원문 : https://aclanthology.org/2023.clinicalnlp-1.36/
이 글에 대한 모든 권리는 원문 저자에게 있음
#############
WangLab at MEDIQA-Chat 2023: Clinical Note Generation from Doctor-Patient Conversations using Large Language Models
John Giorgi1,2,3∗ Augustin Toma1,3,4∗ Ronald Xie1,2,3,4∗ Sondra S. Chen1,5Kevin R. An1,6 Grace X. Zheng1,5 Bo Wang1,3,4∗
1University of Toronto 2Terrence Donnelly Centre for Cellular and Biomolecular Research 3Vector Institute for AI 4University Health Network 5Sunnybrook Health Sciences Centre 6Department of Cardiac Surgery, University of Toronto
{john.giorgi, augustin.toma, ronald.xie, bowang.wang}@mail.utoronto.ca
Abstract
This paper describes our submission to the MEDIQA-Chat 2023 shared task for automatic clinical note generation from doctor-patient conversations. We report results for two approaches: the first fine-tunes a pre-trained language model (PLM) on the shared task data, and the second uses few-shot in-context learning (ICL) with a large language model (LLM). Both achieve high performance as measured by automatic metrics (e.g. ROUGE, BERTScore) and ranked second and first, respectively, of all submissions to the shared task. Expert human scrutiny indicates that notes generated via the ICL-based approach with GPT-4 are preferred about as often as human-written notes, making it a promising path toward automated note generation from doctor-patient conversations.1
이 논문에서는 의사-환자 간 대화를 통한 자동 임상 노트 생성을 위해 MEDIQA-Chat 2023 공유 과제에 제출한 내용을 설명한다.첫 번째 접근 방식은 공유 작업 데이터에 대해 사전 학습된 언어 모델(PLM)을 미세 조정하고, 두 번째 접근 방식은 대규모 언어 모델(LLM)과 함께 퓨샷 인컨텍스트 학습(ICL)을 사용하는 것이다.두 가지 방법 모두 자동 메트릭(예: ROUGE, BERTScore)으로 측정한 결과 높은 성능을 달성했으며 공유 작업에 대한 모든 제출물 중 각각 2위와 1위에 올랐다.전문가들의 조사에 따르면 GPT-4를 사용한 ICL 기반 접근 방식을 통해 생성된 노트가 사람이 직접 작성한 노트만큼 선호되는 것으로 나타나, 의사-환자 대화에서 자동화된 노트를 생성하는 데 있어 유망한 경로가 될 것으로 보인다.1
1. Introduction
The growing burden of clinical documentation has emerged as a critical issue in healthcare, increasing job dissatisfaction and burnout rates among clinicians and negatively impacting patient experiences (Friedberg et al., 2013; Babbott et al., 2014; Arndt et al., 2017). On the other hand, timely and accurate documentation of patient encounters is critical for safe, effective care and communication between specialists. Therefore, interest in assisting clinicians by automatically generating consultation notes is mounting (Finley et al., 2018; Enarvi et al., 2020; Molenaar et al., 2020; Knoll et al., 2022).
증가하는 임상 문서화 부담은 임상의의 직무 불만족과 소진율을 높이고 환자 경험에 부정적인 영향을 미치는 등 의료 분야에서 중요한 문제로 대두되고 있다(Friedberg 등, 2013; Babbott 등, 2014; Arndt 등, 2017). 반면에 안전하고 효과적인 치료와 전문가 간의 의사소통을 위해서는 환자 진료에 대한 적시에 정확한 문서화가 중요하다. 따라서 상담 노트를 자동으로 생성하여 임상의를 보조하는 것에 대한 관심이 높아지고 있다(Finley 외., 2018; Enarvi 외., 2020; Molenaar 외., 2020; Knoll 외., 2022).

Figure 1: (A) Fine-tuning a pre-trained language model (PLM), Longformer-Encoder-Decoder (LED, Beltagy et al. 2020). (B) In-context learning (ICL) with large language models (LLMs). We rank train examples based on their similarity to the test dialogue using Instructor (Su et al., 2022a). Notes of the top-k most similar examples are then used as in-context examples to form a prompt alongside natural language instructions and fed to GPT-4 (OpenAI, 2023) to generate the clinical note
그림 1: (A) 사전 학습된 언어 모델 미세 조정하기 (PLM), 롱포머-인코더-디코더(LED, Beltagy 외, 2020).(B) 대규모 언어 모델(LLM)을 사용한 컨텍스트 내 학습(ICL). 테스트 다이얼과의 유사성을 기준으로 인스트럭터를 사용하여 테스트 대화와의 유사성에 따라 훈련 예제의 순위를 매긴다. 인스트럭터를 사용하여 훈련 예제의 순위를 매긴다(Su et al., 2022a). 그런 다음, 가장 유사한 상위 k개의 예시를 문맥 내 예시로 사용하여 자연어 지침과 함께 프롬프트를 형성하고 임상 노트를 생성하기 위해 GPT-4(OpenAI, 2023)에 공급한다.
To further encourage research on automatic clinical note generation from doctor-patient conversations, the MEDIQA-Chat Dialogue2Note shared task was proposed (Ben Abacha et al., 2023). Here, we describe our submission to subtask B: the generation of full clinical notes from doctor-patient dialogues. We explored two approaches; the first fine- tunes a pre-trained language model (PLM, §3.1),
의사-환자 대화를 통한 임상 노트 자동 생성에 대한 연구를 더욱 장려하기 위해 MEDIQA-Chat Dialogue2Note 공유 과제가 제안되었다(벤 아바차 외., 2023). 여기에서는 의사-환자 대화에서 전체 임상 노트를 생성하는 하위 과제 B에 대한 제출 내용을 설명한다. 두 가지 접근 방식을 살펴봤는데, 첫 번째는 사전 학습된 언어 모델을 미세 조정하는 것이다(PLM, §3.1),
∗Core contributors. See author contributions
1https://github.com/bowang-lab/
(1) Rank train examples based on similarity to test dialogue
(1) 테스트 대화와의 유사성을 기준으로 훈련 예제 순위 매기기
Figure 1: (A) Fine-tuning a pre-trained language model (PLM), Longformer-Encoder-Decoder (LED, Beltagy et al. 2020). (B) In-context learning (ICL) with large language models (LLMs). We rank train examples based on their similarity to the test dialogue using Instructor (Su et al., 2022a). Notes of the top-k most similar examples are then used as in-context examples to form a prompt alongside natural language instructions and fed to GPT-4 (OpenAI, 2023) to generate the clinical note.
그림 1: (A) 사전 학습된 언어 모델(PLM), 롱포머-인코더-디코더의 미세 조정(LED, Beltagy 외, 2020). (B) 대규모 랭귀지 모델(LLM)을 사용한 상황 내 학습(ICL). 인스트럭터를 사용하여 테스트 대화와의 유사성에 따라 훈련 예제의 순위를 매긴다(Su et al., 2022a). 그런 다음 가장 유사한 상위 k개의 예시를 문맥 내 예시로 사용하여 자연어 지침과 함께 프롬프트를 구성하고 GPT-4(OpenAI, 2023)에 공급하여 임상 메모를 생성한다.
while the second uses few-shot in-context learning (ICL, §3.2). Both achieve high performance as measured by automatic natural language generation metrics (§4) and ranked second and first, respectively, of all submissions to the shared task. In a human evaluation with three expert physicians, notes generated via the ICL-based approach with GPT-4 were preferred about as often as humanwritten notes (§4.3).
두 번째는 소수의 샷 인컨텍스트 학습(ICL, §3.2)을 사용한다. 두 가지 방식 모두 자동 자연어 생성 지표(§4)로 측정한 결과 높은 성능을 달성했으며, 공유 과제에 제출된 모든 제출물 중 각각 2위와 1위를 차지했다. 세 명의 전문 의사를 대상으로 한 휴먼 평가에서는 GPT-4를 사용한 ICL 기반 접근 방식을 통해 생성된 노트가 사람이 직접 작성한 노트만큼 선호도가 높았다(§4.3).
2. Shared Task and Dataset
MEDIQA-Chat 2023 proposed two shared tasks:
MEDIQA-Chat 2023은 두 가지 공유 과제를 제안했다:
- Dialogue2Note Summarization: Given a conversation between a doctor and patient, the task is to produce a clinical note summarizing the conversation with one or more note sections (e.g. Assessment, Past Medical History).
- Dialogue2Note 요약: 의사와 환자 간의 대화가 주어지면 하나 이상의 노트 섹션(예: 평가, 과거 병력)을 사용하여 대화를 요약하는 임상 노트를 작성하는 작업이다.
