원문 : https://arxiv.org/pdf/2309.11495.pdf
이 글에 대한 모든 권리는 원문 저자”들”에게 있음. (너무 많아서 이름 생략)
###
CHAIN-OF-VERIFICATION REDUCES HALLUCINATION IN LARGE LANGUAGE MODELS
Shehzaad Dhuliawala
Meta AI & ETH Zu¨rich
Mojtaba Komeili
Meta AI
Jing Xu
Meta AI
Roberta Raileanu
Meta AI
Xian Li
Meta AI
Asli Celikyilmaz
Meta AI
Jason Weston
Meta AI
ABSTRACT
Generation of plausible yet incorrect factual information, termed hallucination, is an unsolved issue in large language models. We study the ability of language models to deliberate on the responses they give in order to correct their mistakes. We develop the Chain-of-Verification (COVE) method whereby the model first (i) drafts an initial response; then (ii) plans verification questions to fact-check its draft; (iii) answers those questions independently so the answers are not biased by other responses; and (iv) generates its final verified response. In experiments, we show COVE decreases hallucinations across a variety of tasks, from list-based questions from Wikidata, closed book MultiSpanQA and longform text generation.
환각이라고 불리는 -그럴듯하지만 잘못된 사실 정보를 생성하는- 것은 대규모 언어 모델에서 해결되지 않은 문제이다. 우리는 언어 모델이 자신의 응답을 심사하고, 실수를 수정하는 능력을 연구한다. 모델이 먼저 (i) 초기 응답 초안을 작성한 다음, (ii) 초안을 사실 확인하기 위해 검증 질문을 계획하고, (iii) 다른 응답에 의해 응답이 편향되지 않도록 해당 질문에 독립적으로 답변하고, (iv) 최종적으로 검증된 응답을 생성하는 COVE (Chain-of- Verification) 방법을 제안한다. 실험 결과, COVE는 위키데이터의 목록 기반 질문, 비공개 도서 MultiSpanQA, 롱폼longform 텍스트 생성 등 다양한 작업에서 환각을 감소시키는 것으로 나타났다.
1.INTRODUCTION
Large Language Models (LLMs) are trained on huge corpora of text documents with billions of tokens of text. It has been shown that as the number of model parameters is increased, performance at tasks such as closed book QA improve in accuracy, and larger models can generate more correct factual statements (Radford et al., 2019; Petroni et al., 2019). However, even the largest models can still fail, particularly on lesser known torso and tail distribution facts (Sun et al., 2023a), i.e. those that occur relatively rarely in the training corpora. In those cases where the model is incorrect, they instead generate an alternative response which is typically plausible looking (e.g., a similar entity, but an incorrect one). These factually incorrect generations are referred to as hallucinations (Maynez et al., 2020). Further, in longform tasks consisting of generating multiple sentences or paragraphs, the hallucination problem can be exacerbated due to the issue of exposure bias (Wang & Sennrich, 2020).
Large Language Models(LLM)은 수십억 개의 텍스트 토큰이 포함된 방대한 텍스트 문서 말뭉치를 학습한다. 모델 파라미터의 수가 증가함에 따라 비공개 도서 QA와 같은 작업의 정확도가 향상되었고, 더 큰 모델은 더 정확한 사실 진술을 생성할 수 있는 것으로 나타났다(Radford 외., 2019; Petroni 외., 2019). 그러나 아무리 큰 모델이라도 특히 잘 알려지지 않은 몸통과 꼬리 분포 사실(Sun et al., 2023a), 즉 훈련 말뭉치에서 상대적으로 드물게 발생하는 사실에 대해서는 여전히 실패할 수 있다. 모델이 부정확한 경우, 정답 대신 일반적으로 그럴듯해 보이는 대체 응답(예: 비슷한 개체이지만 부정확한 응답)을 생성한다. 이렇게 사실적으로 잘못된 생성물을 환각hallucination이라고 한다(Maynez et al., 2020). 또한 여러 문장이나 단락을 생성하는 긴 형식의 과제에서는 노출 편향 문제로 인해 환각 문제가 심해질 수 있다(Wang & Sennrich, 2020).
The current wave of language modeling research goes beyond next word prediction, and has focused on their ability to reason. Improved performance in reasoning tasks can be gained by encouraging language models to first generate internal thoughts or reasoning chains before responding (Wei et al., 2022; Adolphs et al., 2021; Wang et al., 2022; Lanchantin et al., 2023), as well as updating their initial response through self-critique (Press et al., 2022; Madaan et al., 2023). In this work we follow this line of research to study how and when language-model-based reasoning can be used to reduce hallucinations. We develop an approach, called Chain-of-Verification (CoVe) which, given an initial draft response, first plans verification questions to check its work, and then systematically answers those questions in order to finally produce an improved revised response.
현재 언어 모델링 연구의 물결은 ‘다음에 나올 단어 예측’을 넘어 추론 능력에 초점을 맞추고 있다. 언어 모델이 응답하기 전에 먼저 내부 생각이나 추론 사슬을 생성하도록 유도하고(Wei 외, 2022; Adolphs 외, 2021; Wang 외, 2022; Lanchantin 외, 2023), 자기 비평을 통해 초기 응답을 업데이트함으로써 추론 작업에서 향상된 성능을 얻을 수 있다(Press 외, 2022; Madaan 외, 2023). 본 연구에서는 이러한 연구 흐름을 따라 언어 모델 기반 추론이 환각을 줄이는데 언제, 어떻게 사용될 수 있는지 연구한다. 우리는 초기 응답 초안이 주어지면, 먼저 그 작업을 확인하기 위해 검증 질문을 계획한 다음, 이러한 질문에 체계적으로 답변하여 최종적으로 개선된 수정 응답을 생성하는 체인 검증(Chain-of-Verification, CoVe)이라는 접근법을 개발했다.
We find that independent verification questions tend to provide more accurate facts than those in the original longform answer, and hence improve the correctness of the overall response. We study variations on this recipe across a range of tasks: from list-based questions, closed booked QA and longform text generation. We first propose a joint approach for generating the entire verification chain left-to-right, which improves performance and decreases hallucinations compared to the baseline language model. However, models that attend to existing hallucinations in the context from their own generations tend to repeat the hallucinations. Hence we also introduce further improvements with factored variants which separate out the verification chain steps, in terms of which context is attended to. We show how these factored variants give further performance gains across all three tasks considered.
독립적인 검증 질문이 기존에 있던 긴 답변보다 더 정확한 사실을 제공하는 경향이 있고, 전체 답변의 정확성을 향상시킨다는 사실을 발견했다. 목록 기반 질문, 비공개 QA, 롱폼 텍스트 생성 등 다양한 작업에서 이 레시피의 변형을 연구한다. 먼저 전체 검증 체인을 왼쪽에서 오른쪽으로 생성하는 공동 접근joint approach 방식을 제안하여 기본 언어 모델에 비해 성능을 개선하고 환각을 줄였다. 하지만 자체 세대의 문맥에서 기존 환각에 주목하는 모델은 환각을 반복하는 경향이 있다. 따라서 어떤 컨텍스트에 주의를 기울이는지에 따라 검증 체인 단계를 분리하는 팩터 변형을 통해 추가적인 개선 사항을 도입했다. 이러한 팩터 변형이 고려된 세 가지 작업 모두에서 어떻게 추가적인 성능 향상을 가져오는지 보여준다.
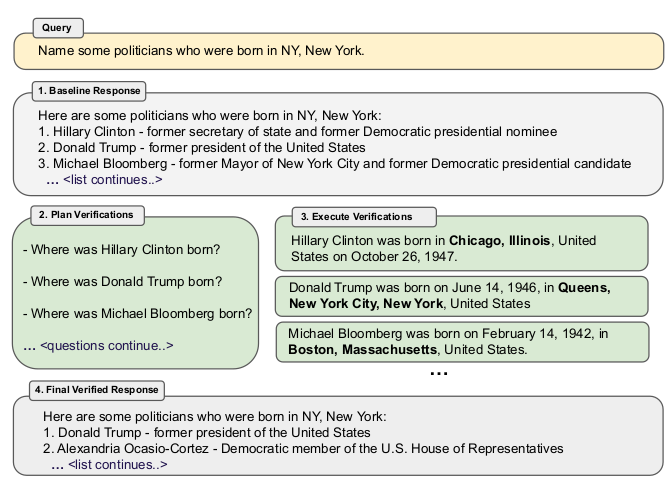
Figure 1: Chain-of-Verification (CoVe) method. Given a user query, a large language model generates a baseline response that may contain inaccuracies, e.g. factual hallucinations. We show a query here which failed for ChatGPT (see section 9 for more details). To improve this, CoVe first generates a plan of a set of verification questions to ask, and then executes that plan by answering them and hence checking for agreement. We find that individual verification questions are typically answered with higher accuracy than the original accuracy of the facts in the original longform generation. Finally, the revised response takes into account the verifications. The factored version of CoVe answers verification questions such that they cannot condition on the original response, avoiding repetition and improving performance.
그림 1: CoVe(연쇄 검증) 방법. 사용자 쿼리가 주어지면 대규모 언어 모델이 사실 착각과 같은 부정확한 내용이 포함될 수 있는 기준 응답을 생성한다. 여기에서는 ChatGPT에 실패한 쿼리를 보여준다(자세한 내용은 섹션 9 참조). 이를 개선하기 위해 CoVe는 먼저 질문할 일련의 확인 질문 계획을 생성한 다음, 해당 질문에 답변하여 동의 여부를 확인함으로써 해당 계획을 실행한다. 일반적으로 개별 확인 질문은 원래 롱폼을 생성할 때 사실에 대한 정확도보다 더 높은 정확도로 답변되는 것으로 나타났다. 마지막으로, 수정된 답변은 검증을 고려한다. 팩터 CoVe 버전은 검증 질문에 원래 응답에 조건이 붙지 않도록 답변하여 반복을 방지하고 성능을 개선한다.
2. RELATED WORK
Hallucination is a general problem in language model generations that appears across many tasks, from summarization (Maynez et al., 2020) to open-domain dialogue (Roller et al., 2020), and has not been resolved by simply scaling up training data or model size (Zhang et al., 2023). For a survey of the hallucination issue, see Ji et al. (2023). A majority of the methods for reducing hallucination can be divided into roughly three categories: training-time correction, generation-time correction and via augmentation (tool-use).
환각은 언어 모델 생성의 일반적인 문제로 요약(Maynez 외, 2020)에서 개방형 도메인 대화(Roller 외, 2020)에 이르기까지 다양한 작업에 걸쳐 나타나며, 단순히 학습 데이터나 모델 크기를 확장하는 것으로 해결되지 않았다(Zhang 외, 2023). 환각 문제에 대한 설문조사는 Ji 등(2023)을 참조하라. 환각을 줄이기 위한 대부분의 방법은 크게 훈련 시간 보정, 생성 시간 보정, 증강(도구 사용)의 세 가지 범주로 나눌 수 있다.
In training-time correction methods, an attempt is made to improve the raw left-to-right generations of an encoder-decoder or decoder-only language model by either training or otherwise adjusting the model weights to decrease the probability of hallucinated generations. This includes using reinforcement learning (Roit et al., 2023; Wu et al., 2023), constrastive learning (Chern et al., 2023b; Sun et al., 2023b) and other methods (Li et al., 2023).
