원문 : https://aclanthology.org/2021.emnlp-main.530.pdf
이 글에 대한 모든 권리는 원문 저자인 Jiaao Chen, Diyi Yang에게 있음.
###
Simple Conversational Data Augmentation
for Semi-supervised Abstractive Conversation Summarization
Jiaao Chen
School of Interactive Computing, Georgia Institute of Technology
jiaaochen@gatech.edu
Diyi Yang
School of Interactive Computing, Georgia Institute of Technology
Abstract
Abstractive conversation summarization has received growing attention while most current state-of-the-art summarization models heavily rely on human-annotated summaries. To reduce the dependence on labeled summaries, in this work, we present a simple yet effective set of Conversational Data Augmentation (CODA) methods for semi- supervised abstractive conversation summarization, such as random swapping/deletion to perturb the discourse relations inside conversations, dialogue-acts-guided insertion to interrupt the development of conversations, and conditional-generation-based substitution to substitute utterances with their paraphrases generated based on the conversation context. To further utilize unlabeled conversations, we combine CODA with two-stage noisy self- training where we first pre-train the summarization model on unlabeled conversations with pseudo summaries and then fine-tune it on labeled conversations. Experiments conducted on the recent conversation summarization datasets demonstrate the effectiveness of our methods over several state-of-the-art data augmentation baselines. We have publicly released our code at https://github.com/ GT-SALT/CODA.
추상적 대화 요약은 점점 더 많은 관심을 받고 있지만, 대부분의 최신 요약 모델은 사람이 주석을 단 요약에 크게 의존하고 있다. 라벨링된 요약에 대한 의존도를 줄이기 위해 본 연구에서는 대화 내 담화 관계를 교란하는 무작위 교체/삭제, 대화의 전개를 방해하는 대화 행위 안내 삽입, 대화 맥락에 따라 생성된 의역어로 발화를 대체하는 조건 생성 기반 치환 등 반지도 추상 대화 요약에 간단하면서도 효과적인 대화 데이터 증강(CODA) 방법을 제시한다. 라벨이 지정되지 않은 대화를 더욱 활용하기 위해 CODA와 2단계 노이즈 자가 학습을 결합하여, 먼저 라벨이 지정되지 않은 대화에 대해 의사 요약으로 요약 모델을 사전 학습한 다음 라벨이 지정된 대화에 대해 미세 조정한다.최근 대화 요약 데이터 세트에 대해 수행한 실험은 여러 최첨단 데이터 증강 기준선에 대한 방법의 효과를 입증했다. https://github.com/ GT-SALT/CODA에서 코드를 공개했다.
-
Introduction
Abstractive conversation summarization, which targets at processing, organizing and distilling human interaction activities into short, concise and natural text (Murray et al., 2006; Wang and Cardie, 2013), is one of the most challenging and interesting problems in text summarization. Recently, neural abstractive conversation summarization has received growing attention and achieved remarkable performances by adapting document summarization pre-trained models and (Gliwa et al., 2019; Yu et al., 2021) and incorporating structural information (Chen and Yang, 2020; Feng et al., 2020c; Zhu et al., 2020a; Chen and Yang, 2021; Liu et al., 2019b). However, most of these models usually require abundant human-annotated summaries to yield the state-of-the-art performances (Gliwa et al., 2019), making them hard to be applied into real world applications (e.g. summarizing counseling sessions) that lack labeled summaries.
추상적 대화 요약은 인간의 상호 작용 활동을 짧고 간결하며 자연스러운 텍스트로 처리, 구성 및 추출하는 것을 목표로 하는 것으로(Murray et al., 2006; Wang and Cardie, 2013), 텍스트 요약에서 가장 도전적이고 흥미로운 문제 중 하나이다. 최근 뉴럴 추상적 대화 요약은 문서 요약 사전 학습 모델을 적용하고(Gliwa 등, 2019; Yu 등, 2021) 구조 정보structural information를 통합함으로써 주목받고 있으며 괄목할 만한 성과를 거두고 있다(Chen and Yang, 2020; Feng 등, 2020c; Zhu 등, 2020a; Chen and Yang, 2021; Liu 등, 2019b). 그러나 이러한 모델의 대부분은 일반적으로 최첨단 성능을 내기 위해 사람이 주석을 단 많은 요약이 필요하기 때문에(Gliwa et al., 2019), 라벨링된 요약이 없는 실제 애플리케이션(예: 상담 세션 요약)에 적용하기는 어렵다.
Data augmentation, which perturbs input data to create additional augmented data, has been utilized to alleviate the need of labeled data in various NLP tasks, and can be categorized into three major classes: (1) manipulating words and phrases at the token-level like designed word replacement (Kobayashi, 2018; Niu and Bansal, 2018), word deletion/swapping/insertion (Wei and Zou, 2019; Feng et al., 2020a), token/span cutoff (Shen et al., 2020b); (2) paraphrasing the entire input text at the sentence-level through round-trip translation (Sennrich et al., 2015; Xie et al., 2019; Chen et al., 2020b) or syntactic manipulation (Iyyer et al., 2018; Chen et al., 2020c); and (3) adding adversarial perturbations to the original data which dramatcally influences the model’s predictions (Jia and Liang, 2017; Niu and Bansal, 2019; Zhang et al., 2019). Despite the huge success, the former two mainly perturbs sentences locally while ignoring the diverse structures and context information in dialogues to create high-quality augmented conversations for summarization. The third one might utilize context through additional backward passes, but often require significant amount of computational and memory overhead (Zhang et al., 2019; Zhu et al., 2019), especially for summarization tasks with long input.
입력 데이터를 변형하여 추가적인 증강 데이터를 생성하는 데이터 증강은 다양한 NLP 작업에서 라벨링된 데이터의 필요성을 완화하기 위해 활용되어 왔으며, 크게 세 가지로 분류할 수 있다: (1) 설계된 단어 교체(Kobayashi, 2018; Niu and Bansal, 2018), 단어 삭제/교체/삽입(Wei and Zou, 2019; Feng et al., 2020a), 토큰/스팬 절삭(Shen et al, 2020b), (2) 문장 수준에서 전체 입력 텍스트를 다시 말로 바꾸는 것(Sennrich et al., 2015; Xie et al., 2019; Chen et al., 2020b) 또는 구문 조작syntactic manipulation (Iyyer et al, 2018; Chen et al., 2020c), (3) 원본 데이터에 적대적 교란을 추가하여 모델의 예측에 큰 영향을 미치는 경우(Jia and Liang, 2017; Niu and Bansal, 2019; Zhang et al., 2019) 등이 있다. 큰 성공에도 불구하고 앞의 두 가지 방법은 주로 문장을 국부적으로 교란하고 대화의 다양한 구조와 문맥 정보를 무시하여 요약을 위한 고품질의 증강 대화를 생성한다. 세 번째 방법은 추가적인 역방향 패스를 통해 문맥을 활용할 수 있지만, 특히 긴 입력이 필요한 요약 작업의 경우 상당한 양의 계산 및 메모리 오버헤드가 필요한 경우가 많다(Zhang et al., 2019; Zhu et al., 2019).