Figure 2: Example of a paired doctor-patient conversation and clinical note from the subtask B validation set. Dialogue has been lightly cleaned for legibility (e.g. remove trailing white space). Parts of the dialogue and note have been truncated. During evaluation, sections are grouped under one of four categories: “Subjective”, “Objective Exam”, “Objective Results”, and “Assessment and Plan” (see §2.1 for details).
그림 2: 하위 작업 B 유효성 검사 세트의 쌍으로 구성된 의사-환자 대화 및 임상 메모의 예이다. 대화는 가독성을 위해 가볍게 정리되었다(예: 후행 공백 제거). 대화 및 메모의 일부가 잘렸다. 평가 시 섹션은 네 가지 범주 중 하나로 그룹화된다: "주관적", "객관적 시험", "객관적 결과", "평가 및 계획"(자세한 내용은 §2.1 참조).
- Note2Dialogue Generation: Given a clinical note, the task is to generate a synthetic doctorpatient conversation related to the information described in the note.
2. 노트 2대화 생성: 임상 노트가 주어지면 노트에 설명된 정보와 관련된 의사-환자 간 가상 대화를 생성하는 작업이다.
We focused on Dialogue2Note, which is divided into two subtasks. In subtask ‘A’ (Ben Abacha et al., 2023), the goal is to generate specific sections of a note given partial doctor-patient dialogues. In subtask ‘B’ (Yim et al., 2023), the goal is full note generation from complete dialogues. The remainder of the paper focuses on subtask B; see Appendix A
우리는 두 개의 하위 태스크로 나뉘는 Dialogue2Note에 집중했다. 하위 과제 'A'(벤 아바차 외, 2023)에서는 부분적인 의사-환자 대화가 주어진 노트의 특정 섹션을 생성하는 것이 목표이다. 하위 과제 'B'(Yim 외, 2023)의 목표는 완전한 대화에서 전체 노트를 생성하는 것이다. 본 논문의 나머지 부분은 하위 과제 B에 초점을 맞춘다(부록 A 참조).
2. Task definition
Each of the k examples consist of a doctor-patient dialogue, D = d1, . . . , dk and a corresponding clinical note, N = n1, . . . , nk. The aim is to automatically generate a note ni given a dialogue di. Each note comprises one or more sections, such as “Chief Complaint”, and “Family history”. During evaluation, sections are grouped under one of four categories: “Subjective”, “Objective Exam”, “Objective Results”, and “Assessment and Plan”.2 See Figure 2 for an example doctor-patient conversation and clinical note pair.
for our approach to subtask A, which also ranks first of all submissions to the shared task.
각각의 예는 의사-환자 대화 D = d1, . . . , dk 및 해당 임상 메모(N = n1, . . . , nk로 구성된다. 목표는 대화 di가 주어지면 노트 ni를 자동으로 생성하는 것이다. 각 노트는 "주요 불만 사항" 및 "가족력"과 같은 하나 이상의 섹션으로 구성된다. 평가 과정에서 섹션은 네 가지 범주 중 하나로 그룹화된다: "주관적 검사", "객관적 검사", "객관적 결과", "평가 및 계획"이다.2 의사-환자 대화 및 임상 노트 쌍의 예는 그림 2를 참조하세요.
하위 과제 A에 대한 접근 방식은 공유 과제에 대한 모든 제출물 중 첫 번째 순위를 차지한다.
2See here for the mapping
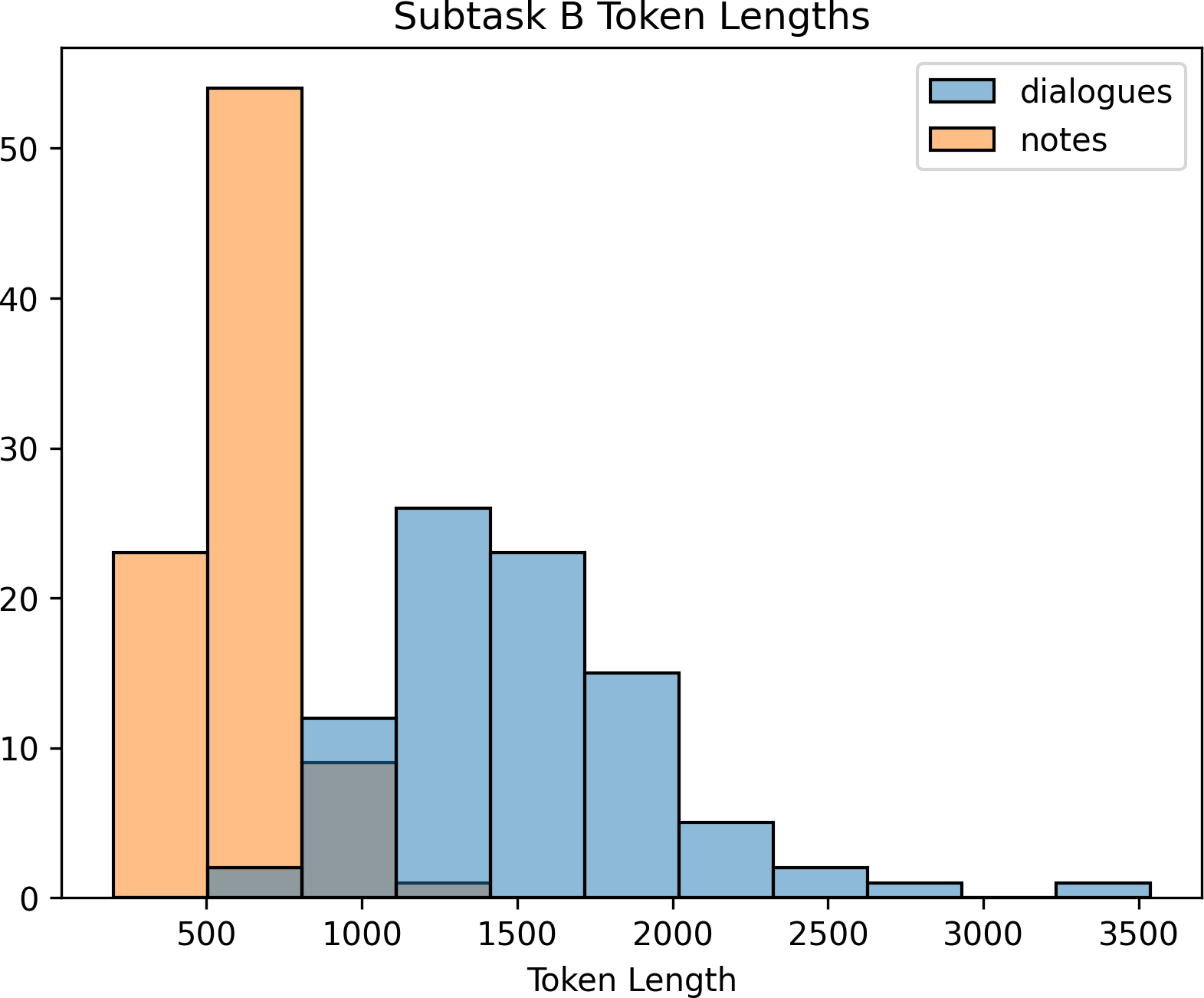
Figure 3: Histogram of token lengths for subtask B train and validation sets. Dialogues and notes were tokenized with tiktoken using the “gpt-4” encoding.
그림 3: 하위 작업 B 훈련 및 검증 세트의 토큰 길이 히스토그램. 대화와 메모는 "gpt-4" 인코딩을 사용하여 틱토큰으로 토큰화되었다.
2.2 Dataset
The dataset comprises 67 train and 20 validation examples, featuring transcribed dialogues from doctor-patient encounters and the resulting clinician-written notes. Each example is labelled with the ‘dataset source’, indicating the dialogue transcription system used to produce the note.
데이터 세트는 67개의 훈련 예시와 20개의 검증 예시로 구성되어 있으며, 의사와 환자 간의 대화를 전사한 내용과 의사가 작성한 진료 노트가 포함되어있다. 각 예제는 해당 노트를 생성한 대화 전사 시스템을 나타내는 '데이터셋 소스'로 레이블이 지정되어 있다.
3. Approach
We take two high-performant approaches to the shared task. In the first, we fine-tune a pre-trained language model (PLM) on the provided training set (§3.1). In the second, we use in-context learning (ICL) with a large language model (LLM, §3.2).
