3일 전에 올라온 따끈따끈한 논문임.
사실 관계만 기억하면 되는 아주 쉬운(?) 논문이라서 수정 같은거 안 함. DeepL 이용해서 번역한거 그대로 올림.
이 글에 대한 모든 권리는 원문 저자인 Xiao Pu, Mingqi Gao, Xiaojun Wan에게 있음.
###########
원문 : https://arxiv.org/pdf/2309.09558.pdf
Summarization is (Almost) Dead
Xiao Pu ∗ , Mingqi Gao ∗ , Xiaojun Wan
Wangxuan Institute of Computer Technology, Peking University
puxiao@stu.pku.edu.cn
{gaomingqi, wanxiaojun}@pku.edu.cn
Abstract
How well can large language models (LLMs) generate summaries? We develop new datasets and conduct human evaluation experiments to evaluate the zero-shot generation capability of LLMs across five distinct summarization tasks. Our findings indicate a clear preference among human evaluators for LLM-generated summaries over human-written summaries and summaries generated by fine-tuned models. Specifically, LLM-generated summaries ex- hibit better factual consistency and fewer in- stances of extrinsic hallucinations. Due to the satisfactory performance of LLMs in summa- rization tasks (even surpassing the benchmark of reference summaries), we believe that most conventional works in the field of text summa- rization are no longer necessary in the era of LLMs. However, we recognize that there are still some directions worth exploring, such as the creation of novel datasets with higher qual- ity and more reliable evaluation methods.
LLM(대형 언어 모델)은 요약을 얼마나 잘 생성할 수 있을까? 우리는 새로운 데이터 세트를 개발하고 인간 평가 실험을 수행하여 5가지 개별 요약 작업에 걸쳐 LLM의 제로 샷 생성 기능을 평가한다. 우리의 연구 결과는 사람이 작성한 요약과 파인튜닝된 모델에 의해 생성된 요약보다 LLM에서 생성된 요약을 평가자 사이에서 분명히 선호한다는 것을 나타낸다. 특히, LLM에서 생성된 요약은 사실적 일관성이 더 뛰어나고 외부 환각 사례가 더 적다. 요약 작업에서 LLM의 만족스러운 성능(참조 요약 벤치마크를 능가함)으로 인해 LLM 시대에는 텍스트 요약 분야의 대부분의 기존 작업이 더 이상 필요하지 않다고 생각한다. 그러나 우리는 더 높은 품질과 더 신뢰할 수 있는 평가 방법을 갖춘 새로운 데이터세트를 생성하는 등 탐구할 가치가 있는 몇 가지 방향이 여전히 있다는 것을 알고 있다.
1. Abstract
Text summarization, a natural language generation (NLG) task, aims to compress extensive source materials into brief summaries, including diverse content such as news articles, source codes, and cross-lingual text. Traditional methods used fine- tuning techniques on specific datasets (Lewis et al., 2019; Raffel et al., 2020; Zhang et al., 2020; Wang et al., 2021; Xue et al., 2021; Wang et al., 2022), but the emergence of large language models (LLMs) (Chung et al., 2022; Zhang et al., 2022; Touvron et al., 2023; Ouyang et al., 2022; OpenAI, 2023) has shifted the focus to their promising zero-shot generation capability.
자연어 생성(NLG) 작업인 텍스트 요약은 뉴스 기사, 소스 코드, 다국어 텍스트 등 다양한 콘텐츠를 포함한 방대한 소스 자료를 간단한 요약으로 압축하는 것을 목표로 한다. 기존에는 특정 데이터 세트에 대한 파인튜닝 기법을 사용했지만(Lewis et al., 2019; Raffel et al., 2020; Zhang et al., 2020; Wang et al., 2021; Xue et al., 2021; Wang et al, 2022), 그러나 대규모 언어 모델(LLM)의 등장(Chung et al., 2022; Zhang et al., 2022; Touvron et al., 2023; Ouyang et al., 2022; OpenAI, 2023)으로 인해 유망한 제로 샷 생성 기능에 초점이 맞춰졌다.
In an exploration of this potential, we evalu- ated the performance of LLMs on various sum- marization tasks—single-news, multi-news, dia- logue, source codes, and cross-lingual summariza- tion—using human-generated evaluation datasets.
