.

Table 4: Zero-shot result on three datasets. We used a BART-large model finetuned on news summarization dataset CNN/DailyMail
표 4: 세 가지 데이터 세트에 대한 제로 샷 결과. 뉴스 요약 데이터 세트 CNN/DailyMail에 대해 파인튜닝된 BART 대규모 모델을 사용했다.
We refer readers to Chen et al. (2021) for base- lines in DialogSum dataset and Wu et al. (2021) for baselines in SAMSum dataset, with an exception of DialoGPT-Annotator Feng et al. (2021b). Similar to our model-based transfer methodology, it uses an external language model, i.e., DigloGPT (Zhang et al., 2020c), to annotate useful information for dialogue summarization, and use BART to finetune on the annotated dialogues.
독자들은 DialoGPT-Annotator Feng 외(2021b)를 제외한 DialogSum 데이터셋의 기준선에 대해서는 Chen 외(2021)를, SAMSum 데이터셋의 기준선에 대해서는 Wu 외(2021)를 참고하라. 모델 기반 전사 방법론과 유사하게 외부 언어 모델, 즉 DigloGPT(Zhang et al., 2020c)를 사용하여 대화 요약에 유용한 정보에 주석을 달고, BART를 사용하여 주석이 달린 대화에 대한 파인튜닝을 수행한다.
- Analysis on Results
For supervised results on the SAMSum dataset, using event narratives achieved better performance on all metrics compared with the BART model finetuned on vanilla dialogue inputs. The most salient improvement is on the FactCC score, indicating that adding narratives helps more with factual correctness. Compared with the state-of-art models, such as DialoGPT-Annotator, MV-BART, and CODS, our best-performing model reached comparable or even better performance on both ROUGE and FactCC scores. This empirical result proves the effectiveness of event narratives in the supervised setting. On DialogSum, pronoun resolution narratives performed better than other narrative methods and the BART baseline. One potential reason is that DialogSum only contains two-speaker conversations, therefore pronouns resolved by our rules are 100% correct.
SAMSum 데이터 세트에 대한 감독 결과, 이벤트 내러티브를 사용하면 바닐라 대화 입력으로 파인튜닝된 BART 모델에 비해 모든 지표에서 더 나은 성능을 달성했다. 내러티브를 추가하면 사실 정확도에 더 많은 도움이 된다는 것을 나타내는 FactCC 점수가 가장 눈에 띄게 개선되었다. DialoGPT-Annotator, MV-BART, CODS와 같은 최신 모델과 비교했을 때, 가장 우수한 성능을 보인 모델은 ROUGE와 FactCC 점수 모두에서 비슷하거나 더 나은 성능을 보였다. 이 경험적 결과는 감독 환경에서 이벤트 내러티브의 효과를 입증한다. DialogSum에서는 대명사 해결 내러티브가 다른 내러티브 방법 및 BART 기준선보다 더 나은 성능을 보였다. 한 가지 잠재적인 이유는 DialogSum에는 두 명의 화자 대화만 포함되어 있기 때문에 규칙에 의해 해결된 대명사는 100% 정확하다.
In the zero-shot evaluation, we can see that all narrative variants achieved significant improvement in FactCC scores. Overall, we conclude that the most robust method for zero-shot setting is event narratives. In other words, a news summarizer can benefit most when accessing the itemized events for dialogue summarization. We also notice that the benefit of including narratives is more salient in the zero-shot setting, where there is no in-domain annotated data to help the model to close the domain gap. We further showcase model outputs of our model in appendix A.3.
제로 샷 평가에서 모든 내러티브 변형이 FactCC 점수를 크게 향상시킨 것을 볼 수 있다. 전반적으로 제로 샷 설정을 위한 가장 강력한 방법은 이벤트 내러티브라는 결론을 내렸다. 즉, 뉴스 요약기는 대화 요약을 위해 항목별 이벤트에 접근할 때 가장 큰 이점을 얻을 수 있다. 또한 내러티브를 포함함으로써 얻을 수 있는 이점은 제로 샷 설정에서 더욱 두드러지는데, 이 설정에서는 도메인 내 주석이 달린 데이터가 없기 때문에 모델이 도메인 갭을 좁히는 데 도움이 된다. 부록 A.3에서 모델 결과물을 자세히 살펴볼 수 있다.