우리는 공유 작업에 대해 두 가지 고성능 접근 방식을 취한다. 첫 번째는 제공된 훈련 세트(§3.1)에서 사전 훈련된 언어 모델(PLM)을 미세 조정하는 것이다. 두 번째는 대규모 언어 모델(LLM, §3.2)과 함께 컨텍스트 내 학습(ICL)을 사용하는 것이다.
3.1 Fine-tuning pre-trained language models

Figure 4: Prompt template for our in-context learning (ICL) based approach. Each prompt includes natural language instructions, up to 3 in-context examples, and an unseen doctor-patient dialogue as input.
그림 4: 상황별 학습(ICL) 기반 접근 방식을 위한 프롬프트 템플릿. 각 프롬프트에는 자연어 지침, 최대 3개의 문맥 내 예시, 보이지 않는 의사-환자 대화가 입력으로 포함되어 있다.
As a first approach, we fine-tune a PLM on the training set following a canonical, sequence-to-sequence training process (Figure 1 A; see Appendix C for details). Given the length of input dialogues (Figure 3), we elected to use LongformerEncoder-Decoder (LED, Beltagy et al. 2020), which has a maximum input size of 16,384 tokens. We begin fine-tuning from a LEDLARGE checkpoint tuned on the PubMed summarization dataset (Cohan et al., 2018), which performed best in preliminary experiments.3 The model was fine-tuned using HuggingFace Transformers (Wolf et al., 2020) on a single NVIDIA A100-40GB GPU. Hyperparame- ters were lightly tuned on the validation set.4
첫 번째 접근 방식으로, 표준 sequence-to-sequence 훈련 프로세스에 따라 훈련셋에서 PLM을 미세 조정한다(그림 1 A, 자세한 내용은 부록 C 참조). 입력 대화의 길이(그림 3)를 고려하여 최대 입력 크기가 16,384 토큰인 LongformerEncoder-Decoder(LED, Beltagy 외, 2020)를 사용하기로 결정했다. 예비 실험에서 가장 우수한 성능을 보인 PubMed 요약 데이터세트(Cohan et al., 2018)를 기반으로 조정된 LEDLARGE 체크포인트에서 미세 조정을 시작했다.3 모델은 단일 NVIDIA A100-40GB GPU에서 HuggingFace Transformers(Wolf et al., 2020)를 사용하여 미세 조정되었다. 하이퍼파라미터는 검증 세트에서 가볍게 조정되었다.4
3https://huggingface.co/patrickvonplaten/
4See Appendix B.1 for details
3.2 In-context learning with LLMs
As a second approach, we attempt subtask B with ICL. We chose GPT-4 (OpenAI, 2023)5 as the LLM and designed a simple prompt, which included natural language instructions and in-context examples (Figure 4). We limited the prompt size to 6192 tokens — allowing for 2000 output tokens, as the model’s maximum token size is 8,192 — and used as many in-context examples as would fit within this token limit, up to a maximum of 3. We set the temperature parameter to 0.2 and left all other hyperparmeters of the OpenAI API at their defaults.
두 번째 접근 방식으로 ICL을 사용하여 서브태스크 B를 시도한다. LLM으로 GPT-4(OpenAI, 2023)5를 선택하고 자연어 명령어와 문맥 내 예제를 포함하는 간단한 프롬프트를 설계했다(그림 4). 모델의 최대 토큰 크기가 8,192개이므로 프롬프트 크기를 6192개로 제한하여 2000개의 출력 토큰을 허용하고, 이 토큰 제한에 맞는 인컨텍스트 예제를 최대 3개까지 사용했다. 온도 매개변수는 0.2로 설정하고 OpenAI API의 다른 모든 하이퍼파미터는 기본값으로 그대로 두었다.
Natural language instructions During prelim- inary experiments, we found that GPT-4 was not overly sensitive to the exact phrasing of the natural language instructions in the prompt. We, therefore, elected to use short, simple instructions (Figure 4).
자연어 명령어 예비 실험에서 GPT-4는 프롬프트의 자연어 명령어의 정확한 문구에 지나치게 민감하지 않다는 것을 발견했다. 따라서 짧고 간단한 지침을 사용하기로 결정했다(그림 4).
In-context example selection Each in-context example is a note from the train set. To select the notes, we first embed the dialogues of each training example and the input dialogue. Train dialogues are then ranked based on cosine similarity to the input dialogue; notes of the resulting top-k training examples are selected as the in-context examples (see Figure 1, B). Dialogues were embedded using Instructor (Su et al., 2022a), a text encoder that supports natural language instructions.6 Lastly, we restricted in-context examples to be of the same ‘dataset source’ (see §2.2) as the input dialogue, hypothesizing that this may improve performance.7
문맥 내 예시 선택 각 문맥 내 예시는 기차 세트의 메모이다. 노트를 선택하려면 먼저 각 훈련 예제의 대화와 입력 대화를 임베드한다. 그런 다음 입력 대화와의 코사인 유사도에 따라 훈련 대화에 순위를 매기고, 그 결과 상위 k개 훈련 예제의 노트를 컨텍스트 내 예제로 선택한다(그림 1, B 참조). 대화는 자연어 명령을 지원하는 텍스트 인코더인 Instructor(Su et al., 2022a)를 사용하여 임베드되었다.6 마지막으로, 입력 대화와 동일한 '데이터 세트 소스'(§2.2 참조)로 인컨텍스트 예제를 제한하여 성능을 개선할 수 있다는 가설을 세웠다.7
5Specifically, the 03/14/2023 snapshot, “gpt-4-0314”
3.3 Evaluation
Models are evaluated with the official evaluation script8 on the validation set (as test notes are not provided). Generated notes are evaluated against the provided ground truth notes with ROUGE (Lin, 2004), BERTScore (Zhang et al., 2020) and BLEURT (Sellam et al., 2020). We report performance as the arithmetic mean of ROUGE-1 F1, BERTScore F1 and BLEURT-20 (Pu et al., 2021).
모델은 검증 세트의 공식 평가 스크립트8를 사용하여 평가된다(테스트 노트는 제공되지 않으므로).생성된 노트는 제공된 실측 자료 노트와 비교하여 ROUGE(Lin, 2004), BERTScore(Zhang et al., 2020) 및 BLEURT(Sellam et al., 2020)로 평가된다.성능은 ROUGE-1 F1, BERTScore F1 및 BLEURT-20의 산술 평균으로 보고한다(Pu et al., 2021).
4. Results
4.1 Fine-tuning pre-trained language models
We present the results of fine-tuning LED in Table 1. Due to the non-determinism of the LED implementation,9 we report the mean results of three training runs. Unsurprisingly, we find that scaling the model size from LEDBASE (12 layers, 162M parameters) to LEDLARGE (24 layers, 460M parameters) leads to sizable gains in performance. Performance further improves by initializing the model with a checkpoint fine-tuned on the PubMed summarization dataset (LEDLARGE-PubMed). This is likely because (1) Dialouge2Note resembles a summarization task, and (2) text from PubMed is more similar to clinical text than is the general domain text used to pre-train LED.10 Our submission to the shared task using this approach ranked second overall, outperforming the next-best submission by 2.7 average score; a difference comparable to the improvement in performance we see by doubling model size (see LEDBASE vs. LEDLARGE, Table 1).
LED 미세 조정 결과를 표 1에 제시한다. LED 구현의 비결정성 때문에,9 세 번의 트레이닝 실행의 평균 결과를 보고한다. 놀랍지않게도 모델 크기를 LED BASE(12개 레이어, 162M 파라미터)에서 LED LARGE(24개 레이어, 460M 파라미터)로 확장하면 성능이 크게 향상되는 것을 알 수 있다. PubMed 요약 데이터 세트(LED LARGE-PubMed)에서 미세 조정된 체크포인트로 모델을 초기화하면 성능이 더욱 향상된다. 이는 (1) Dialouge2Note가 요약 작업과 유사하고, (2) PubMed의 텍스트가 LED를 사전 학습하는 데 사용되는 일반 도메인 텍스트보다 임상 텍스트와 더 유사하기 때문일 수 있다.10 이 접근 방식을 사용한 공유 작업에 제출한 결과, 2위 제출물을 평균 2.7점 앞질러 전체 2위를 차지했는데, 이는 모델 크기를 두 배로 늘렸을 때의 성능 향상과 비슷한 수치이다(표 1, LED BASE 대 LED LARGE 비교 참조).