Our quantitative and qualitative comparisons be- tween LLM-generated summaries, human-written summaries, and summaries generated by fine-tuned models revealed that LLM summaries are sig- nificantly preferred by the human evaluators, which also demonstrate higher factuality.
이러한 잠재력을 탐구하기 위해 사람이 생성한 평가 데이터셋을 사용하여 단일 뉴스, 다중 뉴스, 다이아로그, 소스 코드, 다국어 요약 등 다양한 요약 작업에 대한 LLM의 성능을 평가했다.
LLM으로 생성된 요약, 사람이 작성한 요약, 파인튜닝된 모델로 생성된 요약을 정량적, 정성적으로 비교한 결과, 인간 평가자들이 LLM 요약을 훨씬 더 선호하며 사실성 또한 더 높은 것으로 나타났다.
Given the impressive performance of LLMs across these tasks, we question the need for fur- ther refinement of text summarization models with higher metric scores. After sampling and exam- ining 100 summarization-related papers published in ACL, EMNLP, NAACL, and COLING in the past 3 years, we find that the main contribution of about 70% papers was to propose a summa- rization approach and validate its effectiveness on standard datasets. As such, we provocatively assert that " Summarization is (almost) Dead." Nonethe- less, we acknowledge existing challenges in the field such as the need for high-quality reference datasets, application-oriented approaches, and im- proved evaluation methods.
이러한 작업에서 LLM의 인상적인 성능을 고려할 때, 우리는 더 높은 지표 점수를 가진 텍스트 요약 모델을 더욱 세밀하게 개선할 필요성에 의문을 제기한다. 지난 3년 동안 ACL, EMNLP, NAACL, COLING에 발표된 요약 관련 논문 100편을 샘플링하여 조사한 결과, 약 70%의 논문이 요약 접근법을 제안하고 표준 데이터세트에서 그 효과를 검증하는 데 주로 기여한 것으로 나타났다. 따라서 우리는 "요약은 (거의) 죽었다"고 도발적으로 주장한다. 그럼에도 불구하고 고품질 참조 데이터 세트의 필요성, 애플리케이션 지향 접근 방식, 검증된 평가 방법 등 이 분야의 기존 과제를 인정한다.
2. Experimental Settings
In this section, we provide an overview of the datasets and models used for human evaluation, as well as the experimental process and details.
2.1 Datasets
To ensure that the large language model has not "seen" the data during training, we use the lat- est data to build the datasets specifically for hu- man evaluation in each summarization task.1 Each dataset consists of 50 samples.
In conducting single-news, multi-news, and dialogue summarization tasks, our methodology emulates the dataset construction approaches utilized by CNN/DailyMail (See et al., 2017; Hermann et al., 2015), Multi-News (Fabbri et al., 2019), and Mediasum (Zhu et al., 2021), respectively, to build the datasets for our experiments. The sources for the data remain consistent with the original datasets, such as the DailyMail website, yet are the latest. For the cross-lingual summarization task, our strategy aligns with Zhu et al. (2019) approach, which entails translating reference summaries in our single-news dataset from English to Chinese using Google Translate, followed by a post-editing process. 2 In relation to code summarization, we adopt Bahrami et al. (2021)’s methodology to formulate a dataset, the source documents of which are Go language programs.
대규모 언어 모델이 훈련 중에 데이터를 "보지" 못하도록 하기 위해 최신 데이터를 사용하여 각 요약 작업에서 인간 평가를 위한 데이터셋을 구축한다.1 각 데이터셋은 50개의 샘플로 구성된다.
단일 뉴스, 다중 뉴스, 대화 요약 작업을 수행할 때, 우리의 방법론은 실험을 위한 데이터셋을 구축하기 위해 각각 CNN/DailyMail (See 외., 2017; Hermann 외., 2015), 다중 뉴스(Fabbri 외., 2019), 미디어섬(Zhu 외., 2021)에서 사용하는 데이터셋 구성 접근법을 모방한다. 데이터의 출처는 데일리메일 웹사이트와 같은 원본 데이터 세트와 일관성을 유지하면서도 가장 최신의 것이다. 언어 간 요약 작업의 경우, 단일 뉴스 데이터 세트의 참조 요약을 Google 번역기를 사용하여 영어에서 중국어로 번역한 후 사후 편집 과정을 거치는 Zhu 등(2019)의 접근 방식과 일치한다. 2 코드 요약과 관련하여, 우리는 바둑 언어 프로그램의 소스 문서인 데이터 세트를 모사하기 위해 Bahrami 등(2021)의 방법론을 채택한다.