-
Related Work
To alleviate the domain mismatch and label scarcity, pre-training on dialogue or news domains (Qi et al., 2021; Zou et al., 2021; Khalifa et al., 2021; Zhu et al., 2020), multi-tasking (Liu et al., 2021a; Khalifa et al., 2021), and data argumentation (Chen and Yang, 2021) have shown to be effective for summarization. Other works focus on the structured information of dialogues and model the auxiliary input via graph attention network (Velicˇkovic´ et al., 2018) or the manipulation of transformer attention (Vaswani et al., 2017). The internal structured information includes speaker-utterance relationship (Lei et al., 2021), semantic slot (Zhao et al., 2021), topic (Zhao et al., 2020; Chen and Yang, 2020), and coreference (Liu et al., 2021b). And the external structured information includes commonsense graph from knowledge bases (Xiachong et al., 2021).
도메인 불일치 및 레이블 부족 문제를 완화하기 위해 대화 또는 뉴스 도메인에 대한 사전 학습(Qi 외, 2021; Zou 외, 2021; Khalifa 외, 2021; Zhu 외, 2020), 멀티태스킹(Liu 외, 2021a; Khal- ifa 외, 2021), 데이터 논증(Chen and Yang, 2021)이 요약에 효과적인 것으로 나타났다. 다른 연구들은 대화의 구조화된 정보에 초점을 맞추고 그래프 주의 네트워크(Velicˇkovic´ et al., 2018) 또는 변압기 주의 조작(Vaswani et al., 2017)을 통해 보조적 입력을 모델링한다. 내부 구조화된 정보에는 화자-발화 관계(Lei 외, 2021), 의미적 슬롯(Zhao 외, 2021), 주제(Zhao 외, 2020; Chen and Yang, 2020), 핵심 참조(Liu 외, 2021b) 등이 포함된다. 그리고 외부 구조화된 정보에는 지식 베이스의 상식 그래프가 포함된다(Xiachong et al., 2021).
Another line of work addresses the challenges of dialogue summarization by directly injecting knowledge into model input. For instance, Liu and Chen (2021) uses personal named entities to control the occurrence of speakers in the summary generation. Feng et al. (2021b) make use of Dialog- GPT (Zhang et al., 2020c) to annotate keywords, redundant utterance, and topic changes in the dialogue transcript. Wu et al. (2021) use external tools to annotate speaker intent and key phrases as a "sketch" of the dialogue. Our work falls in this category but differs from previous approaches as we attempt to incorporate external knowledge by directly narrating the dialogues in natural language.
또 다른 작업 라인은 모델 입력에 지식을 직접 주입하여 대화 요약의 문제를 해결한다. 예를 들어, Liu와 Chen(2021)은 개인 명명 엔티티를 사용하여 요약 생성에서 화자의 발생을 제어한다. (2021b)는 다이얼로그 트랜스크립트에서 키워드, 중복 발화, 주제 변경에 주석을 달기 위해 다이얼로그- GPT(Zhang et al., 2020c)를 사용한다. (2021)은 외부 도구를 사용하여 화자의 의도와 핵심 문구를 대화의 '스케치'로 주석을 달았다. 우리의 작업도 이 범주에 속하지만 자연어로 대화를 직접 서술하여 외부 지식을 통합하려고 시도한다는 점에서 이전 접근 방식과 다르다.
-
Conclusion
We propose a general framework to narrate a dialogue into a third-person description for dialogue summarization. We empirically compare different ways of narration and found that the proposed framework improves the performance, especially the factual correctness of the generated summary, for both supervised and zero-shot settings in three benchmark datasets. The improvement is most consistent when including the salient events in the dialogue as narrative. The resulting summarization model surpasses existing strong baselines on SAMSum and DialogSum datasets.