4.2 In-context learning with LLMs
We present the results of ICL with GPT-4 in Table 2. We note several interesting trends in order of magnitude of impact. First, selecting in-context examples based on the similarity of dialogues has a strong positive impact, typically improving average score by 4 or more. Using only notes as in-context examples, as opposed to dialogue-note pairs, also has a positive impact, typically improving average score by 1. Surprisingly, increasing the number of in-context examples had a marginal effect on performance. Together these results suggest that the in-context examples’ primary benefit is providing guidance with regard to the expected note structure, style and length. Finally, filtering in-context examples to be of the same ‘dataset source’ as the input dialogue has a negligible impact on performance. The best strategy out-performs LED by almost 3 average score (60.8 vs. 57.9, see Table 1 & Table 2) and achieves first place of all submissions to the shared task, out-performing the runner up by > 9 average score. We conclude that (1) few-shot ICL with GPT-4, using as little as one example, is a performance approach for note generation from doctor patient conversations, and (2) using the notes of semantically similar dialogue-note pairs is a strong strategy for selecting the in-context examples.
GPT-4를 사용한 ICL의 결과는 표 2에 제시되어 있다. 영향력의 크기 순으로 몇 가지 흥미로운 경향을 발견할 수 있다. 첫째, 대화의 유사성을 기준으로 문맥 내 예문을 선택하면 일반적으로 평균 점수가 4점 이상 향상되는 등 매우 긍정적인 영향을 미쳤다. 대화와 노트 쌍이 아닌 노트만 문맥 내 예시로 사용하는 경우에도 긍정적인 영향을 미쳐 평균 점수가 1점 정도 향상되었다. 놀랍게도 문맥 내 예시 수를 늘리는 것은 성능에 미치는 영향이 미미했다. 이러한 결과를 종합하면 문맥 내 예제의 주요 이점은 예상되는 노트 구조, 스타일 및 길이에 대한 지침을 제공하는 것임을 알 수 있다. 마지막으로, 문맥 내 예시를 입력 대화와 동일한 '데이터 세트 소스'로 필터링하는 것은 성능에 미치는 영향이 미미했다. 가장 좋은 전략은 LED보다 평균 점수가 거의 3점(60.8점 대 57.9점, 표 1 및 표 2 참조) 높았으며, 공유 과제에 제출된 모든 제출물 중 1위를 차지해 2위보다 평균 9점 이상 앞섰다. 결론적으로 (1) 한 개의 예시만 사용하는 GPT-4를 사용한 퓨샷 ICL이 의사 환자 대화에서 노트를 생성하는데 효과적인 접근 방식이며, (2) 의미적으로 유사한 대화-노트 쌍의 노트를 사용하는 것이 맥락에 맞는 예시를 선택하는 데 강력한 전략이라는 결론을 내릴 수 있다.
6We used the following instructions: “Represent the Medicine dialogue for clustering: {dialogue}”
7Manual review revealed that dataset source was predictive of note structure & style; likely because it indicates which clinician or electronic health record system produced the note
8https://github.com/abachaa/MEDIQA-Chat-2023/
blob/main/scripts/evaluate_summarization.py
9https://github.com/huggingface/transformers/
10LED is initialized from BART (Lewis et al., 2020), which was pre-trained on a combination of text from Wikipedia and BooksCorpus (Zhu et al., 2015)

Table 1: Fine-tuning LED. Mean and standard deviation (SD) of three training runs is shown. Scaling model size and pre-training on a related task improve performance. Bold: best scores.
표 1: LED 미세 조정. 세 번의 훈련 실행의 평균과 표준편차(SD)가 표시된다. 모델 크기를 확장하고 관련 작업에 대한 사전 학습을 수행하면 성능이 향상된다. 굵게 표시: 최고 점수.
4.3 Human evaluation
Automatic evaluation metrics like ROUGE, BERTScore and BLEURT are imperfect and may not correlate with aspects of human judgment.11 Therefore, we conducted an expert human evaluation to validate our results. To make annotation feasible, we conducted it on the validation set (20 examples) using the best performing fine-tuned model: LEDLARGE-PubMed (Table 1), and best performing ICL-based approach: 3-shot, similar, note- only examples filtered by dataset type (Table 2).
ROUGE, BERTScore, BLEURT와 같은 자동 평가 지표는 불완전하며 사람의 판단과 상관관계가 없을 수 있다.11 따라서 저희는 전문가의 휴먼 평가를 실시하여 결과를 검증했다. 주석의 실현 가능성을 높이기 위해 가장 성능이 좋은 미세 조정 모델을 사용하여 검증 세트(20개 예제)에 대해 수행했다: LEDLARGE-PubMed(표 1)와 최고 성능의 ICL 기반 접근 방식을 사용했다: 데이터 세트 유형별로 필터링된 3샷, 유사, 참고 전용 예제(표 2).
Three senior resident physicians12 were shown a ground truth note, a note generated by the fine-tuned model, and a note generated by the ICL-based approach for each example (presented in random order as clinical note ‘A’, ‘B’ and ‘C’) and asked to select which note(s) they preferred, given a dialogue and some simple instructions:
세 명의 선임 레지던트 의사12에게 각 예에 대해 근거 자료 노트, 미세 조정 모델로 생성된 노트, ICL 기반 접근 방식으로 생성된 노트(임상 노트 'A', 'B', 'C'로 무작위 순서로 제시)를 보여주고 대화와 간단한 지침을 제공한 후 선호하는 노트를 선택하도록 요청했다:
11See §6 for an extended discussion
12The three annotators are a subset of the authors who did not interact with the model or model outputs before annotation
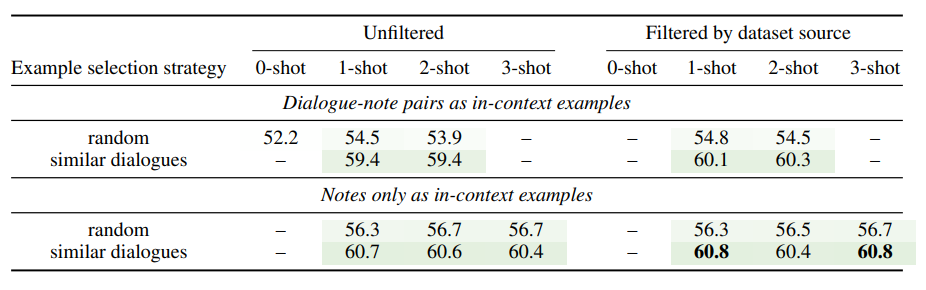
Table 2: ICL with GPT-4. Mean of ROUGE-1 F1, BERTScore F1 and BLEURT for three runs is shown. Selecting in-context examples based on similarity to input dialogue improves performance. Dialogue-note pairs as in-context examples (omitting 3-shot results due to token length limits) underperforms notes only. Filtering in-context examples to be of the same ‘dataset source’ as the input dialogue has little effect. Bold: best scores. SD < 0.1 in all cases.
표 2: GPT-4를 사용한 ICL. 세 번의 실행에 대한 ROUGE-1 F1, BERTScore F1 및 BLEURT의 평균이 표시되어 있다. 입력 대화와의 유사성을 기준으로 컨텍스트 내 예제를 선택하면 성능이 향상된다. 컨텍스트 내 예제로 대화-노트 쌍을 사용하면(토큰 길이 제한으로 인해 3샷 결과 생략) 노트만 성능이 저하된다. 컨텍스트 내 예시를 입력 대화와 동일한 '데이터 세트 소스'로 필터링해도 효과가 거의 없다. 굵게 표시: 최고 점수. 모든 경우에서 SD < 0.1.

Table 3: Human evaluation. Three physicians selected their preference from human written ground-truth notes (GT), notes produced by the fine-tuned model (FT) and notes produced by in-context learning (ICL). Win rate is % of cases where note was preferred, excluding ties.
표 3: 휴먼 평가. 세 명의 의사가 사람이 직접 작성한 사실 기반 노트(GT), 미세 조정 모델(FT)로 생성한 노트, 상황 내 학습(ICL)으로 생성한 노트 중에서 선호하는 것을 선택했다. 승률은 동점을 제외하고 선호하는 노트를 선택한 사례의 %이다.