Figure 1: Pairwise winning rates (%) between different systems across 5 tasks. Each data point represents the proportion of times System M (horizontal axis) is preferred over System N (vertical axis) in the comparisons. Red indicates a winning rate greater than 50%, indicating a preference for System M, while blue represents a winning rate less than 50%, indicating a preference for System N, with darker colors indicating the greater difference in winning rates between the two systems.We find that LLMs are highly preferred by human evaluators.
그림 1: 5개 작업에서 서로 다른 시스템 간의 쌍별 승률(%). 각 데이터 포인트는 비교에서 시스템 M(가로축)이 시스템 N(세로축)보다 선호된 횟수의 비율을 나타낸다. 빨간색은 50% 이상의 승률을 나타내며 시스템 M에 대한 선호도를 나타내고 파란색은 50% 미만의 승률을 나타내며 시스템 N에 대한 선호도를 나타내며 색상이 진할수록 두 시스템 간의 승률 차이가 크다는 것을 의미하며, 인간 평가자들이 LLM을 매우 선호한다는 것을 알 수 있다.
2.2. Models
For each task, we choose GPT-3(text-davinci-003) (Brown et al., 2020; Ouyang et al., 2022), GPT 3.5 and GPT-4 (OpenAI, 2023) as representatives of LLMs. For each summarization task, we ad- ditionally utilize 1-2 smaller models, previously fine-tuned on a dataset in this specific task. Pre- cisely, we employ BART (Lewis et al., 2019) and T5 (Raffel et al., 2020) for single-news task, Pega- sus (Zhang et al., 2020) and BART for multi-news task, T5 and BART for Dialogue task, MT5 (Xue et al., 2021) and MBART (Wang et al., 2022) for cross-lingual task and Codet5 (Wang et al., 2021) for source code task.
각 과제에 대해 GPT-3(text-davinci-003)(Brown et al., 2020; Ouyang et al., 2022), GPT-3.5 및 GPT-4 (OpenAI, 2023)를 LLM의 대표로 선택한다. 각 요약 작업에 대해, 우리는 이 특정 작업의 데이터 세트에 대해 이전에 파인튜닝된 1-2개의 더 작은 모델을 추가로 활용한다. 예를 들어, 단일 뉴스 태스크에는 BART(Lewis et al., 2019)와 T5(Raffel et al., 2020), 다중 뉴스 태스크에는 Pega- sus(Zhang et al., 2020)와 BART, 대화 태스크에는 T5와 BART, 언어 간 태스크에는 MT5(Xue et al., 2021)와 MBART(Wang et al., 2022), 소스 코드 태스크에는 Codet5(Wang et al., 2021)를 사용했다.
2.3 Experimental process and details
We conduct human evaluation experiments to an- notate the different types of summaries for each of five tasks. For each task, we hire two annotators 3, and each annotator is assigned to complete all 50 questions of a single task. For each question, they are presented with a source article and sum- maries from all summarization systems selected in this task. They are then asked to compare the sum- maries pairwise. If there are a total of n systems in the task, each annotator will need to make C2 com- parisons for one question. We calculate the overall Cohen’s kappa coefficient (Cohen, 1968) and find that the inter-annotator agreement is acceptable, with a coefficient of 0.558.
다섯 가지 과제 각각에 대해 서로 다른 유형의 요약본을 작성하는 인간 평가 실험을 실시했다. 각 과제마다 두 명의 주석가3를 고용하고, 각 주석가는 단일 과제의 50개 질문을 모두 완료하도록 배정받는다. 각 문제마다 이 작업에서 선택한 모든 요약 시스템의 원본 기사와 요약이 제시된다. 그런 다음 두 요약의 합을 쌍으로 비교하도록 요청받는다. 과제에 총 n개의 시스템이 있는 경우 각 주석자는 하나의 질문에 대해 C2 콤파리온을 만들어야 한다. 전체 Cohen의 카파 계수(Cohen, 1968)를 계산한 결과, 0.558의 계수로 주석자 간 합의가 수용 가능한 수준이라는 것을 알 수 있다.