우리는 대화 요약을 위해 다이얼로그를 3인칭 서술로 나레이션하는 일반적인 프레임워크를 제안한다. 다양한 나레이션 방식을 경험적으로 비교한 결과, 제안된 프레임워크가 세 가지 벤치마크 데이터 세트에서 감독 설정과 제로샷 설정 모두에서 성능, 특히 생성된 요약의 사실 정확도를 향상시킨다는 사실을 발견했다. 이러한 개선은 대화의 주요 사건을 내러티브로 포함할 때 가장 일관되게 나타났다. 그 결과 요약 모델은 SAMSum 및 DialogSum 데이터 세트의 기존 강력한 기준선을 능가한다.
-
Limitations
We have not explored towards a principled way to combine different narratives to achieve better per formance, as well as the combination of narrating dialogues with other dialogue summarization techniques. We leave these directions to future work.
우리는 더 나은 성능을 달성하기 위해 서로 다른 내러티브를 결합하는 원칙적인 방법과 나레이션 대화와 다른 대화 요약 기술을 결합하는 방법을 탐구하지 않았다. 이러한 방향은 향후 연구에 맡긴다.
References
Jiaao Chen and Diyi Yang. 2020. Multi-view sequence- to-sequence models with conversational structure for abstractive dialogue summarization. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 4106– 4118, Online. Association for Computational Linguistics.
Jiaao Chen and Diyi Yang. 2021. Simple conversational data augmentation for semi-supervised abstrac- tive dialogue summarization. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 6605–6616, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
Yulong Chen, Yang Liu, Liang Chen, and Yue Zhang. 2021. DialogSum: A real-life scenario dialogue sum- marization dataset. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 5062–5074, Online. Association for Computa- tional Linguistics.
Alexander Fabbri, Faiaz Rahman, Imad Rizvi, Borui Wang, Haoran Li, Yashar Mehdad, and Dragomir Radev. 2021. ConvoSumm: Conversation summarization benchmark and improved abstractive summarization with argument mining. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 6866–6880, Online. Association for Computational Linguistics.
Xiachong Feng, Xiaocheng Feng, and Bing Qin. 2021a. A survey on dialogue summarization: Re cent advances and new frontiers. arXiv preprint arXiv:2107.03175.
Xiachong Feng, Xiaocheng Feng, Libo Qin, Bing Qin, and Ting Liu. 2021b. Language model as an annotator: Exploring DialoGPT for dialogue summarization. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 1479–1491, Online. Association for Computational Linguistics.
Bogdan Gliwa, Iwona Mochol, Maciej Biesek, and Aleksander Wawer. 2019. SAMSum corpus: A human- annotated dialogue dataset for abstractive summarization. In Proceedings of the 2nd Workshop on New Frontiers in Summarization, pages 70–79, Hong Kong, China. Association for Computational Linguis- tics.
Muhammad Khalifa, Miguel Ballesteros, and Kathleen McKeown. 2021. A bag of tricks for dialogue summarization. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 8014–8022, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
Wojciech Kryscinski, Bryan McCann, Caiming Xiong, and Richard Socher. 2020. Evaluating the factual consistency of abstractive text summarization. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 9332–9346, Online. Association for Computational Linguistics.
Yuejie Lei, Fujia Zheng, Yuanmeng Yan, Keqing He, and Weiran Xu. 2021. A finer-grain universal dia- logue semantic structures based model for abstractive dialogue summarization. In Findings of the Associ- ation for Computational Linguistics: EMNLP 2021, pages 1354–1364, Punta Cana, Dominican Republic. Association for Computational Linguistics.
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. 2020. BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7871–7880, Online. Association for Computational Linguistics.
Chin-Yew Lin. 2004. ROUGE: A package for automatic evaluation of summaries. In Text Summariza- tion Branches Out, pages 74–81, Barcelona, Spain. Association for Computational Linguistics.
Junpeng Liu, Yanyan Zou, Hainan Zhang, Hongshen Chen, Zhuoye Ding, Caixia Yuan, and Xiaojie Wang. 2021a. Topic-aware contrastive learning for abstractive dialogue summarization. In Findings of the Asso- ciation for Computational Linguistics: EMNLP 2021, pages 1229–1243, Punta Cana, Dominican Republic. Association for Computational Linguistics.