Instructions: Please asses the clinical notes A, B and C relative to the provided doctor-patient dialogue. For each set of notes, you should select which note you prefer (‘A’, ‘B’, or ‘C’). If you have approximately equal preference for two notes, select (‘A/B’, ‘B/C’, or ‘C/A’). If you have no preference, select ‘A/B/C’. A ‘good’ note should contain all critical, most non-critical and very little irrelevant information mentioned in a dialogue:
instruction : 제공된 의사-환자 대화와 관련하여 임상 노트 A, B, C를 평가하세요. 각 노트 세트에 대해 선호하는 노트('A', 'B' 또는 'C')를 선택해야 한다. 두 노트에 대한 선호도가 거의 같으면 ('A/B', 'B/C', 'C/A')를 선택한다. 선호도가 없다면 'A/B/C'를 선택한다. '좋은' 노트에는 대화에서 언급된 중요하고 중요하지 않은 정보가 모두 포함되어야 하며, 관련 없는 정보는 거의 없어야 한다:
- Critical: Items medico-legally required to document the diagnosis and treatment decisions whose absence or incorrectness may lead to wrong diagnosis and treatment later on, e.g. the symptom "cough" in a suspected chest infection consultation. This is the key information a note needs to capture correctly in order to not mislead clinicians.
중요: 진단 및 치료 결정을 문서화하기 위해 의료법적으로 요구되는 항목으로, 누락되거나 부정확할 경우 추후 잘못된 진단 및 치료로 이어질 수 있다(예: 흉부 감염이 의심되는 상담에서 '기침' 증상). 의료진의 오해를 불러일으키지 않기 위해 메모에 정확하게 캡처해야 하는 핵심 정보이다.
- Non-critical: Items that should be documented in a complete note but whose absence will not affect future treatment or diagnosis,
e.g. "who the patient lives with" in a consultation about chest infection.
중요하지 않음: 전체 메모에 기록해야 하지만 누락해도 향후 치료 또는 진단에 영향을 미치지 않는 항목이다,
예: 흉부 감염에 대한 상담에서 "환자가 누구와 함께 사는지".
- Irrelevant: Medically irrelevant information covered in the consultation, e.g. the pet of a patient with a suspected chest infection just died.
관련 없음: 의학적으로 관련성이 없는 정보(예: 흉부 감염이 의심되는 환자의 반려동물이 방금 사망함).
The definitions of critical, non-critical and irrelevant information are taken from previous work on human evaluation of generated clinical notes (Moramarco et al., 2022; Savkov et al., 2022).
In short, notes generated by ICL are strongly preferred over notes generated by the fine-tuned model and, on average, slightly preferred over the human-written notes (Table 3), validating the high performance reported by the automatic metrics. We note, however, that inter-annotator agreement is low and speculate why this might be in §6.
중요 정보, 중요하지 않은 정보, 관련 없는 정보의 정의는 생성된 임상 노트의 인간 평가에 대한 이전 연구에서 가져온 것이다(Moramarco 외., 2022; Savkov 외., 2022).
요컨대, ICL로 생성된 노트는 미세 조정된 모델에 의해 생성된 노트보다 강력하게 선호되며, 평균적으로 사람이 직접 작성한 노트보다 약간 더 선호된다(표 3). 그러나 주석자 간 일치도가 낮다는 점에 주목하고 그 이유를 §6에서 추측해본다.
5. Related Work
Automated note generation from doctor-patient conversations has received increasing attention in recent years (Finley et al., 2018; Enarvi et al., 2020; Molenaar et al., 2020; Knoll et al., 2022). Different methods have been proposed, such as extractive- abstractive approaches (Joshi et al., 2020; Krishna et al., 2021; Su et al., 2022b) and fine-tuning PLMs (Zhang et al. 2021, similar to our approach in §3.1). Others have focused on curating data for training and benchmarking (Papadopoulos Korfiatis et al., 2022), including the use of LLMs to produce synthetic data (Chintagunta et al., 2021). Lastly, there have been efforts to improve the evaluation of generated clinical notes, both with automatic metrics (Moramarco et al., 2022) and human evaluation (Savkov et al., 2022). While recent literature has commented on the potential of ICL for note generation (Lee et al., 2023), our work is among the first to evaluate this approach rigorously.
의사와 환자 간의 대화를 통한 자동화된 노트 생성은 최근 몇 년 동안 점점 더 많은 관심을 받고 있다 (Finley 외., 2018; Enarvi 외., 2020; Molenaar 외., 2020; Knoll 외., 2022). 추출적-추상적 접근법(Joshi 외, 2020; Krishna 외, 2021; Su 외, 2022b), PLM 미세 조정(Zhang 외, 2021, §3.1의 접근 방식과 유사) 등 다양한 방법이 제안되었다. 다른 연구자들은 합성 데이터를 생성하기 위해 LLM을 사용하는 것을 포함하여 훈련 및 벤치마킹을 위한 데이터 큐레이팅(Papadopoulos Korfiatis 외., 2022)에 집중했다(Chintagunta 외., 2021). 마지막으로, 자동 메트릭(Moramarco 외., 2022)과 휴먼 평가(Savkov 외., 2022)를 통해 생성된 임상 노트의 평가를 개선하려는 노력이 있었다. 최근 문헌에서는 노트 생성에 대한 ICL의 잠재력에 대해 언급하고 있지만(Lee et al., 2023), 이 접근법을 엄격하게 평가한 것은 이번 연구가 처음이다.
6. Conclusion
We present our submission to the MEDIQA-Chat shared task for clinical note generation from doctor patient dialogues. We evaluated a fine-tuning-based approach with LED and an ICL-based approach with GPT-4, ranking second and first, respectively, among all submissions. Human evaluation with three physicians revealed that notes produced by GPT-4 via ICL were strongly preferred over notes produced by LED and, on average, slightly preferred over human-written notes. We conclude that ICL is a promising path toward clinical note generation from doctor-patient conversations.
의사와 환자의 대화에서 임상 노트를 생성하기 위한 MEDIQA-Chat 공유 과제에 제출한 내용을 발표한다. LED를 사용한 미세 조정 기반 접근 방식과 GPT-4를 사용한 ICL 기반 접근 방식을 평가한 결과, 전체 제출작 중 각각 2위와 1위에 올랐다. 세 명의 의사를 대상으로 한 휴먼 평가 결과, ICL을 통해 GPT-4로 생성된 메모가 LED로 생성된 메모보다 선호도가 높았으며, 평균적으로 사람이 직접 작성한 메모보다 약간 선호도가 높은 것으로 나타났다. ICL은 의사와 환자 간의 대화를 통해 임상 노트를 생성하는 데 있어 유망한 방법이라는 결론을 내렸다.
Limitations
Evaluation of generated text is difficult Evaluating automatically generated text, including clinical notes, is generally hard due to the inherently subjective nature of many aspects of output quality. Automatic evaluation metrics such as ROUGE and BERTScore are imperfect (Deutsch et al., 2022) and may not correlate with aspects of expert judgment. However, they are frequently used to evaluate model-generated clinical notes and do correlate with certain aspects of quality (Moramarco et al., 2022). To further validate our findings, we also conducted a human evaluation with three expert physicians (§4.3). As noted previously (Savkov et al., 2022), even human evaluation of clinical notes is far from perfect; inter-annotator agreement is generally low, likely because physicians have differing opinions on the importance of each patient statement and whether it should be included in a consultation note. We also found low interannotator agreement in our human evaluation and speculate this is partially due to differences in specialties among the physicians. Physicians 1 and 3, both from family medicine, had high agreement with each other but low agreement with physician 2 (cardiac surgery, see Table 3). Investigating better automatic metrics and best practices for evaluating clinical notes (and generated text more broadly) is an active field of research. We hope to integrate novel and performant metrics in future work.
생성된 텍스트의 평가가 어려움 임상 노트를 포함하여 자동으로 생성된 텍스트를 평가하는 것은 일반적으로 출력 품질의 여러 측면의 본질적인 주관적 특성으로 인해 어렵다. ROUGE 및 BERTScore와 같은 자동 평가 지표는 불완전하며(Deutsch et al., 2022) 전문가 판단의 측면과 상관관계가 없을 수 있다. 그러나 모델에서 생성된 임상 노트를 평가하는데 자주 사용되며 특정 품질 측면과 상관관계가 있다(Moramarco 외., 2022). 연구 결과를 더욱 검증하기 위해 세 명의 전문 의사와 함께 휴먼 평가도 실시했다(§4.3). 앞서 언급한 바와 같이(Savkov 외, 2022), 임상 노트에 대한 휴먼 평가조차도 완벽하지 않으며, 각 환자 진술의 중요성과 상담 노트에 포함해야 하는지 여부에 대해 의사마다 의견이 다르기 때문에 일반적으로 주석자 간 합의가 낮다. 또한 휴먼 평가에서도 주석자 간 일치도가 낮은 것으로 나타났는데, 이는 부분적으로 의사들 간의 전문 분야 차이 때문인 것으로 추측된다. 가정의학과 출신인 의사 1과 의사 3은 서로 높은 일치도를 보였지만 의사 2(심장외과, 표 3 참조)와는 낮은 일치도를 보였다. 임상 노트(및 보다 광범위하게는 생성된 텍스트)를 평가하기 위한 더 나은 자동 지표와 모범 사례를 조사하는 것은 활발한 연구 분야이다. 향후 작업에서 새롭고 성과가 좋은 지표를 통합할 수 있기를 기대한다.