To this end, we introduce simple and novel set of Conversational Data Augmentation (CODA) techniques for conversation summarization guided by conversation structures and context, including:
이를 위해 다음과 같이 대화 구조와 문맥에 따라 대화 요약을 유도하는 간단하고 새로운 대화 데이터 증강(CODA) 기법을 소개한다:
(1)random swapping/deletion randomly swap or delete utterances in conversations to perturb the discourse relations, (2) dialogue-acts-guided insertion randomly insert utterances based on the dialogue acts like self-talk, repeating utterance and back-channel (Allen and Core, 1997; Sacks et al., 1978) to interrupt the conversations, and (3) conditional-generation-based substitution randomly substitute utterances in conversations based on pre-trained utterance generation models conditioned on the conversation context. Examples for operations in CODA are shown in Figure 1. To further enhance the performance when labeled summaries are limited, we extend CODA to semi supervised settings, Semi-CODA, where we combine CODA with two-stage noisy self-training (Xie et al., 2020; He et al., 2020) to utilize conversations without annotated summaries. Specifically, we repeat the process where we first generate pseudo summaries for unlabeled conversations with the base summarization model, then we pre-train a new model on pseudo data points and fine-tune the model on labeled conversations to form the updated summarization model. To sum up, our contributions are:
(1) 무작위 교체/삭제는 대화에서 발화를 무작위로 교체하거나 삭제하여 담화discourse 관계를 교란하고,
(2) 대화 행위 안내dialogue-acts-guided 삽입은 자기 대화, 반복 발화, 역방향 발화 등 대화 행위에 따라 발화를 무작위로 삽입하여 대화를 중단하고, (3) 조건 생성 기반 대체conditional-generation-based substitution는 대화 맥락에 따라 사전 학습된 발화 생성 모델에 따라 대화에서 발화를 무작위로 대체한다. CODA의 연산 예는 그림 1에 나와 있다. 레이블이 지정된 요약이 제한적인 경우, 성능을 더욱 향상시키기 위해 CODA를 2단계 노이즈 자가 학습(Xie et al., 2020; He et al., 2020)과 결합하여 주석이 없는 대화를 활용하는 반지도 설정인 Semi-CODA로 확장했다. 구체적으로, 먼저 기본 요약 모델을 사용하여 레이블이 지정되지 않은 대화에 대한 의사 요약을 생성한 다음, 의사 데이터 포인트에 대해 새 모델을 사전 학습하고 레이블이 지정된 대화에 대해 모델을 미세 조정하여 업데이트된 요약 모델을 형성하는 프로세스를 반복한다. 요약하자면, 우리의 기고는 다음과 같다:
- We propose simple yet effective data augmentation techniques for conversation summarization by considering the structures and context of conversations.
- We introduce a semi-supervised conversation summarization framework by combing CODA and two-stage noisy self-training.
- We demonstrate the effectiveness of our proposed methods through extensive experiments on two conversation summarization datasets
, SAMSum (Gliwa et al., 2019) and ADSC (Misra et al., 2015).
- 대화의 구조와 맥락을 고려하여 간단하면서도 효과적인 대화 요약 데이터 증강 기법을 제안한다.
- CODA와 2단계 노이즈 자가 학습을 결합한 반지도 대화 요약 프레임워크를 소개한다.
- 두 가지 대화 요약 데이터 세트에 대한 광범위한 실험을 통해 제안한 방법의 효과를 입증한다.
SAMSum(Gliwa 외., 2019) 및 ADSC(Misra 외., 2015).
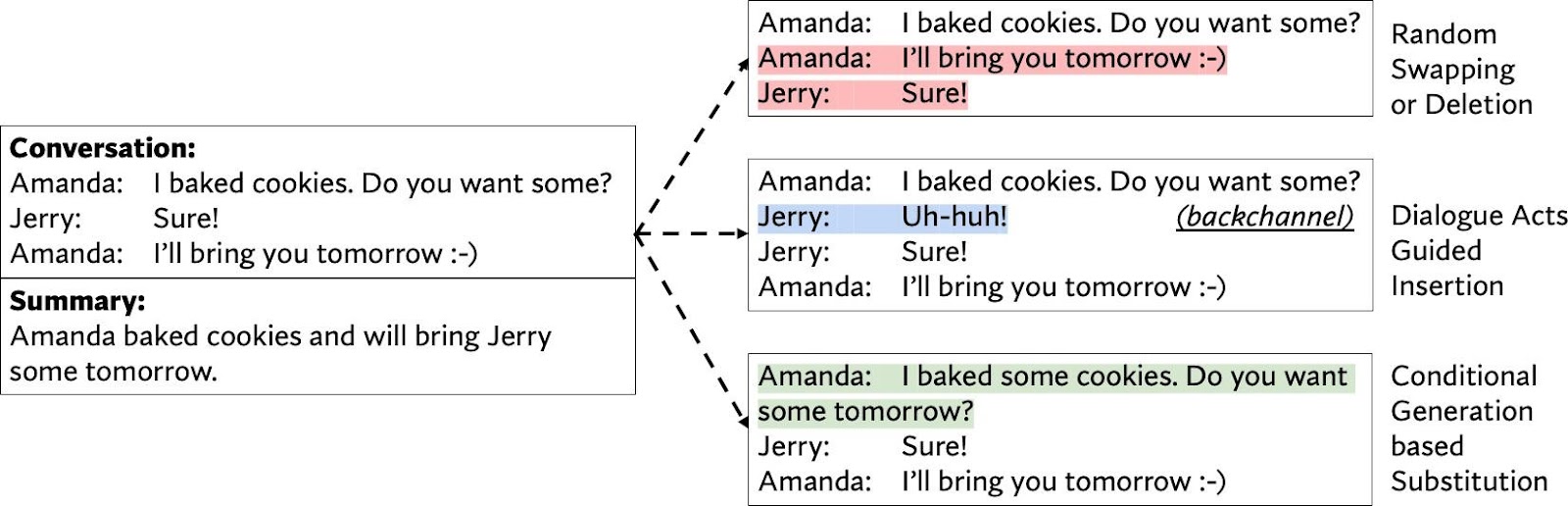
Figure 1: Examples of utilizing different CODA strategies to augment the given conversation including (1) random Swapping/Deletion where last two utterances are swapped (top), (2) dialogue-acts-based Insertion where a backchannel utterance is inserted after the first utterance (middle), and (3) conditional-generation-based substitution where the first utterance is substituted with a model-generated one (bottom).
그림 1: (1) 마지막 두 발화를 교체하는 무작위 스와핑/삭제(위), (2) 첫 번째 발화 뒤에 백채널 발화를 삽입하는 대화 행위 기반 삽입(가운데), (3) 첫 번째 발화를 모델 생성 발화로 대체하는 조건부 생성 기반 대체(아래) 등 주어진 대화를 보강하기 위해 다양한 CODA 전략을 활용하는 예시이다.
2. Related Work
2.1 Abstractive Conversation Summarization
Abstractive conversation summarization has received much attention recently. Other than directly apply document summarization models to conversational settings (Gliwa et al., 2019), models tailored for conversation are designed to achieve the state-of-the-art performances such as modeling conversations in a hierarchical way (Zhao et al., 2019; Zhu et al., 2020b). The rich structured information in conversations are also explored and leveraged such as dialogue acts (Goo and Chen, 2018), key point/entity sequences (Liu et al., 2019a; Narayan et al., 2021), topic segments (Liu et al., 2019c; Li et al., 2019), stage developments (Chen and Yang, 2020), discourse relations (Chen and Yang, 2021; Feng et al., 2020b). External information like commonsense knowledge has also been incorporated to help understand the global conversation context as well (Feng et al., 2020c). However, current summarization models still heavily rely on abundant parallel data to achieve the state-of-the-art performances (Yu et al., 2021). Little work has focused on low-resourced settings where well-annotated summaries are limited or even unavailable. To fill this gap, in this work, we introduce a set of conversational data augmentation techniques to alleviate the dependence on labeled summaries.
추상적 대화 요약은 최근 많은 관심을 받고 있다. 문서 요약 모델을 대화 환경에 직접 적용하는 것 외에도(Gliwa et al., 2019), 대화에 맞춤화된 모델은 대화를 계층적으로 모델링하는 등 최첨단 성능을 달성하도록 설계되었다(Zhao et al., 2019; Zhu et al., 2020b). 대화 행위(Goo and Chen, 2018), 요점/주체 시퀀스(Liu et al., 2019a; Narayan et al., 2021), 주제 세그먼트(Liu et al., 2019c; Li et al., 2019), 단계 전개(Chen and Yang, 2020), 담화 관계(Chen and Yang, 2021; Feng et al., 2020b) 등의 풍부한 구조화된 정보도 탐색 및 활용된다. 상식 지식과 같은 외부 정보도 글로벌 대화 맥락을 이해하는 데 도움이 되도록 통합되었다(Feng et al., 2020c). 그러나 현재의 요약 모델은 최첨단 성능을 달성하기 위해 여전히 풍부한 병렬 데이터에 크게 의존하고 있다(Yu et al., 2021). 주석이 잘 달린 요약이 제한적이거나 아예 제공되지 않는 리소스가 부족한 환경에 대한 연구는 거의 이루어지지 않았다. 이러한 격차를 메우기 위해 이 연구에서는 레이블이 지정된 요약에 대한 의존도를 완화하기 위한 일련의 대화형 데이터 증강 기법을 소개한다.