훈련 시간 보정 방법에서는 인코더-디코더 또는 디코더 전용 언어 모델의 원시 왼쪽에서 오른쪽으로 생성물을 개선하기 위해 훈련하거나 모델 가중치를 조정하여 환각 생성 확률을 줄이려고 시도한다. 여기에는 강화 학습(Roit 외, 2023; Wu 외, 2023), 대비constrastive 학습(Chern 외, 2023b; Sun 외, 2023b) 및 기타 방법(Li 외, 2023)을 사용하는 것이 포함된다.
In generation-time correction, a common theme is to make reasoning decisions “on top of” the base LLM in order to make them more reliable. For example, by considering the probabilities of the generated tokens (Mielke et al., 2022; Kadavath et al., 2022). In Manakul et al. (2023) multiple samples are drawn from the model to detect hallucinations. In Varshney et al. (2023) hallucinations are identified using low confidence scores, and their correctness is checked through a validation procedure, mitigated, and then the generation is continued. An alternative to using the confidence scores is to leverage inconsistencies in the LLMs output to detect hallucination. Agrawal et al. (2023) use both multiple samples and consistency detection by asking direct and indirect queries to check for hallucinated references. Cohen et al. (2023) introduce a method called LM vs LM which simulates an interactive setup between two LLMs where one LLM acts as an examiner and tests if the output is consistent via repeated cross-examination. Cohen et al. (2023) shows that using inconsistencies for QA tasks can outperform using confidence scores for hallucination detection. COVE also uses a related self-consistency approach, but without the multi-agent (multi-LLM) debate concept.
생성 시간 보정에서 일반적인 주제는 더 신뢰할 수 있는 결정을 내리기 위해 기본 LLM "위에" 추론 결정을 내리는 것이다. 예를 들어, 생성된 토큰의 확률을 고려하는 것이다(Mielke et al., 2022; Kadavath et al., 2022). (2023)에서는 환각을 감지하기 위해 모델에서 여러 샘플을 추출한다. (2023)에서는 낮은 신뢰도 점수를 사용하여 환각을 식별하고, 검증 절차를 통해 정확성을 확인한 후 완화한 다음 생성을 계속한다. 신뢰도 점수를 사용하는 대신 LLM 출력의 불일치를 활용하여 환각을 감지하는 방법도 있다. (2023)은 환각 참조를 확인하기 위해 직접 및 간접 쿼리를 요청하여 여러 샘플과 일관성 감지를 모두 사용한다. Cohen 등(2023)은 두 LLM 간의 대화형 설정을 시뮬레이션하여 한 LLM이 검사자 역할을 하고 반복적인 교차 검사를 통해 산출물이 일관성이 있는지 테스트하는 LM vs LM이라는 방법을 도입한다. Cohen 외(2023)의 연구에 따르면 QA 작업에 불일치를 사용하는 것이 환각 감지를 위한 신뢰도 점수를 사용하는 것보다 더 나은 성능을 발휘할 수 있다. COVE도 관련 자체 일관성 접근 방식을 사용하지만 다중 에이전트(다중-LLM) 토론 개념이 없다.
A third approach is to use external tools to help mitigate hallucinations, rather than relying solely on the abilities of the language model itself. For example, retrieval-augmented generation can decrease hallucinations by using factual documents for grounding (Shuster et al., 2021; Jiang et al., 2023b; Yu et al., 2023) or chain-of-thought verification (Zhao et al., 2023). Other approaches include using tools for fact-checking (Chern et al., 2023a; Galitsky, 2023; Peng et al., 2023), or linking to external documents with attribution (Menick et al., 2022; Rashkin et al., 2023; Gao et al., 2023).
세 번째 접근 방식은 언어 모델 자체의 능력에만 의존하지 않고 환각을 완화하는 데 도움이 되는 외부 도구를 사용하는 것이다. 예를 들어, 검색 증강 생성은 근거를 위해 사실 문서를 사용함으로써 환각을 줄일 수 있다(Shuster 외., 2021; Jiang 외., 2023b; Yu 외., 2023) 또는 연쇄 사고 검증(Zhao 외., 2023). 다른 접근법으로는 사실 확인을 위한 도구를 사용하거나(Chern 외, 2023a; Galitsky, 2023; Peng 외, 2023), 어트리뷰션이 있는 외부 문서에 링크하는 방법(Menick 외, 2022; Rashkin 외, 2023; Gao 외, 2023) 등이 있다.
There are also a number of related works in improving reasoning for logical and mathematical tasks, even if they do not address reducing hallucination explicitly. Several approaches have been shown to improve results with extended reasoning steps by the system, such as chain-of-thought (Wei et al., 2022), deductive verification (Ling et al., 2023), and self-verification (Miao et al., 2023; Jiang et al., 2023a; Weng et al., 2022). The latter tries to predict the (masked) question given the answer for math problems, and use that as evidence that this is the correct solution.
환각 감소를 명시적으로 다루지 않더라도 논리 및 수학적 과제에 대한 추론을 개선하는 관련 연구도 다수 존재한다. 연쇄적 사고(Wei 외, 2022), 연역적 검증(Ling 외, 2023), 자기 검증(Miao 외, 2023; Jiang 외, 2023a; Weng 외, 2022) 등 시스템에서 추론 단계를 확장하여 결과를 개선하는 여러 접근 방식이 있다. 후자는 수학 문제에 대한 답이 주어졌을 때 (가려진) 문제를 예측하고 이것이 정답이라는 증거로 사용하려고 한다.
3. CHAIN-OF-VERIFICATION
Our approach assumes access to a base LLM that – despite potentially being prone to hallucination – is capable of being prompted with general instructions in either a few-shot or zero-shot fashion. A key assumption of our method is that this language model, when suitably prompted, can both generate and execute a plan of how to verify itself in order to check its own work, and finally incorporate this analysis into an improved response.
Our overall process, which we call Chain-of-Verification (CoVe), thus performs four core steps:
우리 방법은 잠재적으로 환각이 발생하기 쉽지만 퓨샷 또는 제로샷 방식으로 일반적인 지침instructions 을 프롬프트할 수 있는 기본 LLM에 액세스할 수 있다고 가정한다. 우리 방법의 핵심 가정은 이 언어 모델이 적절한 프롬프트가 주어지면 자신의 작업을 확인하기 위해 스스로 검증하는 방법에 대한 계획을 생성하고 실행할 수 있으며, 최종적으로 이 분석을 개선된 응답에 통합할 수 있다는 것이다.
- Generate Baseline Response: Given a query, generate the response using the LLM.
- Plan Verifications: Given both query and baseline response, generate a list of verification questions that could help to self-analyze if there are any mistakes in the original response.
- Execute Verifications: Answer each verification question in turn, and hence check the answer against the original response to check for inconsistencies or mistakes.
- Generate Final Verified Response: Given the discovered inconsistencies (if any), generate a revised response incorporating the verification results.
1)기준 응답 생성: 쿼리가 주어지면 LLM을 사용하여 응답을 생성한다.
2)검증 계획: 쿼리와 기준 응답이 모두 주어지면 원본 응답에 오류가 있는지 자체 분석하는 데 도움이 될 수 있는 검증 질문 목록을 생성한다.
3)검증을 실행한다: 각 검증 질문에 차례로 답변하여 원본 응답과 대조하여 불일치나 실수가 있는지 확인한다.
4)최종 확인된 응답 생성: 발견된 불일치(있는 경우)가 있으면 검증 결과를 반영하여 수정된 응답을 생성한다.
Each of these steps is performed by prompting the same LLM in different ways to obtain the desired response. While steps (1), (2) and (4) all can be invoked with a single prompt, we investigate variations of step (3) including joint, 2-step and factored versions. These variants either involve a single prompt, two prompts or else independent prompts per question, where more sophisticated decomposition can yield improved results.
We describe these steps in more detail below. An overview of the approach is illustrated in Figure 1, and in the Appendix in Figure 3.
이러한 각 단계는 원하는 응답을 얻기 위해 동일한 LLM을 다른 방식으로 프롬프트하여 수행된다. (1), (2), (4) 단계는 모두 단일 프롬프트로 호출할 수 있지만, 공동, 2단계, 팩터 버전 등 (3)단계의 변형을 조사한다. 이러한 변형에는 단일 프롬프트, 두 개의 프롬프트 또는 문제당 독립적인 프롬프트가 포함되며, 보다 정교하게 세분화하면 더 나은 결과를 얻을 수 있다.
아래에서 이러한 단계에 대해 자세히 설명한다. 접근 방식에 대한 개요는 그림 1과 부록의 그림 3에 나와 있다.
3.1 BASELINE RESPONSE
Given a query, we generate left-to-right as usual using the LLM, with no special tricks. While this is the first step in the CoVe pipeline, it also serves as the baseline we wish to improve in our experiments (i.e., we will directly compare this baseline response with the final verified response from our overall method).
쿼리가 주어지면 특별한 트릭 없이 평소와 같이 LLM을 사용하여 왼쪽에서 오른쪽으로 생성한다. 이것은 CoVe 파이프라인의 첫 번째 단계이지만, 실험에서 개선하고자 하는 기준선의 역할도 한다(즉, 이 기준선 응답을 전체 방법에서 최종적으로 검증된 응답과 직접 비교할 것이다).
Given such baseline generations are typically prone to hallucination, CoVe attempts to identify these hallucinations, and correct them, in the following steps.
이러한 기준선 생성은 일반적으로 환각이 발생하기 쉽기 때문에 CoVe는 다음 단계에서 이러한 환각을 식별하고 이를 수정하려고 시도한다.
3.2 PLAN VERIFICATIONS
Conditioned on the original query and the baseline response, the model is prompted to generate a series of verification questions that test the factual claims in the original baseline response. For example if part of a longform model response contains the statement “The Mexican–American War was an armed conflict between the United States and Mexico from 1846 to 1848”, then one possible verification question to check those dates could be “When did the Mexican American war start and end?”. We note that verification questions are not templated and the language model is free to phrase these in any form it wants, and they also do not have to closely match the phrasing of the original text.
In our experiments, we perform such verification planning by providing a few-shot prompt of (response, verification) demonstrations to our LLM. See section 8 for the few-shot prompts we will use in our experiments. We note it is also possible with a sufficiently performant instruction-following LLM that this could be performed zero-shot.
원래 쿼리와 기준 응답에 따라 모델에 원래 기준 응답의 사실 주장을 테스트하는 일련의 확인 질문을 생성하라는 메시지가 표시된다. 예를 들어 긴 형식의 모델 응답에 "멕시코-아메리카 전쟁은 1846년부터 1848년까지 미국과 멕시코 간의 무력 충돌이었다"라는 문장이 포함된 경우, 해당 날짜를 확인하기 위한 확인 질문 중 하나는 "멕시코-아메리카 전쟁은 언제 시작되고 끝났습니까?"일 수 있다. 확인 질문은 템플릿이 없으며 언어 모델이 원하는 형태로 자유롭게 표현할 수 있으며, 원본 텍스트의 문구와 정확히 일치할 필요도 없다.