Zhengyuan Liu and Nancy Chen. 2021. Controllable neural dialogue summarization with personal named entity planning. In Proceedings of the 2021 Con- ference on Empirical Methods in Natural Language Processing, pages 92–106, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
Zhengyuan Liu, Ke Shi, and Nancy Chen. 2021b. Coreference-aware dialogue summarization. In Pro- ceedings of the 22nd Annual Meeting of the Special Interest Group on Discourse and Dialogue, pages 509–519, Singapore and Online. Association for Computational Linguistics.
Laiba Mehnaz, Debanjan Mahata, Rakesh Gosangi, Uma Sushmitha Gunturi, Riya Jain, Gauri Gupta, Amardeep Kumar, Isabelle G. Lee, Anish Acharya, and Rajiv Ratn Shah. 2021. GupShup: Summarizing open-domain code-switched conversations. In Pro- ceedings of the 2021 Conference on Empirical Meth- ods in Natural Language Processing, pages 6177– 6192, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
Amita Misra, Pranav Anand, Jean E. Fox Tree, and Marilyn Walker. 2015. Using summarization to dis- cover argument facets in online idealogical dialog. In Proceedings of the 2015 Conference of the North American Chapter of the Association for Computa- tional Linguistics: Human Language Technologies, pages 430–440, Denver, Colorado. Association for Computational Linguistics.
Ramesh Nallapati, Bowen Zhou, Cicero dos Santos, Çag˘lar Gu°lçehre, and Bing Xiang. 2016. Abstrac- tive text summarization using sequence-to-sequence RNNs and beyond. In Proceedings of The 20th SIGNLL Conference on Computational Natural Lan- guage Learning, pages 280–290, Berlin, Germany. Association for Computational Linguistics.
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Car- roll L Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow in- structions with human feedback. arXiv preprint arXiv:2203.02155.
MengNan Qi, Hao Liu, YuZhuo Fu, and Ting Liu. 2021. Improving abstractive dialogue summarization with hierarchical pre-training and topic segment. In Find- ings of the Association for Computational Linguis- tics: EMNLP 2021, pages 1121–1130, Punta Cana, Dominican Republic. Association for Computational Linguistics.
Colin Raffel, Noam Shazeer, Adam Roberts, Kather- ine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21(140):1–67.
Abigail See, Peter J. Liu, and Christopher D. Manning. 2017. Get to the point: Summarization with pointer- generator networks. In Proceedings of the 55th An- nual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1073– 1083, Vancouver, Canada. Association for Computa- tional Linguistics.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information Pro- cessing Systems, volume 30. Curran Associates, Inc.
Petar Velicˇkovic´, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Liò, and Yoshua Bengio. 2018. Graph attention networks. In International Conference on Learning Representations.
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pier- ric Cistac, Tim Rault, Remi Louf, Morgan Funtow- icz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander Rush. 2020. Trans- formers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 38–45, Online. Association for Computational Linguistics.
Chien-Sheng Wu, Linqing Liu, Wenhao Liu, Pontus Stenetorp, and Caiming Xiong. 2021. Controllable abstractive dialogue summarization with sketch su- pervision. In Findings of the Association for Com- putational Linguistics: ACL-IJCNLP 2021, pages 5108–5122, Online. Association for Computational Linguistics.
Feng Xiachong, Feng Xiaocheng, and Qin Bing. 2021. Incorporating commonsense knowledge into abstrac- tive dialogue summarization via heterogeneous graph
networks. In Proceedings of the 20th Chinese National Conference on Computational Linguistics, pages 964–975, Huhhot, China. Chinese Information Processing Society of China.
Jingqing Zhang, Yao Zhao, Mohammad Saleh, and Peter Liu. 2020a. PEGASUS: Pre-training with ex- tracted gap-sentences for abstractive summarization. In Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 11328–11339. PMLR.
Jingqing Zhang, Yao Zhao, Mohammad Saleh, and Peter Liu. 2020b. Pegasus: Pre-training with extracted gap-sentences for abstractive summarization. In In- ternational Conference on Machine Learning, pages 11328–11339. PMLR.
Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, and Bill Dolan. 2020c. DIALOGPT : Large- scale generative pre-training for conversational response generation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, pages 270–278, Online. Association for Computational Linguistics.