Data privacy While our GPT-4 based solution achieves the best performance, it is not compliant with data protection regulations such as HIPAA; although Azure does advertise a HIPAA-compliant option.13 From a privacy perspective, locally deploying a model such as LED may be preferred; however, our results suggest that more work is needed for this approach to reach acceptable performance (see Table 3). In either case, when implementing automated clinical note-generation systems, healthcare providers and developers should ensure that the whole system — including text-to-speech, data transmission & storage, and model inference — adheres to privacy and security requirements to maintain trust and prevent privacy violations in the clinical setting.
데이터 개인 정보 보호 Microsoft의 GPT-4 기반 솔루션은 최상의 성능을 제공하지만 HIPAA와 같은 데이터 보호 규정을 준수하지는 않다(Azure는 HIPAA 준수 옵션을 광고하고 있다).13 개인 정보 보호 관점에서 LED와 같은 모델을 로컬에 배포하는 것이 선호될 수 있지만, 조사 결과에 따르면 이 접근 방식이 허용 가능한 성능에 도달하려면 더 많은 작업이 필요한 것으로 나타났다(표 3 참조). 어떤 경우든 자동화된 임상 메모 생성 시스템을 구현할 때 의료 서비스 제공자와 개발자는 텍스트 음성 변환, 데이터 전송 및 저장, 모델 추론을 포함한 전체 시스템이 개인정보 보호 및 보안 요구 사항을 준수하여 임상 환경에서 신뢰를 유지하고 개인정보 침해를 방지해야 한다.
Ethics Statement
윤리 정책
Developing an automated system for clinical note generation from doctor-patient conversations raises several ethical considerations. First, informed consent is crucial: patients must be made aware of their recording, and data ownership must be prioritized. Equitable access is also important; the system must be usable for patients from diverse backgrounds, including those with disabilities, limited technical literacy, or language barriers. Addressing issues of data bias and fairness are necessary to avoid unfair treatment or misdiagnosis for certain patient groups. The system must implement robust security measures to protect patient data from unauthorized access or breaches. Establishing clear lines of accountability for errors or harms arising from using an automated system for note generation is paramount. Disclosure of known limitations or potential risks associated with using the system is essential to maintain trust in the patient-physician relationship. Finally, ongoing evaluations are necessary to ensure that system performance does not degrade and negatively impact the quality of care.
의사와 환자 간의 대화에서 임상 노트를 생성하는 자동화된 시스템을 개발할 때는 몇 가지 윤리적 고려 사항이 있다. 첫째, 환자에게 자신의 기록에 대해 알려야 하고 데이터 소유권을 우선적으로 고려해야 하는 등 사전 동의가 중요하다. 장애가 있거나 기술 활용 능력이 부족하거나 언어 장벽이 있는 환자 등 다양한 배경을 가진 환자들이 시스템을 사용할 수 있어야 한다. 특정 환자 그룹에 대한 불공정한 치료나 오진을 방지하기 위해 데이터 편향성 및 공정성 문제를 해결해야 한다. 시스템은 환자 데이터를 무단 액세스 또는 침해로부터 보호하기 위해 강력한 보안 조치를 구현해야 한다. 자동화된 시스템을 사용하여 메모를 생성할 때 발생하는 오류나 피해에 대한 책임 소재를 명확히 규정하는 것이 무엇보다 중요하다. 시스템 사용과 관련된 알려진 제한 사항이나 잠재적 위험을 공개하는 것은 환자-의사 관계에 대한 신뢰를 유지하는 데 필수적이다. 마지막으로, 시스템 성능이 저하되어 진료의 질에 부정적인 영향을 미치지 않도록 지속적인 평가가 필요하다.
Acknowledgements
This research was enabled in part by support provided by the Digital Research Alliance of Canada (alliancecan.ca) and Compute Ontario (www.computeontario.ca). We thank all internal and external reviewers for their thoughtful feedback, which improved earlier drafts of this manuscript.
이 연구는 부분적으로 캐나다 디지털 연구 연합 (alliancecan.ca)과 컴퓨트 온타리오 (www.computeontario.ca) 의 지원으로 이루어졌다. 이 원고의 초기 초안을 개선할 수 있도록 사려 깊은 피드백을 보내주신 모든 내부 및 외부 검토자에게 감사드립니다.
Author Contributions
John Giorgi (JG), Augustin Toma (AT) and Ronald Xie (RX) led the project in general, including data cleaning and processing, model implementation, and running experiments. JG wrote the initial manuscript and designed the human evaluation with feedback from AT and RX. AT and RX recruited Sondra S. Chen, Kevin R. An and Grace X. Zheng, who served as expert physicians in the human evaluation. Bo Wang provided high- level feedback and advice.
존 조르지(John Giorgi, JG), 어거스틴 토마(Augustin Toma, AT), 로널드 시에(Ronald Xie, RX)가 데이터 정리 및 처리, 모델 구현, 실험 실행 등 프로젝트 전반을 주도했다. JG는 초기 원고를 작성하고 AT와 RX의 피드백을 받아 휴먼 평가를 설계했다. AT와 RX는 인체 평가의 전문 의사로 손드라 S. 첸, 케빈 R. 안, 그레이스 X. 정을 영입했다. 보 왕은 높은 수준의 피드백과 조언을 제공했다.
13https://azure.microsoft.com/en-us/products/
cognitive-services/openai-service#security
References
Brian G. Arndt, John W. Beasley, M. Watkinson, Jonathan L Temte, Wen-Jan Tuan, Christine A. Sinsky, and Valerie J. Gilchrist. 2017. Tethered to the ehr: Primary care physician workload assessment using ehr event log data and time-motion observations. The Annals of Family Medicine, 15:419–426.
Stewart F. Babbott, Linda Baier Manwell, Roger L. Brown, Enid N. H. Montague, Eric S. Williams, Mark D. Schwartz, Erik P. Hess, and Mark Linzer. 2014. Electronic medical records and physician stress in primary care: results from the memo study. Journal of the American Medical Informatics Association : JAMIA, 21 e1:e100–6.
Iz Beltagy, Matthew E. Peters, and Arman Cohan. 2020. Longformer: The long-document transformer. ArXiv, abs/2004.05150.
Asma Ben Abacha, Wen wai Yim, Griffin Adams, Neal Snider, and Meliha Yetisgen. 2023. Overview of the mediqa-chat 2023 shared tasks on the summarization and generation of doctor-patient conversations. In ACL-ClinicalNLP 2023.
Asma Ben Abacha, Wen-wai Yim, Yadan Fan, and Thomas Lin. 2023. An empirical study of clinical note generation from doctor-patient encounters. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 2283–2294, Dubrovnik, Croatia. Association for Computational Linguistics.
Bharath Chintagunta, Namit Katariya, Xavier Amatriain, and Anitha Kannan. 2021. Medically aware GPT-3 as a data generator for medical dialogue summarization. In Proceedings of the Second Workshop on Natural Language Processing for Medical Conversations, pages 66–76, Online. Association for Computational Linguistics.
Hyung Won Chung, Le Hou, S. Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Dasha Valter, Sharan Narang, Gaurav Mishra, Adams Wei Yu, Vincent Zhao, Yanping Huang, Andrew M. Dai, Hongkun Yu, Slav Petrov, Ed Huai hsin Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny
Zhou, Quoc V. Le, and Jason Wei. 2022. Scaling instruction-finetuned language models. ArXiv, abs/2210.11416.
Arman Cohan, Franck Dernoncourt, Doo Soon Kim, Trung Bui, Seokhwan Kim, Walter Chang, and Nazli Goharian. 2018. A discourse-aware attention model for abstractive summarization of long documents. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), pages 615–621, New Orleans, Louisiana. Association for Computational Linguistics.
Daniel Deutsch, Rotem Dror, and Dan Roth. 2022. Reexamining system-level correlations of automatic summarization evaluation metrics. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 6038–6052, Seattle, United States. Association for Computational Linguistics.