Table 1: The number of hallucinations (sentence-level) found in GPT-4 and human-written summaries. We highlight the figures which is significantly large.
표 1: GPT-4 및 사람이 작성한 요약에서 발견된 환각 수(문장 수준). 우리는 상당히 큰 수치를 강조한다.
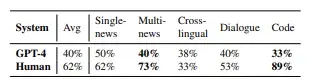
Table 2: The proportion of extrinsic hallucinations in GPT-4 and human-written summaries.
표 2: GPT-4 및 사람이 작성한 요약에서 외적 환각의 비율.
3. Experiment Results
3.1 Experiment 1: Comparing the overall quality of summaries
In this experiment, we engage human evaluators to compare the overall quality of different summaries. Then we compute WinRateN , which represents the proportion of times system M is preferred by human evaluators when comparing it with system
N. By comparing the pairwise winning rates among different systems, we can gain insights into the relative overall quality of the systems. Surprisingly, as depicted in Figure 1, summaries generated by the LLMs consistently outperform both human and summaries generated by fine-tuned models across all tasks.
This raises the question of why LLMs are able to outperform human-written summaries, which are traditionally regarded as flawless and oracle. Moreover, it prompts us to examine the specific limitations of human-written references. Our initial observations suggest that LLM-generated sum- maries exhibit high fluency and coherence. How- ever, the comparative factual consistency between LLM summaries and human-written ones remains uncertain. Consequently, our next experiment fo- cuses on exploring the factual consistency aspect.
이 실험에서는 인간 평가자를 참여시켜 다양한 요약의 전반적인 품질을 비교한다. 그런 다음 인간 평가자가 시스템 M을 시스템 N과 비교할 때 시스템 M이 선호되는 비율을 나타내는 WinRateN을 계산한다.
N. 서로 다른 시스템 간의 쌍별 승률을 비교함으로써 시스템의 상대적인 전반적인 품질에 대한 인사이트를 얻을 수 있다. 놀랍게도 그림 1에서 볼 수 있듯이, LLM이 생성한 요약은 모든 작업에서 사람이 생성한 요약과 세밀하게 조정된 모델이 생성한 요약 모두에서 일관되게 더 나은 성능을 보였다.
이는 전통적으로 완벽하고 정확하다고 여겨지는 사람이 작성한 요약을 LLM이 능가할 수 있는 이유에 대한 의문을 제기한다. 또한 사람이 작성한 참조의 구체적인 한계를 살펴보도록 유도한다. 우리의 초기 관찰에 따르면 LLM으로 생성된 요약은 유창성과 일관성이 높은 것으로 나타났다. 그러나 LLM 요약과 사람이 작성한 요약 간의 비교 사실적 일관성은 여전히 불확실하다. 따라서 다음 실험에서는 사실적 일관성 측면을 탐구하는 데 초점을 맞춘다.
3.2 Experiment 2: Comparing the factual consistency of summaries
3.2 실험 2: 요약의 사실적 일관성 비교하기
We further recruit annotators to identify sentence- level hallucinations in the human- and LLM- generated summaries, allowing us to compare their levels of factual consistency. Given the significant cost of annotation, we select GPT-4 as a repre- sentative LLM. As depicted in Table 1, human- written reference summaries exhibit either an equal or higher number of hallunications compared to GPT-4 summaries. In specific tasks such as multi- news and code summarization, human-written sum- maries exhibit notably inferior factual consistency. To gain a deeper understanding of this observed phenomenon, we further investigate the types of these factual errors. Following Maynez et al. (2020) we divide all hallucinations into two categories: in- trinsic and extrinsic hallucinations. Intrinsic hal- lucinations refer to inconsistencies between the factual information in the summary and the source text, while extrinsic hallucinations occur when the summary includes certain factual information that is not present in the source text.