실험에서는 LLM에 (응답, 검증) 데모의 퓨샷 프롬프트를 제공하여 이러한 검증 계획을 수행했다. 실험에서 사용할 퓨샷 프롬프트는 섹션 8을 참조하라. 충분한 성능의 명령 추종instruction-following LLM을 사용하면 제로 샷으로 수행할 수도 있다.
3.3 EXECUTE VERIFICATIONS
Given the planned verification questions, the next step is to answer them in order to assess if any hallucinations exist. While techniques such as retrieval-augmentation could be used in this process, such as verification via search engine, in this work we do not explore tool-use. Instead, we consider only using the LLM itself in all steps of CoVe, hence the model is used to check its own work. We investigate several variants of verification execution, called joint, 2-Step, factored and factor+revise.
계획된 검증 질문이 주어지면 다음 단계는 환각이 존재하는지 평가하기 위해 질문에 답하는 것이다. 이 과정에서 검색 엔진을 통한 검증과 같은 검색 증강retrieval-augmentation과 같은 기술을 사용할 수 있지만, 이 작업에서는 도구 사용을 고려하지 않았다. 대신 CoVe의 모든 단계에서 LLM 자체를 사용하는 것을 고려하며, 따라서 모델 자체의 작업을 확인하는 데 사용된다. 공동, 2단계, 팩터, 팩터+수정 등 여러 가지 검증 실행 변형을 조사한다.
Joint In the joint method, the planning and execution (steps 2 and 3) are accomplished by using a single LLM prompt, whereby the few-shot demonstrations include both verification questions and their answers immediately after the questions. In this approach separate prompts are not needed.
공동 방식에서는 계획과 실행(2단계와 3단계)이 단일 LLM 프롬프트를 사용하여 이루어지며, 퓨샷으로 구성된 데모에는 확인 질문과 질문 직후의 답변이 모두 포함된다. 이 방식에서는 별도의 프롬프트가 필요하지 않다.
2-Step A potential disadvantage of the joint method is that because the verification questions must condition on the baseline response in the LLM context, and the method is joint, the verification answers have to condition on the initial response as well. This may increase the likelihood of repetition, another known issue of modern LLMs (Holtzman et al., 2019). This means the verification questions might hallucinate similarly to the original baseline response, which defeats the purpose. We hence instead separate the planning and execution into separate steps, both with their own LLM prompt. The planning prompt conditions on the baseline response in the first step. The verification questions generated from planning are answered in the second step, where crucially the context given to the LLM prompt only contains the questions, and not the original baseline response and hence cannot repeat those answers directly.
2단계 공동joint 방법의 잠재적 단점은 LLM 맥락에서 검증 질문이 기준 응답을 조건으로 해야 하고 방법이 공동이기 때문에 검증 답변도 초기 응답을 기준으로 맞춰야 한다는 것이다. 이는 LLM의 또 다른 문제점으로 알려진 반복repetition 가능성을 높일 수 있다(Holtzman et al., 2019). 즉, 검증 질문이 원래의 기준 응답과 유사하게 환각될 수 있으며, 이는 목적에 어긋난다. 따라서 대신 계획과 실행을 별도의 단계로 분리하고, 두 단계 모두 고유한 LLM 프롬프트를 사용한다. 계획 프롬프트는 첫 번째 단계의 기준 응답에 대한 조건이다. 계획에서 생성된 검증 질문은 두 번째 단계에서 답변되는데, 결정적으로 LLM 프롬프트에 주어진 컨텍스트에는 원래 기준 응답이 아닌 질문만 포함되어 있으므로 해당 답변을 직접 반복할 수 없다.
Factored Another, more sophisticated approach, is to answer all questions independently as separate prompts. Again, crucially, those prompts do not contain the original baseline response and are hence not prone to simply copying or repeating it. The factored approach has the further advantage of removing any potential interference not only from the baseline response, but also between answer contexts, and is somewhat related to the recent (concurrent) work of Radhakrishnan et al. (2023) for subquestion answering by factored decomposition, hence we adopt their naming. It can also potentially handle more verification questions by virtue of them not all having to fit with the same single context. While this is potentially more computationally expensive, requiring the execution of many more LLM prompts, they can be run in parallel, and hence be batched. In order to do this, we first have to take the set of generated questions from subsection 3.2 and parse them into separate questions, which is a relatively easy task as the few-shot demonstrations we provide indicate they should be generated as a comma-separated list. We can then split them out into separate LLM prompts.
팩터Factored . 보다 정교한 또 다른 접근 방식은 모든 질문에 독립적으로 별도의 프롬프트로 답하는 것이다. 다시 말하지만, 이러한 프롬프트에는 원래의 기준 응답이 포함되어 있지 않으므로 단순히 복사하거나 반복하는 경향이 없다. 팩터 접근 방식은 기준 응답뿐만 아니라 답변 컨텍스트 간의 잠재적 간섭을 제거할 수 있다는 추가적인 장점이 있으며, 팩터 분해factored decomposition에 의한 하위 질문 답변에 대한 Radhakrishnan 외(2023)의 최근(동시) 연구와 어느 정도 연관성이 있으므로 이 이름을 채택했다. 또한, 모든 질문이 동일한 단일 컨텍스트에 맞지 않아도 되기 때문에 잠재적으로 더 많은 검증 질문을 처리할 수 있다. 이는 잠재적으로 더 많은 LLM 프롬프트를 실행해야 하므로 계산 비용이 더 많이 들 수 있지만, 병렬로 실행할 수 있으므로 일괄 처리할 수 있다. 이를 위해서는 먼저 하위 섹션 3.2에서 생성된 질문 세트를 가져와서 개별 질문으로 파싱해야 하는데, 쉼표로 구분된 목록으로 생성해야 한다는 것을 보여주는 몇 가지 데모에서는 비교적 쉬운 작업이다. 그런 다음 이를 별도의 LLM 프롬프트로 분할할 수 있다.
Factor+Revise After answering the verification questions, the overall CoVe pipeline then has to either implicitly or explicitly cross-check whether those answers indicate an inconsistency with the original responses. In the factor+revise approach, we execute this as a deliberate step via an extra LLM prompt, which may make it easier for the final system to reason about this step explicitly. Differently to answering the verification questions, the cross-checking phase needs to condition on both the baseline response and the verification question and answer. We thus execute this as separate LLM prompts, one “cross-check” prompt for each question, with again a set of few-shot demonstrations showing the desired output. For example if the original baseline response contained the phrase “It followed in the wake of the 1845 U.S. annexation of Texas. . . ” and CoVe generated a verification question When did Texas secede from Mexico? which was answered with 1836 then an inconsistency should be detected by this step.
요인+수정 검증 질문에 답변한 후, 전체 CoVe 파이프라인은 해당 답변이 원래 답변과 불일치하는지 여부를 암시적으로 또는 명시적으로 교차 확인해야 한다. 요인+수정 접근 방식에서는 추가 LLM 프롬프트를 통해 이 작업을 의도적인 단계로 실행하므로 최종 시스템에서 이 단계를 명시적으로 추론하기가 더 쉬워질 수 있다. 검증 질문에 대한 답변과는 달리 교차 확인 단계에서는 기준 응답과 검증 질문 및 답변 모두에 대한 조건이 필요하다. 따라서 각 질문에 대해 하나의 "교차 확인" 프롬프트와 함께 원하는 출력을 보여주는 몇 개의 쇼트 데모 세트를 사용하여 이를 별도의 LLM 프롬프트로 실행한다. 예를 들어, 원래 기준 응답에 "1845년 미국이 텍사스를 합병한 이후. . . "라는 문구가 포함되어 있고 CoVe가 "텍사스는 언제 멕시코에서 분리 독립했나요?"라는 검증 질문을 생성했는데 1836년이라고 대답했다면 이 단계에서 불일치를 감지해야 한다.
3.4. FINAL VERIFIED RESPONSE
Finally, the improved response that takes verification into account is generated. This is executed by a final few-shot prompt where the context takes into account all of the previous reasoning steps, the baseline response and verification question answer pairs, so that the corrections can take place. If the Factor+Revise approach is used from subsection 3.3 then the output of the cross-check inconsistency detection is provided as well.
마지막으로 검증을 고려한 개선된 응답이 생성된다. 이는 이전의 모든 추론 단계, 기준 응답 및 검증 문제 답안 쌍을 고려하여 수정이 이루어질 수 있도록 문맥에서 마지막 몇 번의 프롬프트에 의해 실행된다. 하위 섹션 3.3에서 요인+수정 접근 방식을 사용하는 경우 교차 확인 불일치 감지 결과도 함께 제공된다.
4. EXPERIMENTS
We use various experimental benchmarks to measure the efficacy of CoVe in reducing hallucination, comparing against a number of baselines.
다양한 실험 벤치마크를 사용하여 여러 기준선과 비교하여 환각 감소에 대한 CoVe의 효과를 측정한다.
4.1. TASKS
The benchmarks we use range from list-based questions where the required answer is a set of entities, to where the answer is a longform generation of multiple freeform sentences.
우리가 사용하는 벤치마크는 필요한 답변이 엔티티 집합인 목록 기반 질문부터 여러 자유형 문장으로 구성된 긴 형식의 답변이 필요한 경우까지 다양한다.
4.1.1 WIKIDATA
We start by testing CoVe on a set of automatically generated questions using the Wikidata API1. We create list questions of the form: “Who are some [Profession]s who were born in [City]?”. For example, “Who are some politicians who were born in Boston?”. The answer to these questions is a set of entities, where the gold list is obtained from the Wikidata knowledge base. This results in a dataset of 56 test questions, each typically containing 600 known gold entities, but typically an LLM will produce a much shorter list. We then use the precision metric (micro-averaged) to measure performance, in addition to reporting the averaged number of positive and negative entities produced.
먼저 위키데이터 API1를 사용하여 자동으로 생성된 질문 세트에 대해 CoVe를 테스트한다. 다음과 같은 형식의 목록 질문을 생성한다: "[도시]에서 태어난 [직업]은 누구인가요?". 예를 들어, "보스턴에서 태어난 정치인은 누구인가요?". 이러한 질문에 대한 답은 엔티티 집합이며, 골드 목록은 위키데이터 지식 베이스에서 얻다. 이렇게 하면 56개의 테스트 질문으로 구성된 데이터 세트가 생성되며, 각 질문에는 일반적으로 600개의 알려진 골드 엔티티가 포함되지만, 일반적으로 LLM은 훨씬 더 짧은 목록을 생성한다. 그런 다음 정밀도 메트릭(마이크로 평균)을 사용하여 성능을 측정하고, 생성된 긍정 및 부정 엔티티의 평균 수를 보고한다.
4.1.2 WIKI-CATEGORY LIST
We then proceed to a harder set-generation task. We use the QUEST (Malaviya et al., 2023) dataset that was created using Wikipedia Category lists. We convert these category names to questions by simply prepending a “Name some”. Owing to the varied questions such as Name some Mexican animated horror films or Name some Endemic orchids of Vietnam we believe this task can pose a greater challenge. We collate all examples in the dataset that do not require logical operations to create a set of 55 test questions each having 8˜ answers. Similar to the Wikidata task, we measure precision (micro-averaged) to measure performance, in addition to reporting the averaged number of positive and negative entities produced.