Seppo Enarvi, Marilisa Amoia, Miguel Del-Agua Teba, Brian Delaney, Frank Diehl, Stefan Hahn, Kristina Harris, Liam McGrath, Yue Pan, Joel Pinto, Luca Rubini, Miguel Ruiz, Gagandeep Singh, Fabian Stemmer, Weiyi Sun, Paul Vozila, Thomas Lin, and Ranjani Ramamurthy. 2020. Generating medical reports from patient-doctor conversations using sequence-to-sequence models. In Proceedings of the First Workshop on Natural Language Processing for Medical Conversations, pages 22–30, Online. Association for Computational Linguistics.
Gregory Finley, Erik Edwards, Amanda Robinson, Michael Brenndoerfer, Najmeh Sadoughi, James Fone, Nico Axtmann, Mark Miller, and David Suendermann-Oeft. 2018. An automated medical scribe for documenting clinical encounters. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Demonstrations, pages 11–15, New Orleans, Louisiana. Association for Computational Linguistics.
Mark W. Friedberg, Peggy G. Chen, Kristin R Van Busum, Frances Aunon, Chau Pham, John P. Caloyeras, Soeren Mattke, Emma Pitchforth, Denise D. Quigley, Robert Henry Brook, Francis J. Crosson, and Michael A. Tutty. 2013. Factors affecting physician professional satisfaction and their implications for patient care, health systems, and health policy. Rand health quarterly, 3 4:1.
Alex Graves. 2012. Sequence transduction with recurrent neural networks. ArXiv preprint, abs/1211.3711.
Anirudh Joshi, Namit Katariya, Xavier Amatriain, and Anitha Kannan. 2020. Dr. summarize: Global summarization of medical dialogue by exploiting local structures. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 3755– 3763, Online. Association for Computational Linguistics.
Tom Knoll, Francesco Moramarco, Alex Papadopoulos Korfiatis, Rachel Young, Claudia Ruffini, Mark Perera, Christian Perstl, Ehud Reiter, Anya Belz, and Aleksandar Savkov. 2022. User-driven research of medical note generation software. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 385–394, Seattle, United States. Association for Computational Linguistics.
Kundan Krishna, Sopan Khosla, Jeffrey Bigham, and Zachary C. Lipton. 2021. Generating SOAP notes from doctor-patient conversations using modular summarization techniques. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 4958–4972, Online. Association for Computational Linguistics.
Peter Lee, Sébastien Bubeck, and Joseph Petro. 2023. Benefits, limits, and risks of gpt-4 as an ai chatbot for medicine. The New England journal of medicine, 388 13:1233–1239.
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. 2020. BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7871–7880, Online. Association for Computational Linguistics.
Chin-Yew Lin. 2004. ROUGE: A package for automatic evaluation of summaries. In Text Summarization Branches Out, pages 74–81, Barcelona, Spain. Association for Computational Linguistics.
Ilya Loshchilov and Frank Hutter. 2019. Decoupled weight decay regularization. In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net.
Sabine Molenaar, Lientje Maas, Verónica Burriel, Fabiano Dalpiaz, and Sjaak Brinkkemper. 2020. Medical dialogue summarization for automated reporting in healthcare. Advanced Information Systems Engineering Workshops, 382:76–88.
Francesco Moramarco, Alex Papadopoulos Korfiatis, Mark Perera, Damir Juric, Jack Flann, Ehud Reiter, Anya Belz, and Aleksandar Savkov. 2022. Human evaluation and correlation with automatic metrics in consultation note generation. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5739–5754, Dublin, Ireland. Association for Computational Linguistics.
OpenAI. 2023. Gpt-4 technical report. ArXiv, abs/2303.08774.
Alex Papadopoulos Korfiatis, Francesco Moramarco, Radmila Sarac, and Aleksandar Savkov. 2022. PriMock57: A dataset of primary care mock consultations. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 588–598, Dublin, Ireland. Association for Computational Linguistics.
Amy Pu, Hyung Won Chung, Ankur Parikh, Sebastian Gehrmann, and Thibault Sellam. 2021. Learning compact metrics for MT. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 751–762, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
Aleksandar Savkov, Francesco Moramarco, Alex Papadopoulos Korfiatis, Mark Perera, Anya Belz, and Ehud Reiter. 2022. Consultation checklists: Standardising the human evaluation of medical note generation. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages 111–120, Abu Dhabi, UAE. Association for Computational Linguistics.
Thibault Sellam, Dipanjan Das, and Ankur Parikh. 2020. BLEURT: Learning robust metrics for text generation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7881–7892, Online. Association for Computational Linguistics.
Hongjin Su, Weijia Shi, Jungo Kasai, Yizhong Wang, Yushi Hu, Mari Ostendorf, Wen tau Yih, Noah A. Smith, Luke Zettlemoyer, and Tao Yu. 2022a. One embedder, any task: Instruction-finetuned text embeddings. ArXiv, abs/2212.09741.
Jing Su, Longxiang Zhang, Hamidreza Hassanzadeh, and Thomas Schaaf. 2022b. Extract and abstract with bart for clinical notes from doctor-patient conversations. In Interspeech.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, pages 5998–6008.
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander Rush. 2020. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 38–45, Online. Association for Computational Linguistics.
Wen-wai Yim, Yujuan Fu, Asma Ben Abacha, Neal Snider, Thomas Lin, and Meliha Yetisgen. 2023. The aci demo corpus: An open dataset for benchmark ing the state-of-the-art for automatic note generation from doctor-patient conversations. Submitted to Nature Scientific Data.
Longxiang Zhang, Renato Negrinho, Arindam Ghosh, Vasudevan Jagannathan, Hamid Reza Hassanzadeh, Thomas Schaaf, and Matthew R. Gormley. 2021. Leveraging pretrained models for automatic summarization of doctor-patient conversations. In Findings of the Association for Computational Linguistics: EMNLP 2021, pages 3693–3712, Punta Cana, Dominican Republic. Association for Computational Linguistics.
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. 2020. Bertscore: Evaluating text generation with BERT. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net.
Yukun Zhu, Ryan Kiros, Richard S. Zemel, Ruslan Salakhutdinov, Raquel Urtasun, Antonio Torralba, and Sanja Fidler. 2015. Aligning books and movies: Towards story-like visual explanations by watching movies and reading books. In 2015 IEEE International Conference on Computer Vision, ICCV 2015, Santiago, Chile, December 7-13, 2015, pages 19–27. IEEE Computer Society.
- Preprocess targets
- Fine-tune on shared task data

Train set
- Parse section headers and text from model generations

Test dialogue
Figure 5: Fine-tuning FLAN-T5 (Chung et al., 2022) for subtask A. Before training, targets are preprocessed as “Section header: {section_header} Section text:
{section_text}”. After decoding, the section header and text are parsed using regular expressions.
그림 5: 하위 작업 A에 대한 FLAN-T5 미세 조정(Chung et al., 2022): 훈련 전에 타깃은 '섹션 헤더'로 전처리된다: {섹션_헤더} 섹션 텍스트:
{섹션_텍스트}"로 전처리한다. 디코딩 후 섹션 헤더와 텍스트는 정규 표현식을 사용하여 구문 분석된다.
-
Subtask A
In subtask A of the Dialogue2Note Summarization shared task, given a partial doctor-patient dialogue, the goals are to: (1) predict the appropriate section header, e.g. “PASTMEDICALHX” and (2) generate that specific section of a note. We approached this task by fine-tuning a PLM on the provided training set, following a canonical, sequence-to sequence training process (see Appendix C for details). In preliminary experiments, we found that the instruction-tuned FLAN-T5 (Chung et al., 2022) performed particularly well at this task.
Dialogue2Note 요약 공유 과제의 하위 과제 A에는 의사와 환자의 부분적인 대화가 주어지며, 목표는 다음과 같다: (1) 적절한 섹션 헤더(예: "PASTMEDICALHX")를 예측하고 (2) 해당 특정 섹션의 노트를 생성하는 것이다. 우리는 표준적인 시퀀스 간 훈련 프로세스에 따라 제공된 훈련 세트에 대해 PLM을 미세 조정하는 방식으로 이 작업에 접근했다(자세한 내용은 부록 C 참조). 예비 실험에서 우리는 인스트럭션이 튜닝된 FLAN-T5(Chung et al., 2022)가 이 과제에서 특히 우수한 성능을 발휘한다는 것을 발견했다.
We hypothesized that jointly learning to predict the section header and generate the section text would improve overall performance. To do this, we preprocessed the training set so the targets were of the form: “Section header: {section_header} Section text: {section_text}”. After decoding, the section header and text were parsed using regular expressions and evaluated separately (Figure 5). Section header prediction was evaluated as the fraction of predicted headers that match the ground truth (accuracy), and section text was evaluated similarly to subtask B (see §3.3). In cases where the model output an invalid section header,14 we replaced it with “GENHX” (general history), which tends to summarize the contents of the other sections. The model was fine-tuned on a single NVIDIA A100-40GB GPU. Hyperparameters were lightly tuned on the validation set (Table 4).