By analyzing the proportion of intrinsic and extrinsic hallucinations in both human-written and GPT-4 summaries, as shown in Table 2, we dis- cover a notably higher occurrence of extrinsic hallucinations in tasks where human-written summaries demonstrate poor factual consis- tency, e.g., multi-news and code. Howerver, where there is little difference in factual consistency be- tween human and GPT-4, the proportions of extrinsic hallucinations in both systems are similar. Therefore, we hypothesize that extrinsic hallucinations are the underlying cause for the in- adequate factual consistency observed in human written summaries.
사람이 생성한 요약과 LLM이 생성한 요약에서 문장 수준의 환각을 식별하여 사실적 일관성 수준을 비교할 수 있도록 주석자를 추가로 모집한다. 주석에 드는 상당한 비용을 감안하여, 우리는 문장 수준의 LLM으로 GPT-4를 선택했다. 표 1에서 볼 수 있듯이, 사람이 작성한 참조 요약은 GPT-4 요약과 비교했을 때 동등하거나 더 많은 수의 할루시네이션을 나타낸다. 다중 뉴스 및 코드 요약과 같은 특정 작업에서 사람이 작성한 요약은 사실적 일관성이 현저히 떨어지는 것으로 나타났다. 이 관찰된 현상을 더 깊이 이해하기 위해 이러한 사실 오류의 유형을 추가로 조사했다. 메이네즈 외(2020)의 연구에 따라 모든 환각을 내재적 환각과 외재적 환각의 두 가지 범주로 나눈다. 내재적 환각은 요약본의 사실 정보와 원문 텍스트 간의 불일치를 의미하며, 외재적 환각은 요약본에 원문 텍스트에 없는 특정 사실 정보가 포함되어 있을 때 발생한다.
표 2에서 보는 바와 같이 사람이 작성한 요약과 GPT-4 요약에서 내성(intrinsic) 환각과 외성(extrinsic) 환각의 비율을 분석한 결과, 사람이 작성한 요약의 사실적 일관성이 떨어지는 과제(예: 다중 뉴스 및 코드)에서 외성 환각의 발생률이 현저히 높다는 것을 알 수 있다. 그러나 인간과 GPT-4의 사실 일관성에는 거의 차이가 없는 경우, 두 시스템에서 외성 환각의 비율은 비슷하다. 따라서 우리는 외성 환각이 인간이 작성한 요약에서 관찰되는 사실적 일관성의 근본적인 원인이라고 가설을 세운다.
3.3. Comparative Analysis
Here we delve into an analysis of the specific strengths exhibited by LLM summaries in compar- ison to both human and fintuned summaries. We have included some concrete examples and a more detailed version of analysis in Appendix B.
Reference summaries vs. LLM summaries Compared to LLM summaries, we identify a specific issue with human-written reference sum- maries, their lack of fluency. As shown in Figure 2(a), human-written reference summaries are some- times flawed with incomplete information. Another issue observed in some human-written reference summaries, as concluded in the previous chapter’s quantitative analysis and shown in Figure 2(b) , is the presence of hallucinations.
Summaries generated by fine-tuned models vs. LLM summaries In comparison to LLM summaries, we find that summaries generated by fine-tuned models tend to have a fixed and rigid length, whereas LLMs are able to adjust the output length according to the input’s information volume. Additionally, when the input contains multiple top- ics, the summaries generated by fine-tuned models demonstrate lower coverage of these topics, as ex- ampled in Figure 3, while LLMs can capture all the topics when generating summaries.
여기에서는 사람이 작성한 요약과 핀튠 요약 모두와 비교하여 LLM 요약이 보여주는 특정 강점에 대해 분석해보자. 몇 가지 구체적인 예와 더 자세한 분석 내용은 부록 B에 포함되어 있다.
참조 요약과 LLM 요약 비교 사람이 직접 작성한 참조 요약의 특정 문제, 즉 유창성 부족을 확인했다. 그림 2(a)에서 볼 수 있듯이, 사람이 작성한 참조 요약은 때때로 불완전한 정보로 결함이 있다. 이전 장의 정량적 분석에서 결론을 내리고 그림 2(b)에 표시된 것처럼 일부 사람이 작성한 참조 요약에서 관찰된 또 다른 문제는 환각이 존재한다는 것이다.