그런 다음 더 어려운 집합 생성 작업을 진행한다. 위키백과 카테고리 목록을 사용하여 생성된 QUEST(Malaviya et al., 2023) 데이터셋을 사용한다. 이러한 카테고리 이름 앞에 "이름 몇 개"를 붙여서 질문으로 변환한다. 멕시코 애니메이션 공포 영화 이름 몇 개 또는 베트남의 고유 난초 이름 몇 개와 같은 다양한 질문으로 인해 이 작업은 더 큰 도전이 될 수 있다고 생각한다. 데이터 세트에서 논리적 연산을 필요로 하지 않는 모든 예시를 수집하여 각각 8개씩의 답이 있는 55개의 테스트 문제 세트를 만든다. 위키데이터 작업과 유사하게, 우리는 생산된 양수 및 음수 개체의 평균 수를 보고하는 것 외에도 성능을 측정하기 위해 정밀도(마이크로 평균)를 측정한다.
4.1.3 MULTISPANQA
We next test our approach on an reading comprehension benchmark, MultiSpanQA (Li et al., 2022). MultiSpanQA comprises of questions that have multiple independent answers (derived from a series of multiple discontiguous spans in the text, with questions originally from the Natural Questions dataset). We consider a closed-book setting, where we do not provide supporting documents, and hence consider a subset of questions which are factoid-based, so that our base LLM is more likely to be able to answer them. We thus use a test set of 418 questions with shorter answers per span (up to 3 tokens per item). For example, Q: Who invented the first printing press and in what year?, A: Johannes Gutenberg, 1450.
다음으로, 우리는 독해력 벤치마크인 MultiSpanQA(Li et al., 2022)에서 우리의 접근 방식을 테스트한다. MultiSpanQA는 여러 개의 독립적인 답변이 있는 질문(텍스트의 일련의 불연속적인 여러 구간에서 파생된 질문으로, 원래 자연 질문Natural Questions 데이터 세트에서 가져온 질문)으로 구성되어있다. 지원 문서를 제공하지 않는 폐쇄형 책 설정을 고려하므로 기본 LLM이 답변할 수 있는 가능성이 더 높은 사실 기반의 질문의 하위 집합을 고려한다. 따라서 한 문항당 최대 3개의 토큰을 포함하는 짧은 답변을 가진 418개의 질문으로 구성된 테스트 세트를 사용한다. 예를 들어, Q: 최초의 인쇄기를 발명한 사람은 누구이며 몇 년도에 발명되었나? A: 요하네스 구텐베르크, 1450년.
Wikidata (Easier)
Wiki-Category list (Harder)
| LLM | Method | Prec. (↑) | Pos. | Neg. | Prec. (↑) | Pos. | Neg. |
| Llama 2 70B Chat | Zero-shot | 0.12 | 0.55 | 3.93 | 0.05 | 0.35 | 6.85 |
| Llama 2 70B Chat | CoT | 0.08 | 0.75 | 8.92 | 0.03 | 0.30 | 11.1 |
| Llama 65B | Few-shot | 0.17 | 0.59 | 2.95 | 0.12 | 0.55 | 4.05 |
| Llama 65B | CoVe (joint) | 0.29 | 0.41 | 0.98 | 0.15 | 0.30 | 1.69 |
| Llama 65B | CoVe (two-step) | 0.36 | 0.38 | 0.68 | 0.21 | 0.50 | 0.52 |
| Llama 65B | CoVe (factored) | 0.32 | 0.38 | 0.79 | 0.22 | 0.52 | 1.52 |
Table 1: Test Precision and average number of positive and negative (hallucination) entities for list-based questions on the Wikidata and Wiki-Category list tasks.
표 1: 위키데이터 및 위키 카테고리 목록 작업의 목록 기반 질문에 대한 테스트 정확도 및 평균 긍정 및 부정(환각) 개체 수이다.
4.1.4 LONGFORM GENERATION OF BIOGRAPHIES
We next validate the performance of CoVe on longform text generation. In this setting, we evaluate our method on generating biographies, adopting the benchmark proposed in by Min et al. (2023). Here the model is simply prompted to generate a biography of a selected entity using the prompt: “Tell me a bio of <entity>”. We evaluate the efficacy of our approach using the FACTSCORE metric (Min et al., 2023) developed in that work, which uses a retrieval-augmented language model to fact-check the response (Instruct-Llama, “Llama + Retrieval + NP”), which they showed correlates well with human judgments.
다음으로 롱폼 텍스트 생성에 대한 CoVe의 성능을 검증한다. 이 설정에서는 Min et al.(2023)에서 제안한 벤치마크를 채택하여 전기 생성에 대한 방법을 평가한다. 여기서는 모델에 프롬프트를 사용하여 선택한 인물의 전기를 생성하라는 메시지가 표시된다: "<개체>의 약력을 알려주세요". 이 연구에서 개발된 검색 증강 언어 모델을 사용하여 응답을 팩트체크하는 FACTSCORE 메트릭(Min et al., 2023)을 사용하여 접근 방식의 유효성을 평가했는데, 이 메트릭은 사람의 판단과 잘 상관관계가 있는 것으로 나타났다(Instruct-Llama, "Llama + Retrieval + NP").
4.2 BASELINES
We use Llama 65B, a strong open model as our base LLM (Touvron et al., 2023a), and use greedy decoding for all models. As Llama 65B is not instruction fine-tuned, we employ few-shot examples particular to each task for measuring performance on each of our benchmarks. This serves as our main baseline which CoVe tries to improve upon. CoVe uses the same Llama 65B base, but includes, for the same few-shot examples, demonstrations of verification questions and final verified responses, following Figure 1 and section 3. Thus, we measure the ability to improve over the original baseline response for the same LLM. For CoVe, we compare different variants, particularly the joint and factored versions on all tasks.
우리는 Llama 65B를 기본 LLM으로 사용하며(Touvron et al., 2023a), 모든 모델에 대해 탐욕적greedy 디코딩을 사용한다. Llama 65B는 인스트럭션이 미세 조정되지 않았기 때문에 각 벤치마크에서 성능을 측정하기 위해 각 작업에 특화된 퓨샷 예제를 사용한다. 이는 CoVe가 개선하고자 하는 주요 기준선 역할을 한다. CoVe는 동일한 Llama 65B 베이스를 사용하지만, 그림 1과 섹션 3에 따라 동일한 퓨샷 예제에 대해 검증 질문과 최종적으로 검증된 응답에 대한 데모를 포함한다. 따라서 동일한 LLM에 대해 원래의 기준 응답보다 개선된 능력을 측정한다. CoVe는 모든 작업에서 합동 및 팩터별 버전과 같은 다양한 변형을 비교한다.
We also compare to Llama instruction fine-tuned models, for which we use Llama 2 (Touvron et al., 2023b). We measure both zero-shot performance on the task, or zero-shot with chain-of-thought by adding “Let’s think step by step” to the zero-shot prompt. We find that the instruction fine-tuned models tend to generate extraneous content when queried. This can especially be a problem for the list-based tasks. To deal with this we add an extra line to our prompt: “List only the answers separated by a comma”. We also add another layer of post-processing to extract the answers by using an off-the-shelf NER model to further avoid this issue as this helped. However, we still expect few-shot to improve over this, especially for tasks like Multi-Span-QA where the answers are not all named entities, and the few-shot examples effectively show the domain of the task.
또한 Llama 2를 사용하는 Llama 인스트럭션 미세 조정 모델과 비교한다(Touvron et al., 2023b). 과제에 대한 제로 샷 성능과 제로 샷 프롬프트에 "단계별로 생각해 봅시다"를 추가하여 연쇄적 사고와 함께 제로 샷을 모두 측정한다. 우리는 명령어 미세 조정 모델이 쿼리 시 불필요한 콘텐츠를 생성하는 경향이 있음을 발견했다. 이는 특히 목록 기반 작업에서 문제가 될 수 있다. 이 문제를 해결하기 위해 프롬프트에 한 줄을 추가했다: "쉼표로 구분된 답변만 나열". 또한 기성 NER 모델을 사용하여 답변을 추출하는 또 다른 후처리 계층을 추가하여 이 문제를 더욱 방지할 수 있었다. 그러나 답변이 모두 명명된 엔티티가 아니며 퓨샷 예제에서 작업의 도메인을 효과적으로 보여주지 못하는 멀티스팬-QA와 같은 작업의 경우, 퓨샷이 이보다 더 개선될 것으로 기대한다.
For the longform generation of biographies we also compare to several existing model results reported in Min et al. (2023), in particular InstructGPT (Ouyang et al., 2022), ChatGPT 2 and PerplexityAI 3.
또한 전기의 롱폼 생성을 위해 민 외(2023)에서 보고된 여러 기존 모델 결과, 특히 InstructGPT (Ouyang 외, 2022), ChatGPT 2 및 PerplexityAI 3과 비교했다.
4.3 RESULTS
We are interested in empirically answering the following research questions:
RQ1 Can COVE effectively reduce the rate of hallucinatory content produced by the LLM?
RQ2 Can COVE be used to fix or remove incorrect generations without decreasing the amount of correct content?
저희는 다음과 같은 연구 질문에 경험적으로 답하고자 한다:
RQ1 COVE가 LLM에서 생성되는 환각 콘텐츠의 비율을 효과적으로 줄일 수 있는가?
RQ2 올바른 콘텐츠의 양을 줄이지 않고 잘못된 세대를 수정하거나 제거하는 데 COVE를 사용할 수 있나요?
2https://openai.com/blog/chatgpt 3www.perplexity.ai
| LLM | Method | F1 (↑) | Prec. | Rec. |
| Llama 2 70B Chat | Zero-shot | 0.20 | 0.13 | 0.40 |
| Llama 2 70B Chat | CoT | 0.17 | 0.11 | 0.37 |
| Llama 65B | Few-shot | 0.39 | 0.40 | 0.38 |
| Llama 65B | CoVe (joint) | 0.46 | 0.50 | 0.42 |
| Llama 65B | CoVe (factored) | 0.48 | 0.50 | 0.46 |
Table 2: Closed book MultiSpanQA test performance, comparing CoVe with various baselines.
표 2: 비공개 멀티스팬QA 테스트 성능, CoVe와 다양한 기준선 비교.
| LLM | Method | FACTSCORE. (↑) | Avg. # facts |
| InstructGPT∗ | Zero-shot | 41.1 | 26.3 |
| ChatGPT∗ | Zero-shot | 58.7 | 34.7 |
| PerplexityAI∗ | Retrieval-based | 61.6 | 40.8 |
| Llama 2 70B Chat | Zero-shot | 41.3 | 64.9 |
| Llama 2 70B Chat | CoT | 41.1 | 49.0 |
| Llama 65B | Few-shot | 55.9 | 16.6 |
| Llama 65B | CoVe (joint) | 60.8 | 12.8 |
| Llama 65B | CoVe (factored) | 63.7 | 11.7 |
| Llama 65B | CoVe (factor+revise) | 71.4 | 12.3 |
Table 3: Longform generation of biographies with metrics defined from Min et al. (2023). Models marked with ∗ are reported from previous work. FACTSCORE automatically computed using “Instruct- Llama” ( Retrieve → LM + NP), the best open-access model.