Lulu Zhao, Weiran Xu, and Jun Guo. 2020. Improving abstractive dialogue summarization with graph structures and topic words. In Proceedings of the 28th International Conference on Computational Lin- guistics, pages 437–449, Barcelona, Spain (Online). International Committee on Computational Linguis- tics.
Lulu Zhao, Weihao Zeng, Weiran Xu, and Jun Guo. 2021. Give the truth: Incorporate semantic slot into abstractive dialogue summarization. In Find- ings of the Association for Computational Linguis- tics: EMNLP 2021, pages 2435–2446, Punta Cana, Dominican Republic. Association for Computational Linguistics.
Ming Zhong, Da Yin, Tao Yu, Ahmad Zaidi, Mutethia Mutuma, Rahul Jha, Ahmed Hassan Awadallah, Asli Celikyilmaz, Yang Liu, Xipeng Qiu, and Dragomir Radev. 2021. QMSum: A new benchmark for query- based multi-domain meeting summarization. In Pro- ceedings of the 2021 Conference of the North Amer- ican Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 5905–5921, Online. Association for Computational Linguistics.
Chenguang Zhu, Yang Liu, Jie Mei, and Michael Zeng. 2021a. MediaSum: A large-scale media interview dataset for dialogue summarization. In Proceedings of the 2021 Conference of the North American Chap- ter of the Association for Computational Linguistics: Human Language Technologies, pages 5927–5934, Online. Association for Computational Linguistics.
Chenguang Zhu, Ruochen Xu, Michael Zeng, and Xue- dong Huang. 2020. A hierarchical network for ab- stractive meeting summarization with cross-domain pre-training. In Findings of the Association for Com- putational Linguistics: EMNLP 2020, pages 194– 203, Online. Association for Computational Linguis- tics.
Chenguang Zhu, Ziyi Yang, Robert Gmyr, Michael Zeng, and Xuedong Huang. 2021b. Leveraging lead bias for zero-shot abstractive news summarization. In Proceedings of the 44th International ACM SI- GIR Conference on Research and Development in Information Retrieval, pages 1462–1471.
Yicheng Zou, Bolin Zhu, Xingwu Hu, Tao Gui, and Qi Zhang. 2021. Low-resource dialogue summariza- tion with domain-agnostic multi-source pre-training. In Proceedings of the 2021 Conference on Empiri- cal Methods in Natural Language Processing, pages 80–91, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
-
Appendix
The total number of steps was set to 8000 with lin- ear learning scheduler peaked at step 800. The learning rate is set to be 3e 5 and the batch size is set to be 8, with a gradient accumulation of 4 steps. We tuned a weight decay coefficient at from [0.1, 0.01, 0.001] and a label smoothing fac- tor at from [0.0, 0.1] using grid search and selected weight decay to be 0.001 and label smoothing fac- tor to be 0.1 on the validation set performance of SAMSum dataset with its original dialogue input. The beam size is set to 4 for decoding. For both finetuning and inference, we used the pipeline from Hugging Face (Wolf et al., 2020). 4 All experi- ments are done on a cluster with 8 NVIDIA V100 32GB GPUs.
총 단계 수는 8000으로 설정되었으며 선형 귀 학습 스케줄러는 800단계에서 피크가 발생했다. 학습 속도는 3e 5로 설정하고 배치 크기는 8로 설정했으며 그라데이션 누적은 4단계로 설정했다. 그리드 검색을 사용하여 가중치 감쇠 계수를 [0.1, 0.01, 0.001]에서, 라벨 평활화 팩터를 [0.0, 0.1]에서 조정하고, 원래 대화 입력이 있는 SAMSum 데이터 세트의 검증 세트 성능에서 가중치 감쇠를 0.001로, 라벨 평활화 팩터를 0.1로 선택했다. 디코딩을 위해 빔 크기를 4로 설정했다. 파인튜닝과 추론 모두에 Hugging Face(Wolf et al., 2020)의 파이프라인을 사용했다. 4 모든 실험은 8개의 NVIDIA V100 32GB GPU가 장착된 클러스터에서 수행되었다.
- Pronoun Resolution
For pronoun identification, we used the part-of- speech pipeline from spaCy package 5. The rule of replacing pronouns with speaker names is specified in table 5.