파인튜닝 모델에 의해 생성된 요약과 LLM 요약 비교 파인튜닝 모델에 의해 생성된 요약은 길이가 고정되고 딱딱한 경향이 있는 반면, LLM은 입력의 정보량에 따라 출력 길이를 조정할 수 있다는 것을 알 수 있다. 또한 입력에 여러 개의 톱픽이 포함된 경우, 그림 3에서 볼 수 있듯이 파인튜닝 모델로 생성된 요약은 이러한 토픽에 대한 커버리지가 낮은 반면, LLM은 요약 생성 시 모든 토픽을 캡처할 수 있다.
4. The Changing Landscape of Summarization: Seeking New Horizons
Through the aforementioned manual evaluation, we have discovered that the quality of summaries gen- erated by LLMs surpasses that of the reference sum- maries in many datasets. It is foreseeable that with the continuous improvement of future LLMs, their summarization capabilities will further enhance. Previous summarization methods were often tai- lored to specific categories, domains, or languages, resulting in limited generality, and their signifi- cance is gradually diminishing. As mentioned in the introduction, nearly 70% of the research is no longer meaningful. However, we believe that the following directions are worth exploring:
앞서 언급한 수동 평가를 통해 많은 데이터 세트에서 LLM이 생성한 요약의 품질이 참조 요약의 품질을 능가하는 것을 발견했다. 향후 LLM이 지속적으로 개선됨에 따라 요약 기능은 더욱 향상될 것으로 예상된다. 이전의 요약 방법은 특정 범주, 도메인 또는 언어에 국한된 경우가 많았기 때문에 범용성이 제한적이었으며, 그 의미도 점차 줄어들고 있다. 서론에서 언급했듯이 연구의 약 70%는 더 이상 의미가 없다. 그러나 다음과 같은 방향은 살펴볼 가치가 있다 :
4.1 Summarization Datasets
The role of the dataset shifts from model training to testing, necessitating higher-quality reference sum- maries. Previously generated datasets will gradu- ally be phased out, and future reference summaries will require human expert annotations.
The majority of current summarization datasets are in English and focused on news articles, sci- entific articles, or Wikipedia (Foundation; Merity et al., 2016). And the source documents are rel- atively short. In order to thoroughly assess the summarization capabilities of LLMs, it becomes imperative to incorporate other diverse genres of data, as well as other languages, especially those that are low-resource in nature. Additionally, there is a need to include longer documents, such as books, within the datasets to facilitate comprehen- sive evaluation.
데이터 세트의 역할이 모델 학습에서 테스트로 옮겨가면서 더 높은 품질의 기준 합산값이 필요하다. 이전에 생성된 데이터 세트는 단계적으로 폐기될 것이며, 향후 참조 요약에는 사람의 전문가 주석이 필요하다.
현재 대부분의 요약 데이터 세트는 영어로 되어 있으며 뉴스 기사, 과학 논문 또는 Wikipedia에 초점을 맞추고 있다(Foundation; Merity 외., 2016). 그리고 소스 문서는 상대적으로 짧다. LLM의 요약 기능을 철저히 평가하기 위해서는 다른 다양한 장르의 데이터는 물론 다른 언어, 특히 리소스가 부족한 언어를 통합하는 것이 필수적이다. 또한 포괄적인 평가를 용이하게 하기 위해 책과 같이 긴 문서를 데이터 세트에 포함시켜야 할 필요성도 있다.
4.2 Summarization Approaches
Further investigation is warranted in the realm of application-oriented summarization approaches, with the assistance of LLMs.
Customized Summarization (Zhong et al., 2022): LLMs can be customized to generate sum- maries that align with individual user preferences, reading history, or expertise level, thereby person- alizing the summarization process.
Real-time Summarization (Yang et al., 2022): The ability to condense information in real time plays a vital role in various contexts, such as live steams, stock market fluctuations, or social media monitoring. Research efforts in this domain could concentrate on enhancing the promptness and effi- ciency of LLMs.