표 3: Min et al. (2023)에서 정의한 메트릭을 사용한 전기의 롱폼 생성. 로 표시된 모델은 이전 연구에서 보고된 것이다. 팩트스코어는 오픈액세스 모델 중 가장 우수한 "Instruct- Llama"(검색 → LM + NP)를 사용하여 자동으로 계산되었다.
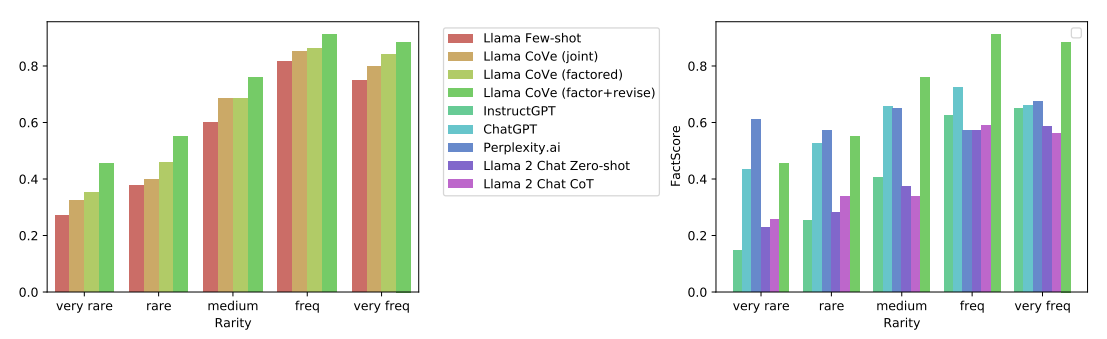
Figure 2: FACTSCORE performance distribution across head, torso and tail facts for CoVe variants and various baselines on longform generation of biographies.
그림 2: 롱폼 전기 생성의 다양한 기준선 및 CoVe 변종에 대한 머리, 몸통, 꼬리 팩트 전반의 팩트스코어 성능 분포.
Our main results across the four benchmark tasks are given in Table 1, Table 2 and Table 3, and our main findings are as follows.
네 가지 벤치마크 과제에 대한 주요 결과는 표1, 표2, 표3에 나와 있으며, 주요 결과는 다음과 같다.
CoVe improves precision on list-based answer tasks We find that CoVe provides large gains in precision on the list-based tasks, e.g. more than doubles the precision from the Llama 65B few-shot baseline for the Wikidata task (from 0.17 to 0.36). We find from the positive and negative breakdown that there is a large reduction in the number of hallucinated answers (negatives: 2.95 → 0.68) while only a relatively small reduction in the number of non-hallucinations (positives: 0.59 → 0.38).
목록 기반 답변 작업의 정확도를 향상시키는 CoVe 위키데이터 작업의 경우, 목록 기반 작업의 정확도가 Llama 65B 퓨샷 기준선보다 두 배 이상 향상(0.17에서 0.36으로)되는 등 CoVe가 목록 기반 작업의 정확도를 크게 향상시키는 것으로 나타났다. 긍정과 부정으로 분류한 결과, 오답의 수가 크게 감소한 반면(부정: 2.95 → 0.68), 다음과 같이 비교적 적은 수의 오답만 감소했다.
환각이 아닌 답변의 수는 상대적으로 소폭 감소했다(긍정: 0.59 → 0.38).
CoVe improves performance on closed book QA We also find that CoVe brings improvements in general QA problems, as measured on MultiSpanQA. We observe a 23% improvement in F1 over the few-shot baseline (0.39 0.48), where the improvements come from gains in both precision and recall.
비공개 QA의 성능을 개선하는 CoVe 멀티스팬QA에서 측정한 결과, CoVe가 일반적인 QA 문제에서도 개선 효과를 가져온다는 사실을 발견했다. F1은 퓨샷 기준선(0.39 0.48)에 비해 23% 개선되었으며, 이러한 개선은 정확도와 리콜 모두에서 비롯된 것이다.
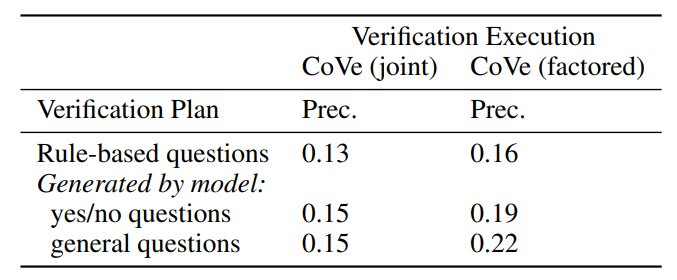
Table 4: Comparison of various CoVe verification plan strategies (rows) and verification execution techniques (columns) on the Wiki-Category task.
표 4: 위키 카테고리 작업에 대한 다양한 CoVe 검증 계획 전략(행)과 검증 실행 기법(열)의 비교.
CoVe improves precision on longform generation These results also extend to longform genera- tion, where we actually see larger gains than in the QA setting. FACTSCORE increases 28% (55.9 71.4) from the few-shot baseline, with again only a relatively small reduction in average number of facts provided (16.6 12.3). We also show the breakdown of improvements across facts in Figure 2, where one can see CoVe improves results for both rare and more frequent facts.
CoVe는 롱폼 생성 시 정확도를 향상시킨다. 이러한 결과는 롱폼 생성에도 적용되며, 실제로 QA 환경보다 더 큰 개선 효과를 볼 수 있다. 팩트 스코어는 퓨샷을 기준으로 했을 때보다 28%(55.9 71.4) 증가했으며, 제공된 평균 팩트 수(16.6개 12.3개)는 비교적 적게 감소했다. 또한 그림 2에서 팩트별로 개선된 내역을 확인할 수 있는데, 희귀한 팩트 및 빈번한 팩트 모두에서 CoVe를 통해 개선된 결과를 확인할 수 있다.
Instruction-tuning and CoT do not reduce hallucinations We find that the few-shot baseline that employs a pre-trained Llama model outperforms Llama 2 Chat, an instruction tuned model, across all the tasks. The few-shot examples lead the model to give outputs in line with those expected for the task, whereas general instruction tuning produces more hallucinations or incorrect outputs. Standard chain-of-thought (CoT) prompting also fails to improve the results for these tasks. While CoT has proven to help for reasoning tasks, it seems less appropriate for the issue of hallucination we measure in this work.
인스트럭션 튜닝과 CoT는 환각을 줄이지 못한다. 사전 학습된 라마 모델을 사용하는 퓨샷 기준이 인스트럭션 튜닝 모델인 라마 2 채팅보다 모든 작업에서 더 나은 성능을 발휘하는 것으로 나타났다. 일반적인 인스트럭션 튜닝은 더 많은 환각이나 부정확한 출력을 생성하는 반면, 퓨샷 예제는 모델이 작업에 대해 예상되는 것과 일치하는 출력을 제공하도록 유도한다. 표준 연쇄 사고(CoT) 프롬프트 역시 이러한 작업의 결과를 개선하지 못한다. CoT는 추론 과제에 도움이 되는 것으로 입증되었지만, 이 연구에서 측정하는 환각 문제에는 적합하지 않은 것으로 보인다.
Factored and 2-step CoVe improve performance We observe a consistent performance improve- ment across all tasks from applying the factored CoVe approach compared to joint CoVe. For example improvement from 60.8 63.7 in FACTSCORE in longform generation. Similarly, the 2-step approach also outperforms the joint approach, as tested on the Wikidata and Wiki-Category list tasks, with 2-step giving the best results for Wikidata, and factored the best for Wiki-Category. All these results support our hypothesis that verifying questions should not attend to the original baseline response as they may be prone to repeating it (as the joint method can do).
팩터 및 2단계 CoVe를 통한 성능 향상. 공동 CoVe에 비해 팩터 CoVe 접근법을 적용했을 때 모든 작업에서 일관된 성능 향상을 관찰할 수 있다. 예를 들어, 롱폼 생성에서 팩트스코어를 적용하면 60.8에서 63.7로 개선되었다. 마찬가지로 위키데이터 및 위키 카테고리 목록 작업에서 테스트한 결과, 2단계 접근 방식이 공동 접근 방식보다 성능이 뛰어났으며, 위키데이터의 경우 2단계 접근 방식이 가장 좋은 결과를, 위키 카테고리의 경우 팩터가 가장 좋은 결과를 제공했다. 이러한 모든 결과는 공동 접근 방식에서처럼 검증 질문이 원래의 기준 응답을 반복하는 경향이 있기 때문에 원래의 기준 응답에 주목해서는 안 된다는 우리의 가설을 뒷받침한다.
Further explicit reasoning helps remove hallucinations In the longform generation task we also explore more sophisticated reasoning steps in the CoVe “factor+revise” method, which explicitly cross-checks whether verification answers indicate an inconsistency. We see large gains in the FACTSCORE metric from this further explicit reasoning from 63.7 (factored) 71.4 (factor+revise). This gives further indication that appropriate and explicit reasoning in LLMs can bring improvements in mitigating hallucinations.
보다 명시적인 추론이 환각을 제거하는 데 도움. 롱폼 생성 작업에서는 검증 답변이 불일치를 나타내는지 명시적으로 교차 확인하는 CoVe "요인+수정" 방법에서 보다 정교한 추론 단계도 살펴본다. 이러한 보다 명시적인 추론을 통해 FACTSCORE 지표가 63.7점(팩터)에서 71.4점(팩터+수정)으로 크게 향상되었다. 이는 LLM에서 적절하고 명시적인 추론이 환각을 완화하는 데 개선 효과를 가져올 수 있음을 시사한다.
CoVe-based Llama outperforms InstructGPT, ChatGPT and PerplexityAI On the longform generation task, our baseline few-shot Llama 65B is outperformed by the ChatGPT and PerplexityAI models in terms of the FACTSCORE metric. However, applying CoVe to the baseline Llama 65B lifts its performance above both ChatGPT and PerplexityAI, as well as outperforming InstructGPT. This is particularly impressive compared to PerplexityAI considering that is a model that can support its facts with retrieval-augmentation, whereas CoVe uses only the base language model itself with improved reasoning via deliberation (verification). However, we can see in Figure 2 PerplexityAI still outperforms CoVe for very rare facts where retrieval is essential, but CoVe outperforms PerplexityAI for more frequent facts. We note that some models produce less overall facts than others, however the FACTSCORE metric is normalized and hence comparable across models. We verified this experimentally by clipping Llama 2 70B chat’s output to present less facts (as it contains the largest number in its output out of all models), but this did not change its FACTSCORE substantially, e.g. clipping to 10 sentences increased its score from 41.3 42.7. We note the length of the generations of the few-shot-based models are essentially governed by the few-shot examples, which in-turn are constrained by the context length.