대명사 식별을 위해 spaCy 패키지 5의 품사 파이프라인을 사용했다. 대명사를 화자 이름으로 대체하는 규칙은 표 5에 명시되어 있다.
- Rephrase Generation
For rephrase generation, we first convert dialogue to narrative equivalence with InstructGPT. Secondly, we filter the generated narratives based on several criteria to make sure that resulting parallel corpus has a high quality. Specifically, we compute the length of the narratives in word and divide it by the length of the dialogue. If the ratio is smaller than a threshold, the narrative tends to lose some key information of the dialogue and is therefore discarded. In our experiment, we manually inspect some of the generated narratives and set this thresh- old to be 1.2. Similarly, we also set a upper bound for this ratio to be 5, preventing the narrative to be too verbose when compared with the original dialog. In filtering process, we found the upper bound is very rarely reached. At last, we use the filtered parallel corpus from SAMSum dataset to finetune a BART-Large model and use it to convert dialogue in the all downstream datasets.
고쳐말하기rephrase 생성을 위해, 먼저 대화를 InstructGPT로 내러티브 동등성으로 변환한다. 두 번째로, 생성된 내러티브를 몇 가지 기준에 따라 필터링하여 병렬 코퍼스의 품질이 높은지 확인한다. 구체적으로는 내러티브의 단어 길이를 계산하고 이를 대화의 길이로 나눈다. 이 비율이 임계값보다 작으면 내러티브는 대화의 일부 핵심 정보를 잃는 경향이 있으므로 버려진다. 실험에서는 생성된 내러티브 중 일부를 수동으로 검사하여 이 임계값을 1.2로 설정했다. 마찬가지로 이 비율의 상한선도 5로 설정하여 원본 대화와 비교했을 때 내러티브가 너무 장황해지는 것을 방지했다. 필터링 과정에서 상한값에 도달하는 경우가 매우 드물다는 사실을 발견했다. 마지막으로 SAMSum 데이터 세트의 필터링된 병렬 말뭉치를 사용하여 BART-Large 모델을 파인튜닝하고 모든 다운스트림 데이터 세트의 대화를 변환하는 데 사용했다.
- FactCC Modification
The original FactCC takes the source text and the claim as inputs to verify whether the claim is supported by the source text. For dialogue summa- rization, the input dialogue text has a domain gap between the training data of FactCC model, there- fore, we input the reference summary instead in order to determine if the system predicted sum- mary is well supported by the reference summary. Similarly, we also input the system and reference summary in the reverse order and averaged the two scores for each testing example.
원본 FactCC는 원본 텍스트와 클레임을 입력으로 받아 클레임이 원본 텍스트에서 지원되는지 여부를 확인한다. 대화 요약의 경우, 입력된 대화 텍스트는 FactCC 모델의 학습 데이터와 도메인 갭이 존재하므로 시스템 예측 요약이 참조 요약에 의해 잘 지원되는지 판단하기 위해 참조 요약을 대신 입력한다. 마찬가지로 시스템과 참조 요약을 역순으로 입력한 후 각 테스트 예제에 대해 두 점수의 평균을 구했다.
4Source code from https://github.com/ huggingface/transformers/tree/v4.9.1/ examples/pytorch/summarization

Table 5: Resolution mapping of first and sec- ond pronouns to speaker names. Placeholder
<speaker>represents the speaker’s name of the current turn. <prev_speaker>represents the speaker’s name of the previous turn. If the current turn is the first turn, then <prev_speaker>is the current speaker.
표 5: 첫 번째 대명사와 두 번째 대명사의 화자 이름에 대한 해상도 매핑. 자리 표시자
<스피커>는 현재 턴의 발표자 이름을 나타낸다. <prev_speaker>는 이전 턴의 발표자 이름을 나타낸다. 현재 턴이 첫 번째 턴인 경우 <prev_speaker>가 현재 발표자이다.
- Example Model Outputs
We show the example outputs from baseline BART model and narrative model with events in figures 2, 3, and 4 for SAMSum, DialogSum and ADSC dataset respectively. We can see that the event narratives helps BART model to generate more detailed summaries than using the dialogue input alone. The quality improvement is significant in the zero-shot setting, where BART w/ event could still generate high-quality summaries, the vanilla zero- shot model tends to copy turns from the dialogue or produce hallucinations.