Interactive Summarization (Shapira et al., 2017): The development of models capable of in- teracting with users, soliciting clarification or feed- back throughout the summarization process, holds promise for augmenting the accuracy and relevance of summaries.
4.2 요약 접근법
응용 지향적 요약 접근법 영역에서는 LLM의 도움을 받아 추가 조사가 필요하다.
맞춤형 요약(Zhong et al., 2022): 개별 사용자의 선호도, 독서 이력 또는 전문 지식 수준에 맞는 요약문을 생성하도록 LLM을 사용자 정의하여 요약 프로세스를 개인화할 수 있다.
실시간 요약(Yang et al., 2022): 실시간으로 정보를 압축하는 기능은 실시간 스팀, 주식 시장 변동 또는 소셜 미디어 모니터링과 같은 다양한 상황에서 중요한 역할을 한다. 이 영역의 연구 노력은 LLM의 신속성과 효율성을 향상시키는 데 집중될 수 있다.
대화형 요약(Shapira et al., 2017): 요약 프로세스 전반에 걸쳐 사용자와 상호작용하고 설명이나 피드백을 요청할 수 있는 모델을 개발하면 요약의 정확성과 관련성을 높일 수 있을 것으로 기대된다.
4.3. Summarization Evaluation
It is imperative to bid farewell to antiquated as- sessment metrics such as ROUGE (Lin, 2004), as they no longer align with the evolving landscape of summarization. Future automated evaluation tech- niques for summarization hold promise in their re- liance on LLMs as demonstrated by recent studies (Kocmi and Federmann, 2023; Wang et al., 2023a; Liu et al., 2023; Luo et al., 2023; Gao et al., 2023). Furthermore, a shift in emphasis is necessary in the evaluation of summarization, with greater consider- ation given to the practical utility and applications of the generated summaries.
Extrinsic Evaluation (Pu et al., 2023): Measur- ing the effectiveness of a summary by using it as an input to another task (e.g., question-answering or decision-making tasks), to see if essential infor- mation has been retained.
더 이상 요약의 진화하는 환경에 부합하지 않는 ROUGE(Lin, 2004)와 같은 낡은 평가 지표와 작별을 고해야 한다. 요약에 대한 미래의 자동화된 평가 기법은 최근 연구(Kocmi and Federmann, 2023; Wang et al., 2023a; Liu et al., 2023; Luo et al., 2023; Gao et al., 2023)에서 입증된 것처럼 LLM에 다시 의존할 가능성이 높다. 또한, 요약 평가에서 강조점의 전환이 필요하며, 생성된 요약의 실제 유용성과 응용 프로그램을 더 많이 고려해야한다.
외재적 평가(Pu et al., 2023): 요약을 다른 작업(예: 질문-답변 또는 의사 결정 작업)의 입력으로 사용하여 필수 정보가 유지되었는지 확인함으로써 요약의 효과를 측정한다.
5. Related Work
Evaluating the ability of LLMs on summarization. Goyal et al. (2023) show that news sum- maries generated by GPT-3 are overwhelmingly preferred by humans compared with those gener- ated by fine-tuned models. Further, Zhang et al. (2023) find that news summaries generated by LLMs are evaluated to be on par with human- written summaries. Some studies have also ex- plored the performance of LLMs such as ChatGPT with automatic evaluations on aspect-based sum- marization (Yang et al., 2023) and cross-lingual summarization (Wang et al., 2023b). Our work in- volves GPT-3.5 and GPT-4 and conducts human evaluations on various data on which they have not been trained.
요약에 대한 LLM의 능력 평가. (2023)은 GPT-3에 의해 생성된 뉴스 요약이 미세 조정된 모델에 의해 생성된 뉴스 요약에 비해 인간이 압도적으로 선호한다는 것을 보여준다. 또한 Zhang 등(2023)은 LLM이 생성한 뉴스 요약이 사람이 작성한 요약과 동등한 수준으로 평가된다는 사실을 발견했다. 일부 연구에서는 측면 기반 요약(양 외, 2023) 및 언어 간 요약(왕 외, 2023b)에 대한 자동 평가를 통해 ChatGPT와 같은 LLM의 성능을 평가하기도 했다. 저희는 GPT-3.5와 GPT-4를 학습시키고 학습되지 않은 다양한 데이터에 대해 사람이 직접 평가하는 작업을 수행한다.