CoVe 기반 Llama, InstructGPT, ChatGPT, PerplexityAI를 능가하는 성능 롱폼 생성 작업에서 기본 모델인 퓨샷으로 구성된 Llama 65B는 FACTSCORE 메트릭 측면에서 ChatGPT와 PerplexityAI 모델보다 성능이 뛰어나다. 그러나 기준선인 Llama 65B에 CoVe를 적용하면 ChatGPT와 PerplexityAI를 모두 능가할 뿐만 아니라 InstructGPT를 능가하는 성능을 발휘한다. PerplexityAI는 검색 증강을 통해 사실을 뒷받침할 수 있는 모델인 반면, CoVe는 심의(검증)를 통해 추론을 개선한 기본 언어 모델 자체만을 사용한다는 점을 고려하면 특히 인상적인 결과이다. 그러나 그림 2에서 볼 수 있듯이 검색이 필수적인 매우 드문 사실에 대해서는 여전히 PerplexityAI가 CoVe보다 성능이 뛰어나지만, 보다 빈번한 사실에 대해서는 CoVe가 PerplexityAI보다 성능이 뛰어나다. 일부 모델은 다른 모델보다 전체 팩트 수를 적게 생성하지만, 팩트스코어 메트릭은 정규화되어 있어 모델 간에 비교할 수 있다. 실험적으로 Llama 2 70B 채팅의 출력을 잘라내어 더 적은 팩트를 제시(모든 모델 중 출력에 가장 많은 팩트가 포함되어 있음)함으로써 이를 확인했지만, 10문장으로 잘라내면 점수가 41.3에서 42.7로 증가하는 등 팩트스코어가 크게 변하지는 않았다. 퓨샷 기반 모델의 생성 길이는 본질적으로 퓨샷 예제에 의해 결정되며, 이는 다시 문맥 길이에 의해 제약을 받다.
Shortform verification questions are more accurately answered than longform queries In a longform response, LLMs are prone to generate a number of hallucinations. However, it can often be the case that the LLM itself would know these hallucinations are wrong if queried specifically for that individual fact, independent of the rest of the longform generation, see Figure 1, Figure 3, and section 9. This can be seen quantitatively on the Wikidata task, where only 17% of the Llama few-shot baseline answer entities are correct in list-based questions. However, when querying each individual entity via a verification question, we find ∼70% are correctly answered.
숏폼 확인 질문이 롱폼 쿼리보다 더 정확한 답변 롱폼 응답에서 LLM은 여러 가지 착각을 일으키기 쉽다. 그러나 나머지 롱폼 생성과는 별개로 개별 사실에 대해 구체적으로 쿼리하면 LLM 자체가 이러한 환각이 잘못된 것임을 알 수 있는 경우가 종종 있다(그림 1, 그림 3 및 섹션 9 참조). 이는 위키데이터 작업에서 정량적으로 확인할 수 있는데, 목록 기반 질문에서 라마 소수점 기준 답변 엔티티 중 17%만이 정답이다. 그러나 검증 질문을 통해 각 개별 엔티티를 쿼리할 경우 약 70%가 정답을 맞추는 것으로 나타났다.
LLM-based verification questions outperforms heuristics In our method, CoVe, the verification questions are generated by the LLM dependent on the task. We compare the quality of these questions to heuristically constructed ones in order to measure their quality, by replacing the LLM questions with templated yes/no questions of the form “Does X answer the question” for list-based questions with elements X in the answer. Results on the Wiki-Category task, given in Table 4, show a reduced precision with rule-based verification questions. We believe this difference would be larger for longform generation where the types of required verification questions can be more diverse, and LLM-based verification becomes even more necessary.
휴리스틱보다 성능이 뛰어난 LLM 기반 검증 질문 당사의 방법인 CoVe에서는 작업에 따라 LLM에 의해 검증 질문이 생성된다. 이러한 질문의 품질을 측정하기 위해 목록 기반 질문에 대해 "X가 질문에 답하는가"라는 형식의 템플릿화된 예/아니요 질문으로 LLM 질문을 대체하여 이러한 질문의 품질을 휴리스틱하게 구성된 질문과 비교한다. 표 4에 제시된 위키 카테고리 작업의 결과는 규칙 기반 검증 질문으로 인해 정확도가 감소했음을 보여준다. 필요한 검증 질문의 유형이 더 다양할 수 있고 LLM 기반 검증이 더욱 필요해지는 롱폼 생성의 경우 이러한 차이는 더 커질 것으로 예상된다.
Open verification questions outperform yes/no-based questions In our main experiments we use verification questions where the expected answers are true facts. An alternative setup is to include the fact as part of the verification question and ask it in a yes/no answer format. We evaluate this difference in Table 4, and find that yes/no type questions perform worse for the factored version of CoVe. Some anecdotal examples are included in Appendix section 9 for ChatGPT where we find the model tends to agree with facts in a yes/no question format whether they are right or wrong.
개방형 확인 질문이 예/아니오 기반 질문보다 우수한 성능 주요 실험에서는 예상 답변이 사실인 확인 질문을 사용한다. 다른 설정은 사실을 확인 질문의 일부로 포함시키고 예/아니오 답변 형식으로 질문하는 것이다. 표 4에서 이러한 차이를 평가한 결과, 예/아니오 유형의 질문이 팩터 버전의 CoVe에서 더 낮은 성과를 보인다는 것을 알 수 있다. 예/아니오 질문 형식의 사실에 대해 옳고 그름에 관계없이 동의하는 경향을 보이는 ChatGPT에 대한 부록 섹션 9에 몇 가지 일화적인 예가 나와 있다.
5. CONCLUSION
We introduced Chain-of-Verification (CoVe), an approach to reduce hallucinations in a large language model by deliberating on its own responses and self-correcting them. In particular, we showed that models are able to answer verification questions with higher accuracy than when answering the original query by breaking down the verification into a set of simpler questions. Secondly, when answering the set of verification questions, we showed that controlling the attention of the model so that it cannot attend to its previous answers (factored CoVe) helps alleviate copying the same hallucinations. Overall, our method provides substantial performance gains over the original language model response just by asking the same model to deliberate on (verify) its answer. An obvious extension to our work is to equip CoVe with tool-use, e.g., to use retrieval augmentation in the verification execution step which would likely bring further gains.
대규모 언어 모델에서 답변을 스스로 검토/수정하여 오류를 줄이기 위한 접근 방식인 CoVe (Chain-of-Verification)를 도입했다. 특히, 검증을 더 간단한 질문으로 세분화하여 모델이 원래 쿼리에 답변할 때보다 더 높은 정확도로 검증 질문에 답변할 수 있음을 보여주었다. 둘째, 일련의 검증 질문에 답할 때 모델이 이전 답변에 주의를 기울이지 않도록 주의력을 제어(팩터 CoVe)하면 동일한 환각을 모방하는 것을 완화하는 데 도움이 된다는 것을 보여주었다. 전반적으로, 우리의 방법은 동일한 모델에게 답변을 숙고(검증)하도록 요청하는 것만으로도 원래 언어 모델 응답에 비해 상당한 성능 향상을 제공한다. 이 작업의 분명한 확장은 CoVe에 검증 실행 단계에서 검색 증강을 사용하는 등의 도구 사용 기능을 탑재하는 것으로, 이를 통해 더 많은 이점을 얻을 수 있을 것이다.
6. LIMITATIONS
While our Chain-of-Verification (CoVe) method seeks to reduce hallucinations, it does not remove them completely from generations. This means that CoVe can still generate incorrect or misleading information for a given query, even if it improves over the baseline. We also note that in our experiments we have only addressed hallucinations in the form of directly stated factual inaccuracies. However, hallucinations could come in other forms, such as during incorrect reasoning steps, as part of opinions, etc. We also note that the generations CoVe produces come with verifications which, if viewed by the user, add more interpretability to its decisions, but come at the cost of increased computational expense due to generating more tokens in the output, similar to other reasoning methods such as Chain-of-Thought.
트위터의 체인 검증(CoVe) 방식은 환각을 줄이기 위해 노력하지만, 생성물에서 완전히 제거하지는 못한다. 즉, CoVe는 기준선보다 개선되더라도 특정 쿼리에 대해 여전히 부정확하거나 오해의 소지가 있는 정보를 생성할 수 있다. 또한 실험에서는 직접적으로 언급된 부정확한 사실의 형태로만 환각을 다루었다는 점에 유의하라. 그러나 환각은 잘못된 추론 단계, 의견의 일부 등 다른 형태로 나타날 수 있다. 또한 CoVe가 생성하는 세대에는 사용자가 볼 때 결정에 더 많은 해석 가능성을 추가하는 검증이 함께 제공되지만, 연쇄 사고Chain-of-Thought와 같은 다른 추론 방법과 유사하게 출력에 더 많은 토큰을 생성하기 때문에 계산 비용이 증가한다는 점에 유의해야 한다.
Our method seeks to make a large language model produce improved responses by spending more time deliberating to identify its own mistakes. While we have shown this gives clear improvements, the upper bound to the improvement is clearly limited by the overall capabilities of the model, e.g. in identifying and knowing what it knows. In this regard, an orthogonal line of research, as discussed in section 2 is the use of external tools by language models, to gain further information beyond what is stored in its weights. While we do not explore that avenue in this work those techniques would likely be fruitful to combine with the findings here.
저희의 방법은 대규모 언어 모델이 스스로의 실수를 식별하기 위해 더 많은 시간을 투자함으로써 더 나은 응답을 생성하도록 만들려고 한다. 이를 통해 분명한 개선 효과를 얻을 수 있지만, 개선의 상한선은 모델의 전반적인 능력(예: 알고 있는 것을 식별하고 파악하는 능력)에 의해 분명히 제한된다. 이와 관련하여, 섹션 2에서 논의한 바와 같이 언어 모델에서 외부 도구를 사용하여 가중치에 저장된 것 이상의 추가 정보를 얻는 것이 연구의 직교 라인이다. 이 연구에서는 이러한 방법을 탐구하지는 않았지만, 이러한 기법은 여기서의 연구 결과와 결합하면 유익할 수 있다.
REFERENCES
(생략)
7. COVE - FURTHER DETAILS
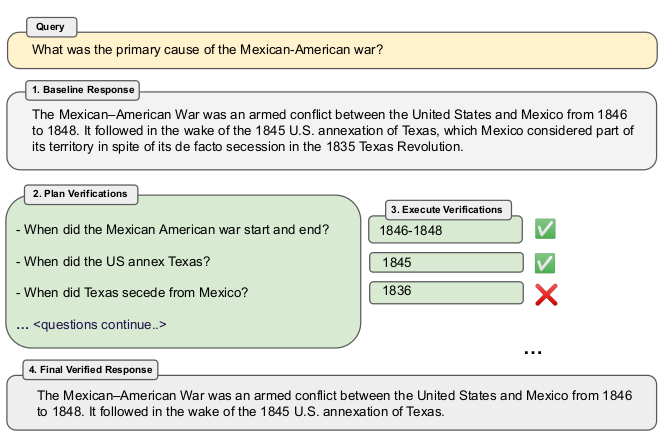
Figure 3: For longform generation, the Chain-of-Verification (CoVe) Factor + Revise method is the most effective in our longform generation experiments. CoVe Factor + Revise has the model indepen- dently identify (cross-check) which facts are consistent with its executed verifications (indicated by tickmark and crosses in the figure). With this extra step we aim to disregard the inconsistent facts and use the consistent facts to regenerate the response.