2.1 Data Augmentation for NLP
Data augmentation is one of the most common approaches to mitigate the need for labeled data in various NLP tasks (Feng et al., 2021). The augmented data is usually generated by modifying existing data points through transformations while keeping the semantic meaning unaffected like designed word/synonym replacement (Kobayashi, 2018; Niu and Bansal, 2018; Kumar et al., 2020), word deletion/swapping/insertion (Wei and Zou, 2019), token/span cutoff (Shen et al., 2020b), and paraphrasing through round-trip translation (Sennrich et al., 2015; Xie et al., 2019; Chen et al., 2020b). Even though they could be directly applied to conversation summarization settings, these prior techniques mainly modify the text locally and largely ignore the structure and context information in conversations to generate more effective and diverse augmented conversations. To this end, our CODA augmentation will perturb the conversation structures and substitute paraphrases by taking into account the conversation context.
데이터 증강은 다양한 자연어 처리 작업에서 레이블이 지정된 데이터의 필요성을 완화하기 위한 가장 일반적인 접근 방식 중 하나이다(Feng et al., 2021). 증강 데이터는 일반적으로 설계된 단어/동의어 대체와 같이 의미론적 의미에는 영향을 주지 않으면서 변환을 통해 기존 데이터 포인트를 수정하여 생성된다(Kobayashi, 2018; Niu and Bansal, 2018; Kumar et al, 2020), 단어 삭제/스왑/삽입(Wei and Zou, 2019), 토큰/스팬 잘라내기(Shen et al., 2020b), 왕복 번역을 통한 의역(Sennrich et al., 2015; Xie et al., 2019; Chen et al., 2020b) 등 다양한 변형 기법이 있다. 이러한 선행 기술들은 대화 요약 설정에 직접 적용될 수 있지만, 주로 텍스트를 국부적으로 수정하고 대화의 구조와 문맥 정보를 대부분 무시하여 보다 효과적이고 다양한 증강 대화를 생성할 수 없다. 이를 위해 코다의 증강 기술은 대화 문맥을 고려하여 대화 구조를 변형하고 의역을 대체한다.
2.2. Semi-supervised Learning Methods
Semi-supervised learning methods can further reduce the dependency on labeled data and enhance the models by using large amounts of unlabeled data (Chapelle et al., 2009; Gururangan et al., 2019; Chen et al., 2021). Unlabeled data is usually incorporated through consistency training (Xie et al., 2019; Chen et al., 2020b,a), co-training (Clark et al., 2018), variational auto encoders (Gururangan et al., 2019; Chen et al., 2018; Yang et al., 2017) or self-training (Scudder, 1965; Riloff and Wiebe, 2003; Xie et al., 2020). In this work, we focus on self-training, one of the most classic “pseudo-label” semi-supervised learning approaches (Yarowsky, 1995; Riloff and Wiebe, 2003). Self-training often iteratively incorporates unlabeled data by learning student models from pseudo labels assigned by teacher models. The teacher model could be the model trained on labeled data or the model from last iteration (Zhu and Goldberg, 2009). Recent work showed that combining self-training with better noise/augmentation techniques to perturb the input space greatly improve the performances on classification tasks (Rasmus et al., 2015; Laine and Aila, 2017; Miyato et al., 2019; Xie et al., 2020). However, their impact on language generation tasks like summarization is largely underexplored because, unlike classification tasks, the the pseudo summaries might be quite complicated and very different from human-annotated labels (He et al., 2020). Inspired by these previous self training work, we will combine our CODA with the two-stage noisy self-training framework (He et al., 2020) for semi-supervised abstractive conversation summarization.
준지도 학습 방법은 레이블이 지정된 데이터에 대한 의존도를 더욱 낮추고 대량의 레이블이 지정되지 않은 데이터를 사용하여 모델을 향상시킬 수 있다 (Chapelle et al., 2009; Gururangan et al., 2019; Chen et al., 2021). 라벨이 없는 데이터는 일반적으로 일관성 훈련(Xie et al., 2019; Chen et al., 2020b,a), 공동 훈련(Clark et al., 2018), 변형 자동 인코더(Gururangan et al., 2019; Chen et al., 2018; Yang et al., 2017) 또는 자가 훈련(Scudder, 1965; Riloff and Wiebe, 2003; Xie et al., 2020)을 통해 통합된다. 이 연구에서는 가장 고전적인 "유사 레이블" 반지도 학습 접근법 중 하나인 자가 학습에 초점을 맞춘다(Yarowsky, 1995; Riloff and Wiebe, 2003). 자가 학습은 종종 교사 모델에 의해 할당된 의사 레이블로부터 학생 모델을 학습하여 레이블이 지정되지 않은 데이터를 반복적으로 통합한다. 교사 모델은 레이블이 지정된 데이터로 학습된 모델일 수도 있고, 마지막 반복에서 학습된 모델일 수도 있다(Zhu와 Goldberg, 2009). 최근 연구에 따르면 자가 학습과 입력 공간을 교란하는 더 나은 노이즈/증강 기법을 결합하면 분류 작업의 성능이 크게 향상되는 것으로 나타났다(Rasmus et al., 2015; Laine and Aila, 2017; Miyato et al., 2019; Xie et al., 2020). 그러나 요약과 같은 언어 생성 작업에 미치는 영향은 분류 작업과 달리 의사 요약은 상당히 복잡하고 사람이 주석을 단 레이블과 매우 다를 수 있기 때문에 크게 연구되지 않았다(He et al., 2020). 이러한 이전의 자가 훈련 작업에서 영감을 얻어, 반지도 추상 대화 요약에 대한 2단계 노이즈 자가 훈련 프레임워크(He et al., 2020)와 CODA를 결합할 것이다.
3. Methods on Semi-Supervised CODA
In order to generate more diverse and effective augmented data for conversation summarization and alleviate the reliance on human annotations, we propose a set of simple Conversational Data Augmentation (CODA) to perturb conversations based on the conversation structures and global context (Section 3.1). We further introduce Semi- CODA under the self-training framework to utilize unlabeled conversations for semi-supervised conversation summarization (Section 3.2).
대화 요약을 위해, 보다 다양하고 효과적인 증강 데이터를 생성하고, 인간 의존도를 낮추기 위해, 대화 구조와 글로벌 컨텍스트를 기반으로 대화를 교란하는 간단한 대화 데이터 증강(CODA) 세트를 제안한다(섹션 3.1). 또한 셀프 트레이닝 프레임워크 하에서 라벨이 지정되지 않은 대화를 반지도 대화 요약에 활용할 수 있는 Semi- CODA를 도입한다(3.2절).
3.1 CODA
For a given conversation c = u0, ..., un with n utterances, CODA random performs one of the conversational perturbations described below to generate augmented conversation cj while preserving the semantic information of the global conversation.
Random Swapping or Deletion Utterances from different speakers in conversations usually follow Gricean Maxims (Dale and Reiter, 1995) to achieve effective communication in social situations, which requires utterances to be related to each other orderly under the context of discourse (Murray et al., 2006; Qin et al., 2017). From the perspective of perturbing discourse relations to create augmented conversations (Gui et al., 2021), we introduce two simple operations to perturb the discourse relations: (1) random swapping, which breaks the discourse relations by randomly swapping two utterances in one conversation to messes up the logic chain of utterance, and (2) random deletion, which goes against the discourse requirement by randomly deleting Kr = αd n utterances to provide less information in the conversations, where n is the number of utterances in conversations and αd is a hyper-parameter to control the strength of the deleting perturbation, as shown in Figure 1. In practice, for one conversation c, we combine these two strategies by randomly choosing one of them to generate the augmented conversation cj.
주어진 대화 c = u0, ..., un에 대해 발화가 n개일 경우, CODA 랜덤은 아래에 설명된 대화 섭동 중 하나를 수행하여 전체 대화의 의미 정보를 보존하면서 증강 대화 cj를 생성한다.