그림 2, 3, 4에는 각각 SAMSum, DialogSum, ADSC 데이터 세트에 대한 기본 BART 모델과 내러티브 모델에서 이벤트가 포함된 예제 출력이 나와 있다. 이벤트 내러티브가 대화 입력만 사용할 때보다 BART 모델이 더 자세한 요약을 생성하는 데 도움이 된다는 것을 알 수 있다. 제로 샷 설정에서 품질 개선이 두드러지는데, 이벤트가 포함된 BART는 여전히 고품질 요약을 생성할 수 있는 반면, 바닐라 제로 샷 모델은 대화의 턴을 복사하거나 환각을 생성하는 경향이 있다.
Wanda asking Gina to help her plan a party Gina agreeing to help Wanda making a list of things she needs for the party Gina agreeing to go grocery shopping with Wanda Wanda: Let's make a party! Gina: Why? Wanda: beacuse. I want some fun! Gina: ok, what do u need? Wanda: 1st I need too make a list Gina: noted and then? Wanda: well, could u take yours father car and go do groceries with me? Gina: don't know if he'll agree Wanda: I know, but u can ask :) Gina: I'll try but theres no promisess Wanda: I know, u r the best! Gina: When u wanna go Wanda: Friday? Gina: ok, I'll ask |
|
| BART FT | Wanda wants to make a party. She wants Gina to go shopping with her on Friday. |
BART FT w\ event |
Wanda wants to make a party. Gina will help her with that. She will go shopping with Wanda on Friday. |
| BART ZS | Wanda: Let's make a party! "I want some fun!" "I'll try but theres no promisess" |
BART ZS w\ event |
Wanda asks Gina to help her plan a party. Gina agrees to help. Wanda makes a list of things she needs for the party. |
Reference |
Wanda wants to throw a party. She asks Gina to borrow her father's car and go do groceries together. They set the date for Friday. |
Figure 2: Example input and output on SAMSum dataset of BART with event narratives (in blue color). "FT" means finetuned model outputs, and "ZS" means zero-shot model outputs.
그림 2: 이벤트 내러티브(파란색)가 있는 BART의 SAMSum 데이터 세트에 대한 입력 및 출력 예시. "FT"는 파인튜닝된 모델 출력을 의미하며, "ZS"는 제로 샷 모델 출력을 의미한다.
| Person1 calls Person2 Person1 talks to Person2 about her application and grades Person1 asks Person2 if she is interested in college sports Person2 tells Person1 about her basketball skills Person2 tells Person1 about her volleyball skills Person1 thanks Person2 Person1 ends the conversation Person1: Hi, can I talk to Person2, please? Person2: This is Person2. Who's that speaking? Person1: Hi, Person2. This is Greg Sonders from Brown College. Person2: How can I help you, Mr. Sonders? Person1: Well, your papers mention your impressive grade point average. And your test scores meet our admission standards. But we'd like to know if you'd be interested in college sports. Person2: Definitely! I wrote on my application that I played high school basketball. In fact, I hold my school's all time record for points scored in a game. Person1: Great! Do you play any other sports? Person2: I also play volleyball. Person1: Great! Well, you've certainly made an impression on us. We'll let you know our decision soon. Person2: Thanks! Person1: Goodbye. |
|
BART FT |
Greg Sonders from Brown College calls Mary to ask her if she would be interested in college sports. |
BART FT w\ event |
Greg Sonders from Brown College calls Mary and asks her if she's interested in college sports. Mary tells him she played high school basketball and volleyball. Greg will inform her of the decision soon. |
BART ZS |
Greg Sonders applied to Brown College. He wrote on his application that he played high school basketball. He also wrote that he held his school's all time record for points scored in a game. The college decided to interview him for the sports program. He was accepted to Brown. |
BART ZS w\ event |
Person1 calls Person2 about her application and grades. Person1 asks Person2 if she is interested in college sports. |
Reference |
Greg Sonders from Brown College calls the applicant Mary to ask whether she is interested in college sports and will make a further decision later. |
Figure 3: Example input and output on DialogSum dataset of BART with event narratives (in blue color). "FT" means finetuned model outputs, and "ZS" means zero-shot model outputs.