6. Conclusion
Through the development of new evaluation datasets and the conduction of comprehensive human evluation experiments that cover a wide range of summarization scenarios, our study demonstrates the remarkable performance of LLM- generated summaries compared to human-written reference summaries and summaries generated by fine-tuned models across diverse summarization tasks. LLM summaries exhibit superior fluency, factuality, and flexibility, especially in specialized and uncommon summarization scenarios. Our find- ings indicate that text summarization is undergoing significant transformation, rendering previous ap- proaches less meaningful in light of the advance- ments in LLMs. We also offer an outlook on the tasks worth exploring in the field of text summa- rization in the future, focusing on three aspects: datasets, methods, and evaluation. We hope that this can bring inspiration to relevant researchers regarding their future work.
새로운 평가 데이터 세트의 개발과 광범위한 요약 시나리오를 포괄하는 포괄적인 인간 유출 실험을 통해, 본 연구는 다양한 요약 작업에서 사람이 작성한 참조 요약 및 미세 조정된 모델로 생성된 요약과 비교하여 LLM으로 생성된 요약의 놀라운 성능을 입증했다. LLM 요약은 특히 전문적이고 흔하지 않은 요약 시나리오에서 뛰어난 유창성, 사실성, 유연성을 보여준다. 우리의 연구 결과는 텍스트 요약이 상당한 변화를 겪고 있으며, LLM의 발전에 비추어 볼 때 이전의 접근 방식은 의미가 없어지고 있음을 나타낸다. 또한 데이터 세트, 방법, 평가의 세 가지 측면에 초점을 맞춰 향후 텍스트 요약 분야에서 탐구할 가치가 있는 과제에 대한 전망을 제시한다. 이를 통해 관련 연구자들이 향후 연구에 영감을 얻을 수 있기를 바란다.
Limitations
We do not include other popular LLMs like LLaMA and Vacuna because these newer models do not dis- close the cutoff date of their training data. This lack of information makes it challenging for us to create a novel dataset specifically tailored for evaluating the zero-shot generation of summaries by LLMs. In the future, if these LLMs provide more details about their training data, it would be beneficial to incorporate additional LLMs and compare the differences among different series of such models. Due to the high cost, we only conduct human experiments on five common text summarization tasks. However, exploring some less common and more challenging summarization tasks, e.g. slides summarization, to test the capability of LLMs in the field text summarization would be an interesting avenue for future research.
LLaMA나 Vacuna와 같이 널리 사용되는 다른 LLM은 포함하지 않았는데, 그 이유는 이러한 최신 모델들은 학습 데이터의 마감일이 정해져 있지 않기 때문이다. 이러한 정보 부족으로 인해 LLM의 제로 샷 생성 요약을 평가하기 위해 특별히 맞춤화된 새로운 데이터 세트를 만들기가 어려웠다. 향후 이러한 LLM이 학습 데이터에 대한 더 자세한 정보를 제공한다면, 추가 LLM을 통합하고 이러한 모델 시리즈 간의 차이점을 비교하는 것이 유용하다. 비용이 많이 들기 때문에 5가지 일반적인 텍스트 요약 작업에 대해서만 인간 실험을 진행했다. 그러나 슬라이드 요약과 같이 덜 일반적이고 더 어려운 요약 작업을 탐색하여 현장 텍스트 요약에서 LLM의 기능을 테스트하는 것은 향후 연구를 위한 흥미로운 방법이 될 수 있다.
### 끝 ###
'인터넷/모바일 > 머신러닝' 카테고리의 다른 글
| (논문번역) Narrate Dialogues for Better Summarization (0) | 2023.09.26 |
|---|---|
| 우바부가] 모델 로딩 시에 with open(self.vocab_file, "rb") as f: 에러 (0) | 2023.09.21 |
| nvidia docker 재설치 (0) | 2023.05.10 |
| 괜찮은 python용 progressive bar (1) | 2020.02.05 |
| vtable error. undefined 해결방법 (0) | 2019.08.07 |