그림 3: 롱폼 생성의 경우, 롱폼 생성 실험에서 CoVe(Chain-of-Verification) 팩터 + 수정 방법이 가장 효과적이었다. CoVe 팩터 + 수정은 모델이 실행된 검증(그림에서 체크 표시와 십자 표시)과 일치하는 사실을 독립적으로 식별(교차 확인)하도록 한다. 이 추가 단계를 통해 일관되지 않은 사실은 무시하고 일관된 사실을 사용하여 응답을 재생성하는 것을 목표로 한다.
8. PROMPT TEMPLATES
We provide prompt templates for the longform generation of biographies task below for the different steps and variants of CoVe (see section 3). Templates for the other tasks are similar, but using few-shot examples from those tasks instead.
아래에서 다양한 단계와 CoVe의 변형에 따라 롱폼 전기 생성 작업을 위한 프롬프트 템플릿을 제공한다(섹션 3 참조). 다른 작업의 템플릿도 비슷하지만, 대신 해당 작업에서 퓨샷 예시를 사용한다.
8.1 GENERATE BASELINE RESPONSE
Table 5: Few-shot prompting with 3 few-shot examples for the longform generation of biographies task. Other tasks use the same standard few-shot setup as well (with 3 examples from that particular task).
표 5: 전기의 롱폼 생성 작업에 대한 3개의 퓨샷 예제가 포함된 퓨샷 프롬프트. 다른 작업에서도 동일한 표준 퓨샷 설정을 사용한다(특정 작업의 예제 3개 포함).
8.2 PLAN VERIFICATIONS
Table 6: Step (2) of CoVe involves planning the verification questions. In the biography task case we split the longform generation into its individual passages (e.g. sentences in the biography case, this was done due to excessive context length, which we don’t need to do for the other tasks). The model then generates a verification question for each fact it observes in each passage (a passage may have multiple facts).
표 6: CoVe의 (2)단계에는 검증 질문을 계획하는 것이 포함된다. 전기 작업 사례에서는 롱폼 생성을 개별 구절로 분할했다(예: 전기 작업 사례의 문장은 문맥 길이가 너무 길어 다른 작업에서는 이 작업을 수행할 필요가 없음). 그런 다음 모델은 각 구절에서 관찰한 각 사실에 대해 검증 질문을 생성한다(한 구절에 여러 사실이 포함될 수 있음).
8.3 EXECUTE VERIFICATIONS
Table 7: In step (3) of CoVe, the model then generates an answer for each of the verification questions. Again we use 3 few-shot examples.
표 7: CoVe의 (3)단계에서 모델은 각 검증 질문에 대한 답변을 생성한다. 여기에서도 3개의 퓨샷 예시를 사용한다.
8.4 GENERATE FINAL VERIFIED RESPONSE
Table 8: In step (4) of CoVe (factored) the model is then presented with its original generatin (split into passages, e.g. sentences, in the biography case, due to excessive context length which we do not need to do for the other tasks) along with its own verification step results. The model is told that this information comes from “another source”. The model is required to synthesize a new final answer based on facts that are consistent between the two sources.
표 8: CoVe(팩터)의 (4)단계에서 모델은 자체 검증 단계 결과와 함께 원래의 제너레이틴 (전기의 경우 문맥 길이가 너무 길어 다른 작업에는 필요하지 않은 구절로 분할됨)을 제시받다. 모델에는 이 정보가 "다른 출처"에서 왔다고 알려준다. 이 모델은 두 소스 간에 일관된 사실을 기반으로 새로운 최종 답변을 합성해야 한다.
8.5 FACTOR+REVISE: IDENTIFY WHICH FACTS ARE CONSISTENT
Table 9: In the CoVe (Factor + Revise) variant, as part of step (3) after subsection 8.3, the model is made to explicitly identify which facts are consistent between the two sources. The consistent facts can then be spliced together.
표 9: 8.3번 하위 섹션의 (3)단계의 일부인 CoVe(요인 + 수정) 변형에서는 두 출처 간에 어떤 사실이 일치하는지 명시적으로 식별하도록 모델을 만든다. 그런 다음 일관된 사실을 서로 연결할 수 있다.
9. CHATGPT EXAMPLE SCREENSHOTS
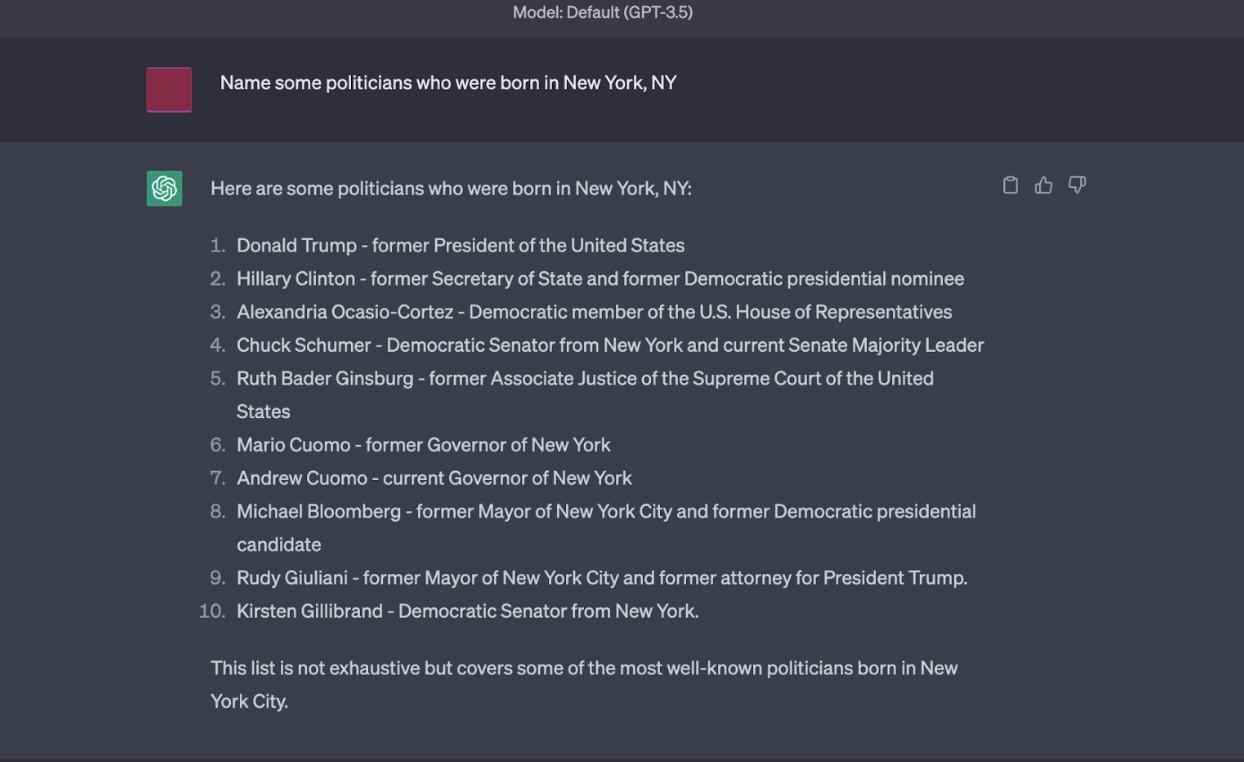
Figure 4: ChatGPT generates several hallucinations for this question, e.g. Hillary Clinton and Michael Bloomberg.
그림 4: ChatGPT는 이 질문에 대해 힐러리 클린턴과 마이클 블룸버그와 같은 여러 환각을 생성한다.
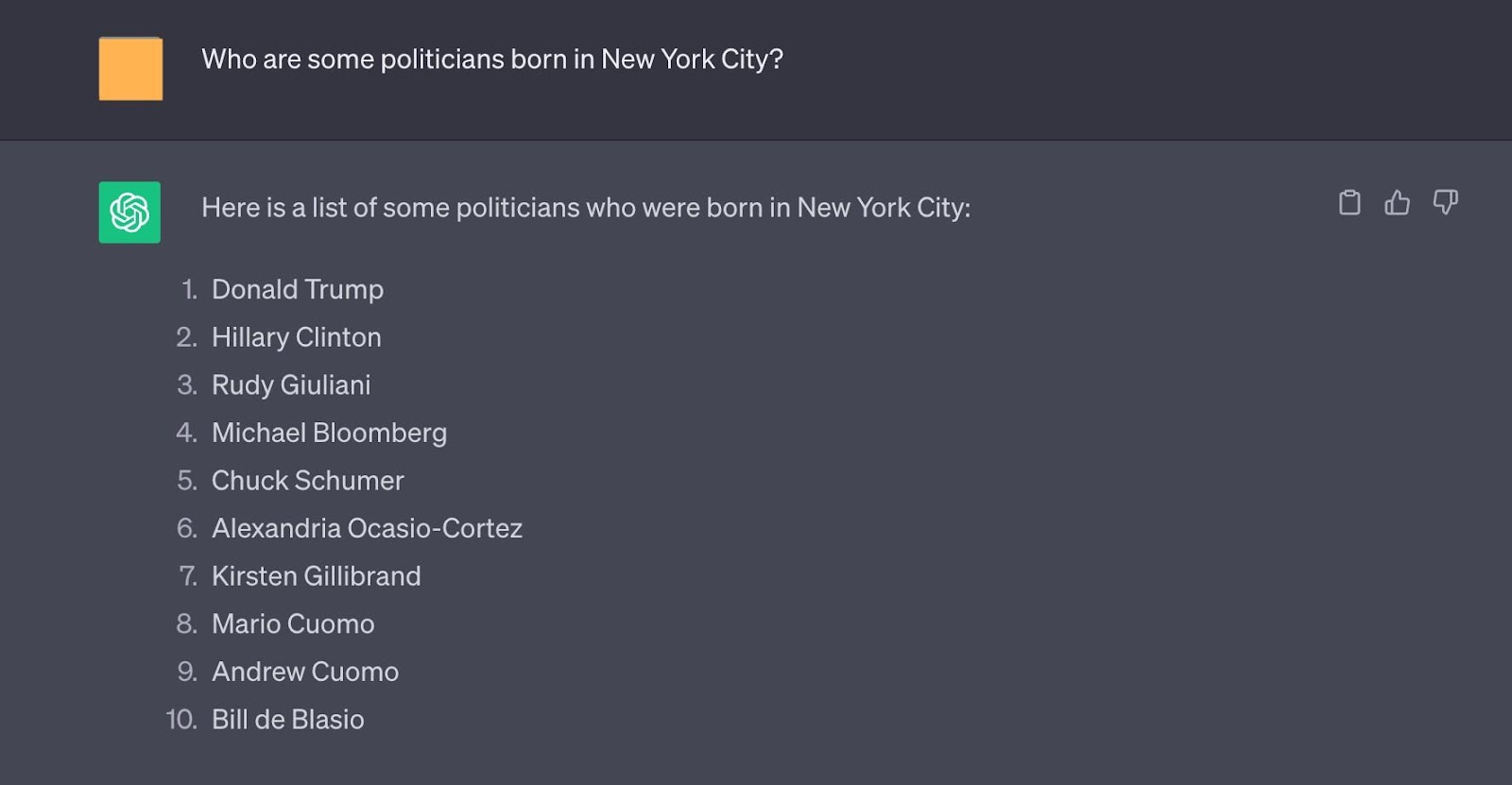
Figure 5: Even when the longform answer is provided for a rewritten query (see query from Figure 4), while giving a slightly different answer, ChatGPT still generates several hallucinations for this question, e.g. Hillary Clinton and Michael Bloomberg.