무작위 교체 또는 삭제 대화에서 서로 다른 화자의 발화는 일반적으로 사회적 상황에서 효과적인 의사소통을 달성하기 위해 그리스 맥심 (Gricean Maxims)(Dale and Reiter, 1995)을 따르는데, 이 격언은 담화의 맥락에서 발화가 서로 질서 있게 연관되어야 한다(Murray et al., 2006; Qin et al., 2017). 담화 관계를 교란하여 증강 대화를 생성한다는 관점에서(Gui et al, 2021), 담화 관계를 교란하는 두 가지 간단한 연산을 소개한다: (1) 무작위 교환은 대화에서 두 발화를 무작위로 교환하여 발화의 논리 체인을 어긋나게 만들어 대화 관계를 깨뜨린다. (2) 무작위 삭제는 대화 요구 사항에 반하여 대화에서 정보를 적게 제공하기 위해 무작위로 Kr = αd n 개의 발화를 삭제한다. 여기서 n은 대화에서의 발화 수이고, αd는 삭제 왜곡의 강도를 제어하는 하이퍼 파라미터이다. 실제로 하나의 대화 c에 대해 이러한 두 전략을 결합하여 무작위로 하나를 선택하여 증강 대화 cj를 생성한다.
Dialogue Acts Guided Insertion Unlike structured documents, conversations have unique characteristics of interruptions (Allen and Core, 1997) such as repetitions, false-starts, reconfirmations, hesitations and backchanneling (Sacks et al., 1978), making it challenging for summarization models to reason over conversations and extract key information. Inspired by these observations, we introduce a novel dialogue-acts-guided insertion to interrupt the conversations to generate augmented data. Specifically, for a given conversation c, we randomly insert repeated utterances or insert utterances whose dialogue acts (Jurafsky and Shriberg, 1997) are interruptions including acknowledge/backchannel (e.g., “Uh-huh”), response acknowledgement (e.g., “Oh, okay”), backchannel in question form (e.g., “Is that right?”), self-talk (e.g., “What is the thing I am thinking of”), or hedge (e.g., “I don’t know if I’m making any sense or not.”) to generate augmented cj, as shown in Figure 1 where an utterance with backchannel act “Uh-huh!” is inserted.
대화 행위 안내 삽입 구조화된 문서와 달리 대화에는 반복, 잘못된 시작, 재확인, 망설임, 백채널링(Sacks et al., 1978)과 같은 고유한 중단 특성(Allen and Core, 1997)이 있어 요약 모델이 대화를 추론하고 핵심 정보를 추출하는 데 어려움이 있다. 이러한 관찰에서 영감을 얻어 대화 중간에 삽입하여 증강 데이터를 생성하는 새로운 대화 행위 안내 삽입 방식을 도입했다. 구체적으로, 주어진 대화 c에 대해 반복되는 발화를 무작위로 삽입하거나 대화 행위(Jurafsky and Shriberg, 1997)가 인정/백채널(예: "어허"), 응답 인정(예: "오, 알았어요"), 질문 형식의 백채널(예: "맞아요?") 등의 중단인 발화를 삽입한다, "맞나요?"), 자기 대화(예: "내가 생각하는 게 뭐지?") 또는 헤지(예: "내가 말이 되는지 안 되는지 모르겠어.")를 사용하여 백채널 행위 "어-허!"가 삽입된 그림 1과 같이 증강된 CJ를 생성할 수 있다.
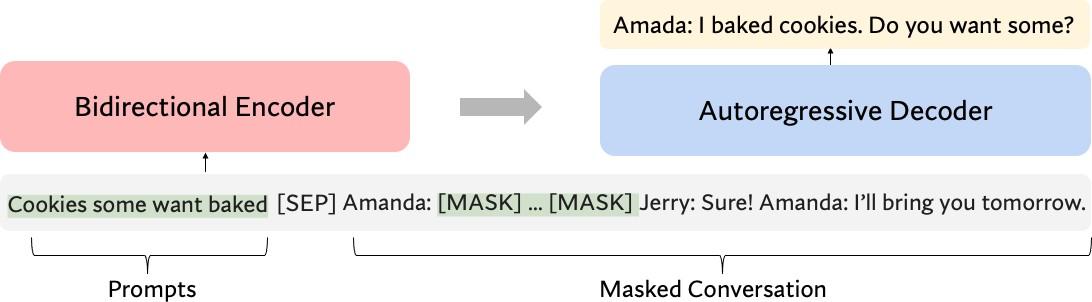
Figure 2: The model architecture for the conditional-generation-based. The randomly shuffled unique tokens in the utterance ui are prepended to the masked conversation cmask = u0, ..., ui−1, umask, ui+1, ..., un as input. A transformer-based sequence-to-sequence model is then applied to generate the corresponding utterance u.
그림 2: 조건부 생성 기반 모델 아키텍처. 발화 ui에서 무작위로 섞인 고유 토큰은 마스크된 대화 cmask = u0, ..., ui-1, umask, ui+1, ..., un에 입력으로 앞에 추가된다. 그런 다음 트랜스포머 기반 시퀀스 간 모델을 적용하여 해당 발화 u를 생성한다.
For inserting repeated utterances, we randomly select Kr = αr n utterances from the input conversation and directly insert them back. For other types of dialogue-acts-guided insertion, we randomly insert Kd = αd n utterances sampled from a pre-defined utterance set to random positions in the input conversation. The pre-defined set consists of 8,000 utterances: (1) utterances with desired dialogue acts from a human annotated Switchboard corpus (Jurafsky and Shriberg, 1997), and (2) utterances with desired dialogue acts from high confidence predictions using a state-of-the-art dialogue acts classifier (Raheja and Tetreault, 2019) (with 82.9% accuracy on Switchboard corpus) on SAMSum corpus (Gliwa et al., 2019).
반복 발화 삽입의 경우, 입력 대화에서 Kr = αr n 발화를 무작위로 선택한 후 다시 직접 삽입한다. 다른 유형의 대화-행위 안내 삽입의 경우, 사전 정의된 발화 세트에서 샘플링된 Kd = αd n개의 발화를 입력 대화의 임의 위치에 무작위로 삽입한다. 사전 정의된 발화 세트는 8,000개의 발화로 구성된다: (1) 사람이 주석을 단 스위치보드 말뭉치(Jurafsky and Shriberg, 1997)에서 원하는 대화 행위가 있는 발화, (2) SAMSum 말뭉치(Gliwa et al., 2019)에서 최신 대화 행위 분류기(Raheja and Tetreault, 2019)를 사용하여 높은 신뢰도로 예측한 대화 행위가 있는 발화(스위치보드 말뭉치에서 82.9%의 정확도)이다.
Conditional Generation based Substitution Paraphrasing has been effective as data augmentation on sentence-level tasks like sentence classification (Xie et al., 2019; Chen et al., 2020b) as it could generate sentences with similar semantic meaning but with different word choices. However, when it comes to utterances in a dialogue, simple paraphrasing techniques like round-trip translation (Sennrich et al., 2015) might not be able to capture the context information in conversation, leading to limited diversity and low quality in its augmented utterances. To this end, we propose a conditional generation based method to generate new utterances and substitute the original utterances. , with its architecture shown in Figure 2.
We first pre-train the conditional generation model g(.; θ) which could generate an utterance ui with a masked conversation cmask = u0, ..., ui−1, umask, ui+1, ..., un and a prompt pi as input. Specifically, during the pre-training stage, utterance ui c is randomly sampled and substituted with <MASK>. The unique tokens in ui are then randomly shuffled to form the prompt pi. We initialize the generation model g(.; θ) with BART base (Lewis et al., 2020), and prepend the prompt pi to the masked conversation cmask as input. The pre-training objective is:
조건부 생성 기반 대체 의역은 의미론적 의미는 비슷하지만 단어 선택이 다른 문장을 생성할 수 있기 때문에 문장 분류와 같은 문장 수준의 작업에서 데이터 증강으로 효과적이었다(Xie et al., 2019; Chen et al., 2020b). 그러나 대화 발화의 경우, 왕복 번역과 같은 단순한 의역 기법으로는 대화의 문맥 정보를 포착할 수 없어 증강 발화의 다양성이 제한되고 품질이 떨어질 수 있다 (Sennrich et al., 2015). 이를 위해 본 논문에서는 새로운 발화를 생성하고 원본 발화를 대체하는 조건부 생성 기반 방법을 제안한다. 의 아키텍처는 그림 2와 같다.