그림 3: 이벤트 내러티브(파란색)가 있는 BART의 DialogSum 데이터 세트에 대한 입력 및 출력 예시(파란색). "FT"는 파인튜닝된 모델 출력을 의미하며, "ZS"는 제로 샷 모델 출력을 의미한다.
S1 apologizes for getting something bassackwards S2 tells S1 that their argument about same-sex marriage is also bassackwards S1 concedes that same-sex marriage does not have a negative financial impact S2 tells S1 that they were hoping for a more forthright concession S1 tells S2 that they are not one of those who feels the need to impose their morality on others S1 tells S2 that they are willing to let society determine its own limits S1: My apologizies. I read it hastily and got it completely bassackwards. The CBO estimate in your link did, indeed, say that the result would be up to ~ $1 Billion surplus. S2: So you also recognize that your argument that same-sex marriage does not benefit society is also \" bassackwards \"? Finally! Some progress. Remember... this thread is supposed to be about fiscal concerns. S1: I have conceded that it doesn't have the negative financial impact that I thought it would. That WAS the purpose for my attempting to have a civil debate on what I thought the issues were. I'd like to move past the fiscal concerns and onto the moral and health concerns if we can continue to do you with civility. S2: Gosh, I love a good typo! In any case, I suppose a tepid concession is all we can expect. S1: Good catch. And you were hoping for ? S2: A forthright concession. Any maybe some discussion of how same-sex marriage benefits society in practical ways. Instead, we're off to your safe ground of \" morality \". Safe, not because you're right, but because morality IS relative and IS subjective. S1: I was hoping that you'd be telling me the benefits, not vice versa. But you forget, I'm not one of \" those \" who feels the need to impose my morality on everyone else. I'm more than willing to let society as a whole determine its own limits. While I'm a staunch defender of the Constitution ( as written, not as interpreted ), I'm way more flexible with public determined acceptable standards of behavior. I'll even cut my grass so that it is the same level as my neighbors. :) |
|
BART ZS |
S1: My apologizies. I read it hastily and got it completely bassackwards. CBO estimate in your link did, indeed, say that the result would be up to ~ $1 Billion surplus. I'd like to move past the fiscal concerns and onto the moral and health concerns if we can continue to do you with civility. |
BART ZS w\ event |
S1 concedes that same-sex marriage does not have a negative financial impact. S2 tells S1 that they were hoping for a more forthright concession. S1 tells S2 that they are willing to let society determine its own limits. |
Reference |
Two people are discussing the financial effect of allowing for gay marriage. S1 originally believed allowing gay marriage would have a negative financial impact on society as a whole. He has since amended that belief due to information found in the CBO. His reasoning for still supporting the ban on gay marriage has changed over to moral and health related concerns. Although S2 is pleased with the concession of S1's former opinion, he believes jumping to the moral high ground still ignores other issues. He would like to discuss the positive impact that allowing gay marriage would have on the country practically. S1 advises while he is a defender of the Constitution, he does feel society should decide. |
Figure 4: Example input and output on ADSC dataset of BART with event narratives (in blue color). "ZS" means zero-shot model outputs.
그림 4: 이벤트 내러티브(파란색)가 있는 BART의 ADSC 데이터 세트에 대한 입력 및 출력 예시(파란색). "ZS"는 제로 샷 모델 출력을 의미한다.
'인터넷/모바일 > 머신러닝' 카테고리의 다른 글
| (논문번역) chain-of-verification reduces hallucination in large language models (4) | 2023.09.27 |
|---|---|
| 논문번역) Simple Conversational Data Augmentationfor Semi-supervised Abstractive Conversation Summarization (1) | 2023.09.27 |
| 우바부가] 모델 로딩 시에 with open(self.vocab_file, "rb") as f: 에러 (0) | 2023.09.21 |
| (논문번역) Summarization is (Almost) Dead, Xiao Pu, et. (0) | 2023.09.21 |
| nvidia docker 재설치 (0) | 2023.05.10 |