그림 5: 재작성된 쿼리(그림 4의 쿼리 참조)에 대해 긴 형식의 답변이 제공되더라도(그림 4의 쿼리 참조) 약간 다른 답변을 제공하지만 ChatGPT는 여전히 이 질문에 대해 힐러리 클린턴과 마이클 블룸버그와 같은 몇 가지 환상을 생성한다.
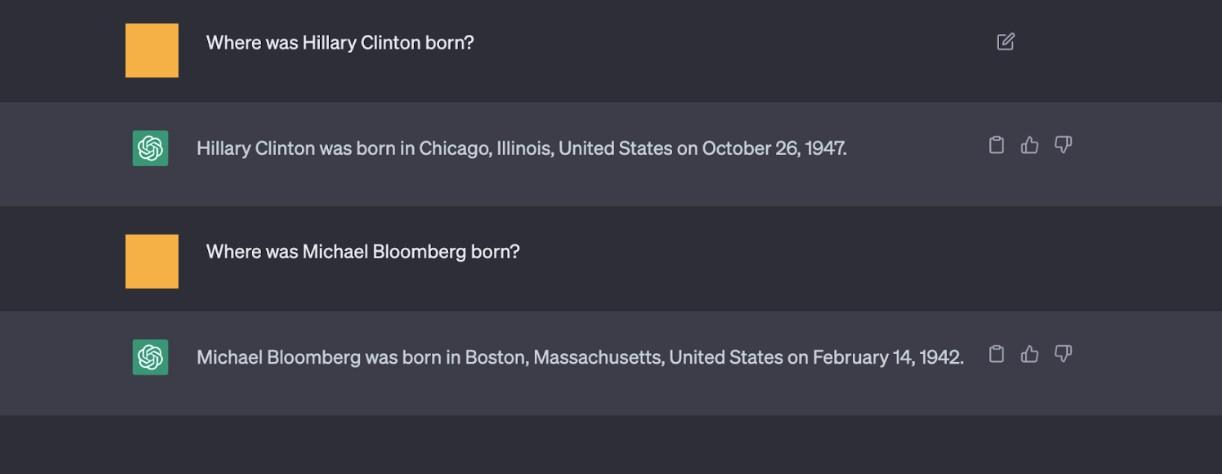
Figure 6: Shortform questions (which could be verification questions) appear to be answered more factually than the longform answers in Figure 4 and Figure 5.
그림 6: 그림 4와 그림 5의 긴 형식의 답변보다 짧은 형식의 질문(확인 질문일 수 있음)이 더 사실적으로 답변된 것으로 보인다.
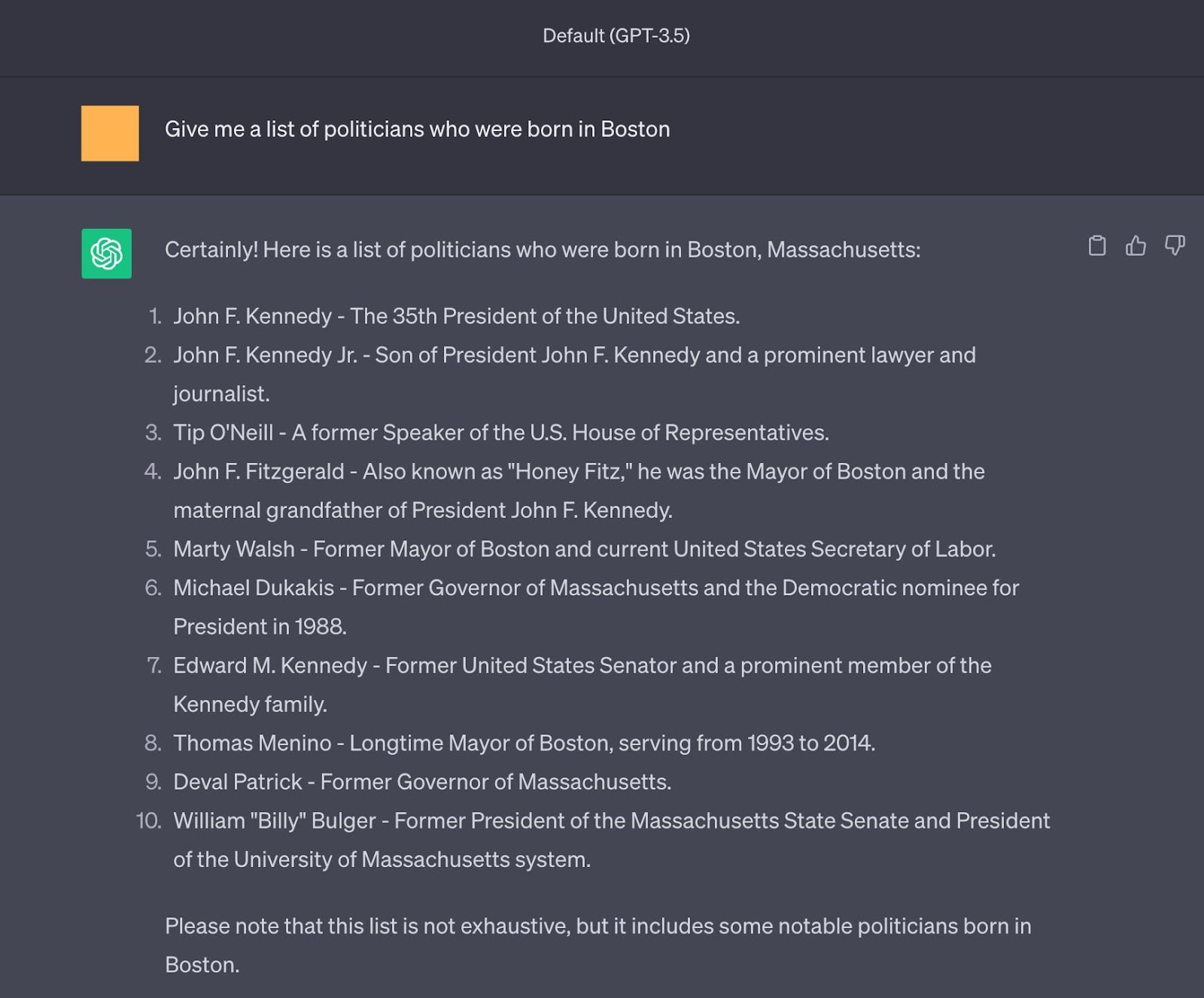
Figure 7: Another example of hallucinations for a different query, e.g., John F. Kennedy Jr was born in Washington D.C.
그림 7: 다른 쿼리에 대한 환각의 또 다른 예(예: 존 F. 케네디 주니어는 워싱턴 D.C.에서 태어났다)이다.
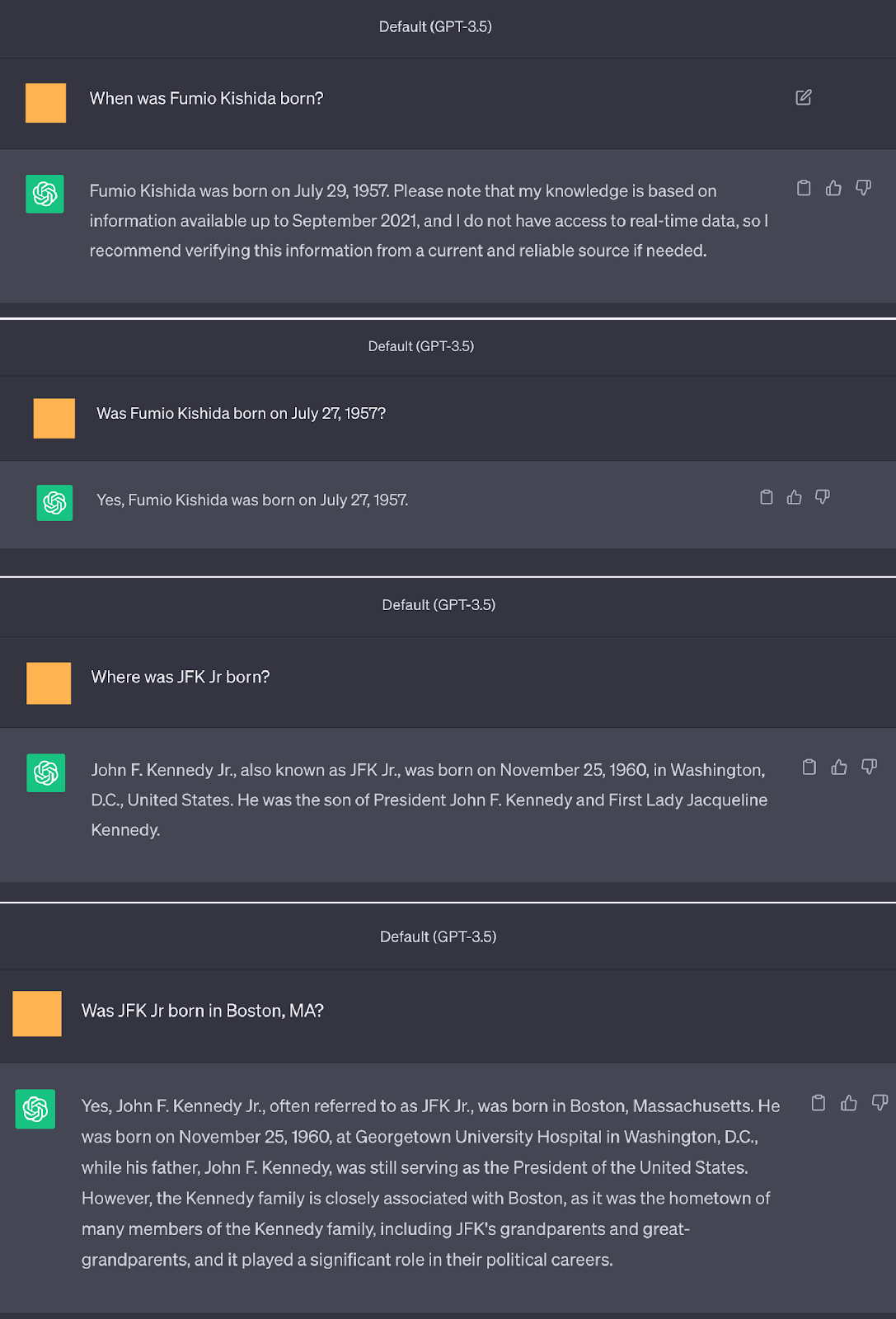
Figure 8: Examples where questions asking for a fact are answered correctly, but verifying via a yes/no question is incorrect (the model tends to agree with the way the question is stated, even if it was stated incorrectly).
그림 8: 사실을 묻는 질문에는 올바르게 답변했지만 예/아니요 질문을 통해 확인하는 것은 잘못된 예(모델은 질문이 잘못 진술되더라도 진술 방식에 동의하는 경향이 있음).