먼저 조건부 생성 모델 g(.; θ)를 사전 훈련하여 마스크 대화 cmask = u0, ..., ui-1, umask, ui+1, ..., un과 프롬프트 파이를 입력으로 받아 발화 ui를 생성할 수 있도록 한다. 구체적으로, 사전 훈련 단계에서 발화 ui c는 무작위로 샘플링되어 <MASK>로 치환된다. 그런 다음 ui의 고유 토큰을 무작위로 섞어 프롬프트 파이를 형성한다. 생성 모델 g(.; θ)를 BART 기반(Lewis et al., 2020)으로 초기화하고, 프롬프트 파이를 마스크된 대화 cmask에 입력으로 추가한다. 사전 훈련 목표는 다음과 같다:
L = − log P (ui|g(pi, cmask; θ)) (1)
During the augmentation stage, for a random utterance ui in c, we construct the cmask and pi in the same way as the pre-training stage. We employ the random sampling strategy with a tunable temperature τ to generate uji and construct the augmented conversation cj by substituting ui with uij in c; τ is a hyper-parameter to control the diversities (higher temperature would result in more diverse generations while injecting more noise). In practice, we randomly substitute Kg = αgn utterances in c with generated utterances from g(.; θ).
CODA for Conversation Summarization When training conversation summarization models f (.; θ), for any input conversation c with summary s in the training set C, we randomly choose and perform one of the above augmentations to generate cj in each epoch. The objective is:
증강 단계에서는 임의의 발화 ui가 c일 때 사전 훈련 단계와 동일한 방식으로 마스크와 파이를 구성한다. τ는 다양성을 제어하기 위한 하이퍼 파라미터로, 온도 τ를 조정할 수 있는 무작위 샘플링 전략을 사용하여 uji를 생성하고, τ를 c의 uij로 치환하여 증강 대화 cj를 구성한다(온도가 높을수록 더 많은 노이즈가 주입되는 동시에 더 다양한 생성물이 생성됨). 실제로는 c에서 Kg = αgn 발화를 g(.; θ)에서 생성된 발화로 임의로 대체한다.
대화 요약 모델 f(.; θ)를 훈련할 때, 훈련 세트 C에 요약 s가 있는 입력 대화 c에 대해 위의 증강 중 하나를 임의로 선택하여 수행하여 각 에포크에서 cj를 생성한다. 목표는 다음과 같다:
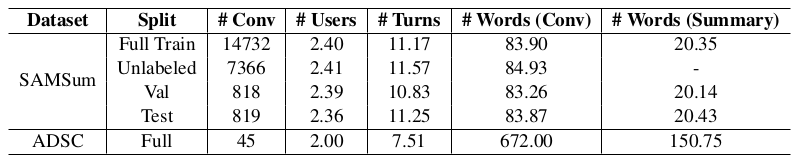
Table 1: Statistics of SAMSum (daily chat) and ADSC (debate) datasets, including the total number of conversations (# Conv), the average number of participants (# Users), the number of turns, the number of words in conversations and summaries per data point.
표 1: 총 대화 수(# Conv), 평균 참여자 수(# Users), 턴 수, 대화 단어 수, 데이터 포인트별 요약을 포함한 SAMSum(일일 채팅) 및 ADSC(토론) 데이터 세트의 통계이다.

L = −E(c,s)∼CEc′∼CODA(c) log P (s|f (cj; θ)) (2)
Note that our introduced CODA augmentation techniques can also be combined and performed in a sequential manner. CODA is agnostic to any conversation summarization models. In this work, we utilize the state-of-the-art summarization model, BART (Lewis et al., 2020), as our base model.
주목해야 할 점은 우리가 도입한 CODA 증강 기술이 순차적으로 결합되어 수행될 수 있다는 것이다. CODA는 어떤 대화 요약 모델에 대해서도 독립적으로 작동한다. 본 연구에서는 우리의 기본 모델로 최첨단 요약 모델인 BART (Lewis 등, 2020)을 활용한다.
3.2 Semi-supervised CODA
To further improve the performance of learning with limited annotated conversations, we combine CODA with two-stage noisy self-training framework (Xie et al., 2020; He et al., 2020) for utilizing unlabeled conversations. The semi-supervised CODA algorithm is shown in Algorithm 1.
제한된 주석이 달린 대화로 학습 성능을 더욱 향상시키기 위해, 라벨이 없는 대화를 활용하기 위한 2단계 노이즈 자가 학습 프레임워크(Xie et al., 2020; He et al., 2020)와 CODA를 결합한다. 반지도형 CODA 알고리즘은 알고리즘 1에 나와 있다.
Specifically, for a parallel conversation dataset Cl = (cl, sl) i=1:n where cl is the conversation and sl is the annotated summary, and a large unlabeled dataset Cu = (cu) i=1:m, where m >> n. In semi-CODA, a teacher conversation summarization model f (.; θ∗) is first trained on Cl where CODA perturbations are utilized to inject noise. Then semi-CODA iteratively (1) apply the teacher model f (.; θ∗) to predict pseudo summaries on unlabeled conversations Cu without any noise injected, (2) pre-train a new summarization model f (.; θ) on Cu with CODA being applied, (3) finetune f (.; θ) on labeled data Cl with CODA being applied and update the teacher model f (.; θ∗). The objective function of semi-CODA for annotated conversation is the same as Equation 2, while the objective function for unlabeled conversation is:
구체적으로, 병렬 대화 데이터 세트 Cl = (cl, sl) i=1:n(여기서 cl은 대화이고 sl은 주석이 달린 요약)과 대규모 라벨링되지 않은 데이터 세트 Cu = (cu) i=1:m(여기서 m >> n)의 경우, 세미-CODA에서는 먼저 교사 대화 요약 모델 f(.; θ∗)를 Cl에 대해 훈련하고, 여기서 CODA 섭동을 활용하여 노이즈를 주입한다. 그런 다음 세미-CODA는 반복적으로 (1) 교사 모델 f(.; θ∗)를 적용하여 노이즈가 주입되지 않은 비라벨 대화 Cu에 대해 의사 요약을 예측하고, (2) CODA가 적용된 Cu에 대해 새로운 요약 모델 f(.; θ)를 사전 훈련하고, (3) CODA가 적용된 라벨 데이터 Cl에 대해 f(.; θ)를 미세 조정하고 교사 모델 f(.; θ∗)를 업데이트한다. 주석이 달린 대화에 대한 세미-CODA의 목적 함수는 방정식 2와 동일하며, 라벨이 없는 대화에 대한 목적 함수는 다음과 같다:
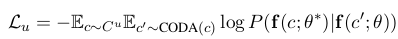
(3)
Here, θ∗ is the parameter from the teacher model (from last iteration) and fixed within the current iteration. In practice, after step (1) in semi-CODA, we apply BERT-score (Zhang* et al., 2020) to calculate the semantic relevance between generated summaries and the unlabeled conversation, and select a subset of Cu with the BERT-score higher than a threshold T for the following steps.
여기서 θ∗는 선생 모델(마지막 반복에서)의 매개변수이며 현재 반복 내에서 고정된다. 실제로 세미 코다의 (1) 단계 이후에는 생성된 요약과 라벨 없는 대화 간의 의미적 관련성을 계산하기 위해 BERT-score(Zhang* et al., 2020)를 적용하고, 다음 단계를 위해 임계값 T보다 높은 BERT-score를 가진 Cu의 하위 집합을 선택한다.
4. Experiments
4.1 Datasets
To demonstrate the effectiveness of our CODA methods on a human-annotated dialogue dataset, we chose SAMSum (Gliwa et al., 2019) that contains open-domain daily-chat conversations such as arranging meetings, planning travels and chitchat. We use the original validation and test set as our validation and test set. To construct a low- resourced setting, we randomly selected 1% (147) and 5% (735) conversations in the original training set as our training set, and 50% conversations (7366) as unlabeled conversation. We also evaluated the generalizability of our methods on Argumentative Dialogue Summary Corpus (ADSC) (Misra et al., 2015) about summarizing debates. The data statics are shown in the Table 1. During pre-processing, we separate every utterance in conversations with a special separator (“</s><s>”) and truncate the input conversation into 800 tokens.
사람이 주석을 단 대화 데이터셋에 대한 CODA 방법의 효과를 입증하기 위해 회의 주선, 여행 계획, 잡담과 같은 오픈 도메인 일상 대화가 포함된 SAMSum(Gliwa et al., 2019)을 선택했다. 우리는 원래의 검증 및 테스트 세트를 우리의 검증 및 테스트 세트로 사용한다. 리소스가 적은 환경을 구축하기 위해 원본 훈련 세트에서 1%(147개)와 5%(735개)의 대화를 무작위로 선택하여 훈련 세트로, 50%(7366개)의 대화를 라벨이 없는 대화로 선택했다. 또한 토론 요약에 관한 논증적Argumentative 대화 요약 코퍼스(ADSC)(Misra et al., 2015)를 대상으로 우리 방법의 일반화 가능성을 평가했다. 데이터 통계는 표 1에 나와 있다. 전처리 과정에서 우리는 대화의 모든 발화를 특수 구분 기호("</s><s>")로 구분하고 입력 대화를 800개의 토큰으로 잘라낸다.

Table 2: ROUGE-1, ROUGE-2 and ROUGE-L scores for different methods on the SAMSum Corpus test set with 1% (147) conversations where summaries are used for training. † means our methods.
표 2: 요약이 훈련에 사용된 1%(147개) 대화가 포함된 SAMSum 코퍼스 테스트 세트의 다양한 방법에 대한 ROUGE-1, ROUGE-2 및 ROUGE-L 점수. 는 당사 방법을 의미한다.
4.2 Baselines
We compared CODA with several state-of-the-art augmentation techniques and baselines:
CODA를 몇 가지 최신 증강 기술 및 기준선과 비교했다:
- BART (Lewis et al., 2020) is the state-of-the-art pre-trained models for summarization. We used BART-base 1 as our base model for all the methods. We also tested AdaptSum (Yu et al., 2021) by initializing the summarization model with BART-base pre-trained on XSUM (Narayan et al., 2018) summarization task.
- Token Cutoff (Wei and Zou, 2019; Shen et al., 2020a) randomly removes tokens from the input to create perturbed conversation.
- Span Cutoff (Shen et al., 2020a) randomly eases a contiguous span of text in conversations to lead to harder perturbed conversation.
- Round-trip Translation (Xie et al., 2019; Chen et al., 2020b) generate paraphrases by first translating them to an intermediate language like Romance and then translating them back. This work utilized pre-trained Marian translation model 2 to generate paraphrases.
- BART(Lewis et al., 2020)는 요약에 대해 사전 학습된 최신 모델이다. 저희는 모든 방법의 기본 모델로 BART-base 1을 사용했다. 또한 XSUM(Narayan et al., 2018) 요약 작업에 대해 사전 학습된 BART-base로 요약 모델을 초기화하여 AdaptSum(Yu et al., 2021)을 테스트했다.
- 토큰 컷오프(Token Cutoff)(Wei and Zou, 2019; Shen et al., 2020a)는 입력에서 토큰을 무작위로 제거하여 교란된 대화를 생성한다.
- 스팬 컷오프(Shen et al., 2020a)는 대화에서 연속된 텍스트의 스팬을 무작위로 완화하여 교란된 대화를 더 어렵게 만든다.
- 왕복 번역(Xie 외., 2019; Chen 외., 2020b)은 먼저 로망스와 같은 중간 언어로 번역한 다음 다시 번역하는 방식으로 의역을 생성한다. 이 연구에서는 사전 학습된 마리안 번역 모델 2를 활용하여 의역을 생성했다.
1https://huggingface.co/transformers/model_doc/bart.html
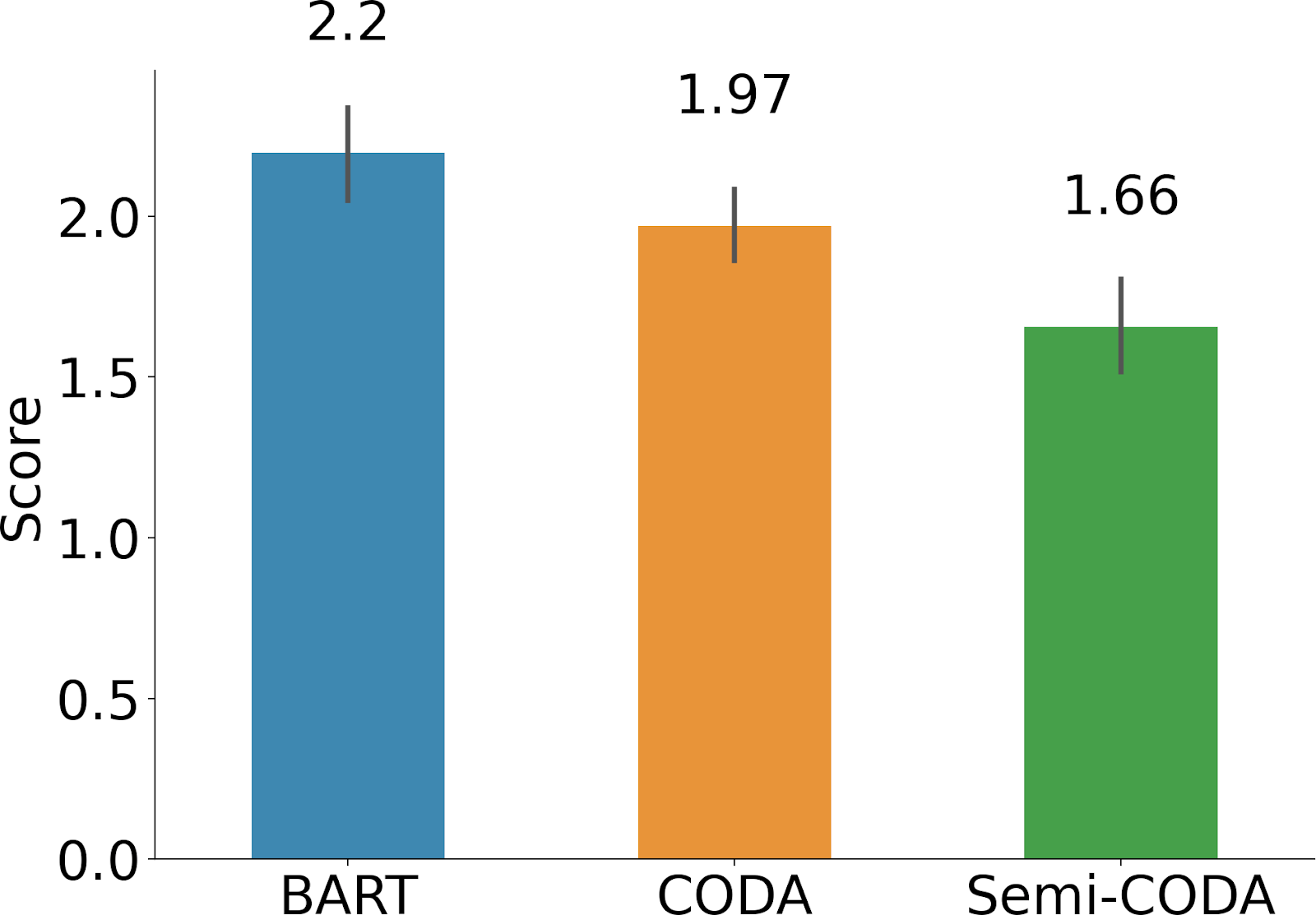
Figure 3: The average ranking every method receives from human evaluation (lower is better).
그림 3: 모든 방법이 사람의 평가에서 받은 평균 순위(낮을수록 좋음).
4.3 Model Settings
For the dialogue acts classifier, we directly followed the settings in Raheja and Tetreault (2019) and applied the trained classifier to predict dialogue acts of utterances in SAMSum corpus. We initialized our conditional generation model with BART- base (Lewis et al., 2020) and trained the model on SAMSum corpus. During augmentation, the sampling temperature is 0.7. α in CODA was selected from 0.1, 0.2, 0.3, 0.5 . We utilized RoBERTalarge to initialize the BERT-score (rescale with baseline) (Zhang* et al., 2020) and set the filtering threshold T = 0.25. The maximum iteration for semi-CODA was set 5. For all the methods, we used BART-base to initialize the conversation summarization model. During training, we used a batch size of 12 for 10 iterations with a 3e-5 learning rate. We used Adam optimizer with momentum β1 = 0.9, β2 = 0.998. During the decoding stage, we used beam search with a beam size of 4.
대화 행위 분류기의 경우, Raheja와 Tetreault(2019)의 설정을 직접 따르고 학습된 분류기를 적용하여 SAMSum 말뭉치에서 발화의 대화 행위 예측에 적용했다. 조건부 생성 모델을 BART- 기반(Lewis et al., 2020)으로 초기화하고 SAMSum 말뭉치에 대해 모델을 훈련했다. 증강 시 샘플링 온도는 0.7이며, CODA의 α는 0.1, 0.2, 0.3, 0.5 중에서 선택했다. RoBERTalarge를 활용하여 BERT 점수를 초기화하고(기준선으로 재조정)(Zhang* et al., 2020) 필터링 임계값 T = 0.25를 설정했다. 세미-CODA의 최대 반복 횟수는 5로 설정했다. 모든 방법에서 대화 요약 모델을 초기화하기 위해 BART-base를 사용했다. 훈련 시에는 3e-5의 학습률로 10회 반복에 배치 크기 12를 사용했다. 모멘텀 β1 = 0.9, β2 = 0.998인 아담 옵티마이저를 사용했다. 디코딩 단계에서는 빔 크기 4의 빔 검색을 사용했다.
2https://huggingface.co/transformers/model_doc/marian.html
3https://github.com/Tiiiger/bert_score
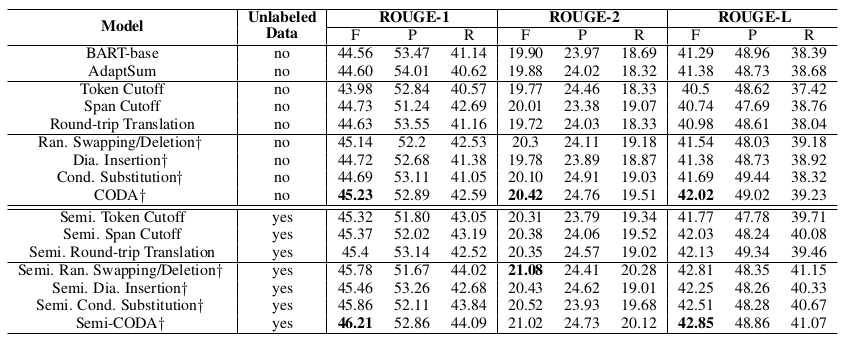
Table 3: ROUGE-1, ROUGE-2 and ROUGE-L scores for different methods on the SAMSum Corpus test set where 5% (735) conversations with summaries are used for training. † means our methods.
표 3: 표 3: 요약이 포함된 5%(735개) 대화가 훈련에 사용된 SAMSum 코퍼스 테스트 세트의 다양한 방법에 대한 ROUGE-1, ROUGE-2 및 ROUGE-L 점수. 는 당사의 방법을 의미한다.
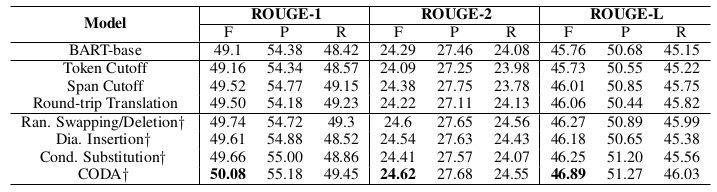
Table 4: ROUGE-1, ROUGE-2 and ROUGE-L scores for different methods on the SAMSum Corpus test set where all (14732) the conversations with summaries are used for training. † means our methods.
표 4: 요약이 포함된 모든 대화(14732개)가 훈련에 사용된 SAMSum 코퍼스 테스트 세트의 다양한 방법에 대한 ROUGE-1, ROUGE-2 및 ROUGE-L 점수이다. 는 당사의 방법을 의미한다.

Table 5: ROUGE scores for different methods on the out-of-domain ADSC Corpus where 1% (147) labeled conversations in SAMSum are used for training.
표 5: 샘섬의 레이블이 지정된 대화 중 1%(147개)가 훈련에 사용되는 도메인 외 ADSC 코퍼스의 다양한 방법에 대한 ROUGE 점수.
4.4 Results
Using Limited Labeled Summaries We varied the number of conversations with summaries for training in both fully-supervised and semi- supervised settings. The ROUGE scores using the rouge package 4, were shown in Table 2 (1% (147) labeled data was used) and Table 3 (5% (735) labeled data was used). Compared to BART-base by pre-training on a news summarization corpus XSUM (Narayan et al., 2018), AdaptSum (Yu et al., 2021) shows similar performances, probably due to the large differences between news and daily chats. When applying Cutoff based augmentations or Round-trip Translations to generate new conversations, performances boosted compared to BART-base as more data was used in the training. Through perturbing conversation structures to generate harder conversations via randomly swapping/deleting utterances and inserting interruption utterances, Random Swapping/Deletion and Dialogue-acts-guided Insertion outperformed the baseline augmentation methods. Substituting utterances with more context-aware paraphrases from Conditional-generation-based Substitution also consistently improved Round-trip Translations. By combining all the conversational augmentation techniques, CODA achieved the best scores (e.g., with an increase of 2.8% on ROUGE-1, 3.7% on ROUGE-2 and 3.2% on ROUGE-L compared to BART-base when 1% labeled data was used).
제한된 레이블이 지정된 요약 사용 완전 지도 및 반 지도 환경에서 훈련을 위해 요약이 포함된 대화 횟수를 다양하게 변경했다. 표 2(1%(147개) 라벨링된 데이터 사용)와 표 3(5%(735개) 라벨링된 데이터 사용)에 라우즈 패키지 4를 사용한 라우즈 점수가 표시되어 있다. 뉴스 요약 말뭉치 XSUM(Narayan et al., 2018)을 사전 학습한 BART 기반과 비교했을 때, 뉴스와 일상 채팅의 차이가 크기 때문인지 AdaptSum(Yu et al., 2021)은 비슷한 성능을 보였다. 새로운 대화를 생성하기 위해 컷오프 기반 증강 또는 왕복 번역을 적용할 경우, 훈련에 더 많은 데이터가 사용됨에 따라 BART 기반에 비해 성능이 향상되었다. 발화 무작위 교체/삭제 및 중단 발화 삽입을 통해 대화 구조를 교란하여 더 어려운 대화를 생성한 결과, 무작위 교체/삭제 및 대화 행위 안내 삽입이 기본 증강 방법보다 성능이 더 뛰어났다. 조건 생성 기반 대체에서 더 많은 문맥 인식 의역으로 발화를 대체하면 왕복 번역도 일관되게 개선되었다. 모든 대화형 증강 기법을 결합한 CODA는 1% 라벨링된 데이터를 사용했을 때 BART 기반에 비해 ROUGE-1에서 2.8%, ROUGE-2에서 3.7%, ROUGE-L에서 3.2% 증가하여 최고의 점수를 달성했다.
4https://github.com/pltrdy/rouge
After incorporating unlabeled conversations through two-stage noisy self-training framework, all the augmentation methods showed large performance improvements over our base model BART. Compared to previous state-of-the-art data augmentations (Cutoff and Round-trip Translation), our proposed conversational augmentation techniques worked better when combined with noisy self-training as they could provide more effective perturbations. Consistently, our Semi-CODA achieved the significantly better performances especially when there are less labeled data (e.g., with an increase of 8.1% on ROUGE-1, 11.9% on ROUGE- 2 and 9.2% on ROUGE-L compared to BART-base when 1% labeled data was used).
2단계 노이즈 자가 학습 프레임워크를 통해 레이블이 지정되지 않은 대화를 통합한 결과, 모든 증강 기법이 기본 모델인 BART에 비해 큰 성능 향상을 보였다. 이전의 최첨단 데이터 증강 기법(컷오프 및 왕복 번역)과 비교했을 때, 우리가 제안한 대화 증강 기법은 노이즈 자가 학습과 결합했을 때 더 효과적인 섭동을 제공할 수 있어 더 효과적이었다. 특히 레이블이 지정된 데이터가 적을수록 훨씬 더 우수한 성능을 보였다(예: 1% 레이블이 지정된 데이터를 사용했을 때 BART 기반에 비해 ROUGE-1에서는 8.1%, ROUGE- 2에서는 11.9%, ROUGE-L에서는 9.2% 증가).
Using All Labeled Summaries Table 4 summarized performances on the full setting where all the labeled data was utilized for training. CODA still showed performance gains compared to all baselines, suggesting that our proposed conversational data augmentation methods work well for conversation summarization even when a large number of labeled conversations is available for training.
모든 라벨링된 데이터 사용 표 4는 모든 라벨링된 데이터가 학습에 활용된 전체 설정에서의 성능을 요약한 것이다. CODA는 모든 기준선에 비해 여전히 성능 향상을 보였으며, 이는 우리가 제안한 대화 데이터 증강 방법이 많은 수의 라벨링된 대화를 학습에 사용할 수 있는 경우에도 대화 요약에 효과적이라는 것을 시사한다.
Human Evaluation We conducted human annotations to evaluate summaries generated by different models trained with 1% (147) conversations from SAMSum. Specifically, we asked annotators from Amazon Mechanical Turk 5 to rank summaries via a 1 (the most preferred) to 3 (the least preferred) scale, generated from BART, CODA and Semi-CODA for randomly sampled 150 conversations. Workers were paid 0.15$ for each ranking task. Every summary triples were ranked by three workers. The rank for every summary was aggregated by majority voting. The Intra-Class Correlation (ICC1k) was 0.561, indicating moderate agreement (Koo and Li, 2016)). As shown in Figure 3, our CODA and Semi-CODA received lower average rankings, which further demonstrated the effectiveness of CODA and Semi-CODA.
사람 평가 우리는 사람의 주석을 통해 SAMSum의 1%(147개) 대화로 훈련된 다양한 모델에서 생성된 요약을 평가했다. 구체적으로, Amazon Mechanical Turk 5의 어노테이터에게 무작위로 샘플링된 150개의 대화에 대해 BART, CODA 및 Semi-CODA에서 생성된 요약의 순위를 1(가장 선호)에서 3(가장 선호하지 않음)까지의 척도로 매기도록 요청했다. 작업자에게는 각 순위 지정 작업에 대해 0.15$를 지급했다. 세 명의 작업자가 모든 요약의 순위를 매겼다. 모든 요약의 순위는 다수결 투표로 집계되었다. 집단 내 상관계수(ICC1k)는 0.561로 중간 정도의 일치도를 나타냈다(Koo and Li, 2016). 그림 3에서 볼 수 있듯이, 코다와 세미 코다의 평균 순위가 낮아 코다와 세미 코다의 효과가 더욱 입증되었다.
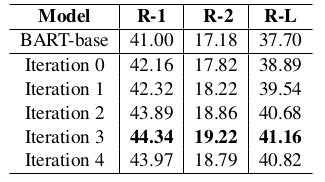
Table 6: ROUGE scores for different iterations in Semi- CODA on the SAMSum Corpus test set where 1% (147) labeled conversations are used for training.
표 6: 표 6: 1%(147개)의 레이블이 지정된 대화가 훈련에 사용되는 SAMSum 코퍼스 테스트 세트의 Semi- CODA에서 다양한 반복에 대한 ROUGE 점수이다.
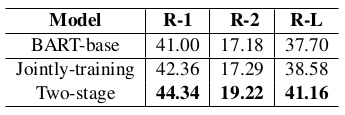
Table 7: ROUGE scores for different training strategies in Semi-CODA on the SAMSum Corpus test set where 1% (147) labeled conversations are used for training.
표 7: 1%(147개)의 레이블이 지정된 대화가 훈련에 사용되는 SAMSum 코퍼스 테스트 세트의 Semi-CODA에서 다양한 훈련 전략에 대한 ROUGE 점수.
Out-of-domain Evaluation We then directly evaluated models trained with 1% (147) conversations with summaries from SAMSum on the debate summarization dataset ADSC (Misra et al., 2015), to investigate the generalization abilities brought by different augmentation methods and unlabeled conversations. As shown in Table 5, consistent with in-domain evaluations, our introduced CODA and Semi-CODA achieved significantly better out-of-domain ROUGE scores than all the baselines, demonstrating the effectiveness of our designed conversational augmentation methods and the ways to incorporate unlabeled conversations.
도메인 외부 평가 토론 요약 데이터 세트 ADSC(Misra et al., 2015)에서 SAMSum의 요약이 포함된 1%(147개) 대화로 훈련된 모델을 직접 평가하여 다양한 증강 방법과 레이블이 없는 대화가 가져오는 일반화 능력을 조사했다. 표 5에서 볼 수 있듯이, 도메인 내 평가와 일관되게, 우리가 도입한 코다와 세미 코다는 모든 기준선보다 훨씬 더 나은 도메인 외 ROUGE 점수를 달성하여 우리가 설계한 대화 증강 방법과 라벨이 없는 대화를 통합하는 방법의 효과를 입증했다.
4.5 Ablation Studies
Number of Iterations in Semi-CODA Here we showed the effects of iterative training in Semi- CODA. For all the iterations in Semi-CODA, we adopted the same hyperparameters. As shown in Table 6, ROUGE scores kept improving and achieved the best performance at iteration 3, and then started to converge. This indicates the effectiveness of iterative training in Semi-CODA by continually updating the teacher model to generate better pseudo summaries.
Two-stage Self-training vs. Joint Self-training One alternative in self-training is to merge the labeled conversation and conversations with pseudo summaries and train new models on them jointly (Edunov et al., 2018). We compared our two-stage training strategy in Semi-CODA with the jointly- training with the same set of hyperparameters in Table 7. We found that two-stage training outperformed jointly training, indicating that our two- stage strategy in Semi-CODA could effectively mitigate the noise from pseudo summaries.
Semi-CODA의 반복 횟수 여기서는 Semi-CODA에서 반복 훈련의 효과를 보여주었다. Semi-CODA의 모든 반복에 대해 동일한 하이퍼 파라미터를 적용했다. 표 6에서 볼 수 있듯이 ROUGE 점수는 계속 개선되어 반복 3에서 최고의 성능을 달성한 후 수렴하기 시작했다. 이는 더 나은 의사 요약을 생성하기 위해 교사 모델을 지속적으로 업데이트함으로써 Semi-CODA의 반복 학습이 효과적이라는 것을 나타낸다.
2단계 자가 학습과 공동 자가 학습 자가 학습의 한 가지 대안은 레이블이 지정된 대화와 대화를 의사 요약과 병합하고 이를 바탕으로 새로운 모델을 공동으로 학습하는 것이다(Edunov et al., 2018). 표 7에서 세미 코다의 2단계 훈련 전략과 동일한 하이퍼 파라미터 세트를 사용한 공동 훈련 전략을 비교했다. 그 결과 2단계 훈련이 공동 훈련보다 우수한 성능을 보였으며, 이는 Semi-CODA의 2단계 전략이 의사pseudo 요약으로 인한 노이즈를 효과적으로 완화할 수 있음을 나타낸다.
Conclusion
In this work, we introduced a simple yet effective set of conversational data augmentation methods CODA, for improving conversation summarization in low-resourced settings. To further utilize unlabeled conversations, we proposed Semi-CODA that utilizes a two-stage noisy self-training framework. Experiments on both in-domain and out-of-domain evaluations demonstrated that our CODA augmented conversations better compared to previous state-of-the-art augmentation methods. In the future, we plan to examine diverse conversation structures for conversation augmentation and work on zero-shot conversation summarization tasks.
이번 연구에서는 리소스가 부족한 환경에서 대화 요약 기능을 개선하기 위해 간단하면서도 효과적인 대화 데이터 증강 방법인 CODA를 소개했다. 라벨이 지정되지 않은 대화를 더욱 활용하기 위해 2단계 노이즈 자가 학습 프레임워크를 활용하는 Semi-CODA를 제안했다. 도메인 내 평가와 도메인 외부 평가 모두에서 실험한 결과, CODA가 이전의 최첨단 증강 방법에 비해 대화를 더 잘 증강한다는 것이 입증되었다. 향후에는 대화 증강을 위한 다양한 대화 구조를 검토하고 제로 샷 대화 요약 작업을 수행할 계획이다.
Acknowledgements
We would like to thank the anonymous reviewers and the members of Georgia Tech SALT Lab for their feedback. This work is supported in part by grants from Cisco and Amazon.
피드백을 주신 익명의 리뷰어와 조지아 공대 SALT 연구소의 구성원들에게 감사의 말씀을 드립니다. 이 연구는 Cisco와 Amazon의 보조금으로 부분적으로 지원되었다.
References
(후략)