섹션 헤더를 예측하고 섹션 텍스트를 생성하는 학습을 공동으로 수행하면 전반적인 성능이 향상될 것이라는 가설을 세웠다. 이를 위해 훈련 집합을 사전 처리하여 목표가 다음과 같은 형태가 되도록 했다: "섹션 헤더: 섹션 헤더: {섹션_헤더} 섹션 텍스트: {섹션_텍스트}" 형식이 되도록 사전 처리했다. 디코딩 후, 섹션 헤더와 텍스트는 정규식을 사용하여 구문 분석하고 별도로 평가했다(그림 5). 섹션 헤더 예측은 실측 데이터와 일치하는 예측 헤더의 비율(정확도)로 평가했으며, 섹션 텍스트는 서브태스크 B와 유사하게 평가했다(§3.3 참조). 모델이 잘못된 섹션 헤더를 출력한 경우,14 다른 섹션의 내용을 요약하는 경향이 있는 "GENHX"(일반 역사)로 대체했다. 이 모델은 단일 NVIDIA A100-40GB GPU에서 미세 조정되었다. 하이퍼파라미터는 검증 세트에서 가볍게 조정되었다(표 4).
We present the results of our approach on the validation set in Table 5. Similar to subtask B (see
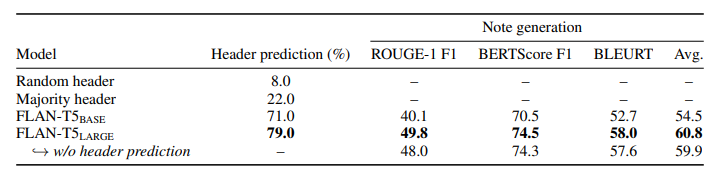
§4.1), we find, perhaps unsurprisingly, that scaling the model size from FLAN-T5BASE (24 layers, 250M parameters) to FLAN-T5LARGE (48 layers, 780M parameters) leads to large improvements in performance. Performance is further improved by jointly learning to predict section headers and generate note sections. Our submission to the shared task based on this approach tied for first on section header prediction (78% accuracy), and ranked first for note section generation (average ROUGE-1, BERTScore and BLEURT F1-score of 57.9).
표 5의 검증 세트에 대한 접근 방식 결과를 제시한다. 하위 작업 B와 유사하게(§4.1 참조)과 마찬가지로, 모델 크기를 FLAN-T5BASE(24개 레이어, 250만 개의 파라미터)에서 FLAN-T5LARGE(48개 레이어, 780만 개의 파라미터)로 확장하면 성능이 크게 향상되는 것을 알 수 있다. 섹션 헤더를 예측하고 노트 섹션을 생성하는 공동 학습을 통해 성능은 더욱 향상된다. 이 접근 방식을 기반으로 공유 과제에 제출한 결과, 섹션 헤더 예측에서 공동 1위(정확도 78%)를 차지했으며, 노트 섹션 생성에서도 1위를 차지했다(평균 ROUGE-1, BERTScore 및 BLEURT F1 점수 57.9점).
14In practice, we found that the fine-tuned model rarely, if ever, generates invalid section headers
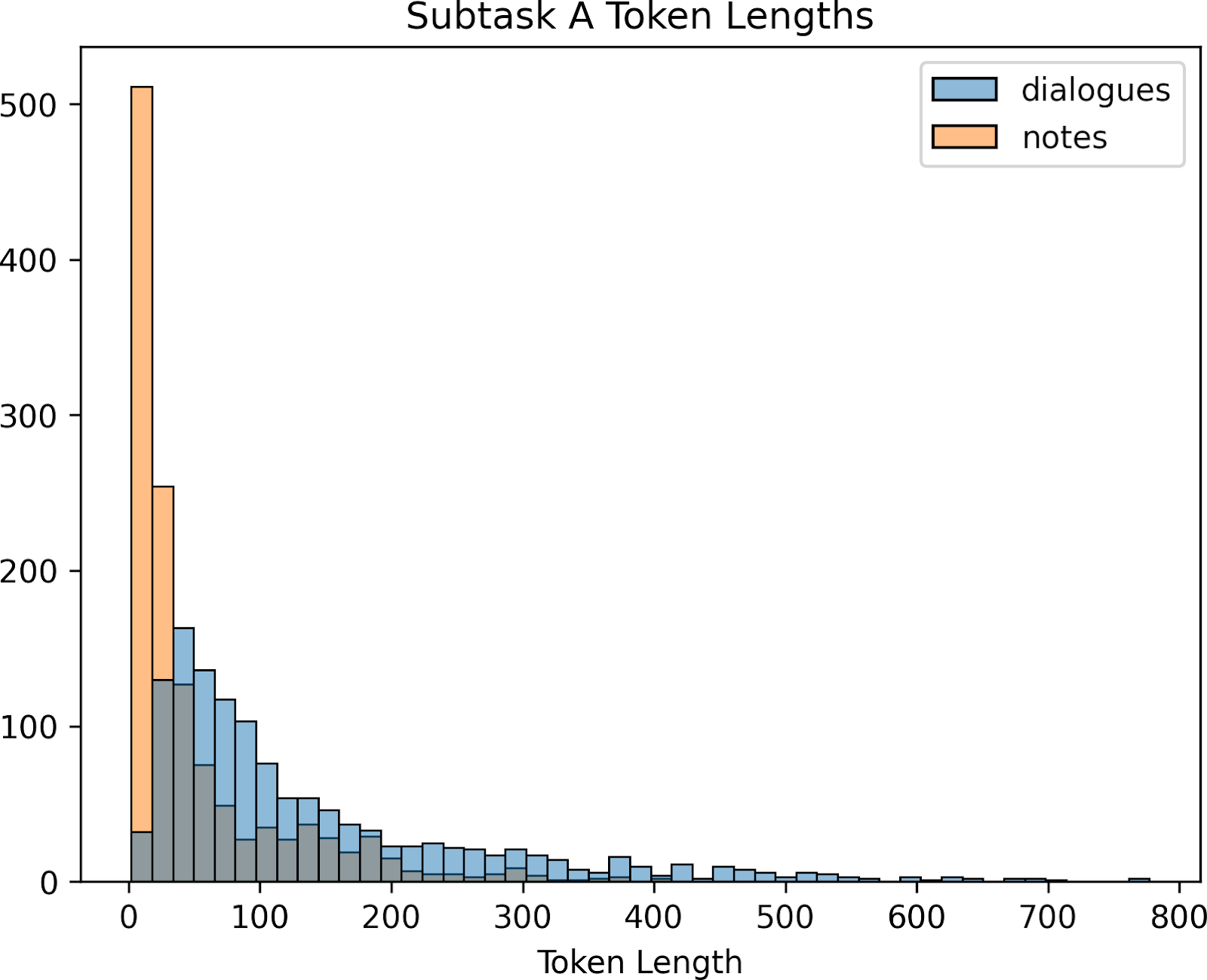
Figure 6: Histogram of token lengths for subtask A train and validation sets. Dialogues and notes were tokenized with HuggingFace Tokenizers using “google/flan-t5-large”. Lengths greater than the 99th-percentile are omitted to make the plot legible.
그림 6: 하위 작업 A 훈련 및 검증 세트에 대한 토큰 길이 히스토그램. 대화와 메모는 "google/flan-t5-large"를 사용하여 HuggingFace 토큰화 도구로 토큰화했다. 가독성을 높이기 위해 99번째 백분위수보다 큰 길이는 생략되었다.
-
Subtask B
We lightly tuned the hyperparameters of LEDLARGE-PubMed on the subtask B validation set against the average ROUGE-1 F1, BERTScore F1 and BLEURT-20 scores. The best hyperparameters obtained are given in Table 6. We used the same hyperparameters when fine-tuning LEDBASE and LEDLARGE in §4.1.
서브태스크 B 검증 세트에서 평균 ROUGE-1 F1, BERTScore F1 및 BLEURT-20 점수와 비교하여 LEDLARGE-PubMed의 하이퍼파라미터를 가볍게 조정했다. 얻은 최상의 하이퍼파라미터는 표 6에 나와 있다. 4.1절에서 LEDBASE 및 LEDLARGE를 미세 조정할 때도 동일한 하이퍼파라미터를 사용했다.
- Post processing LEDs outputs
In practice, we found that the fine-tuned LED model sometimes produces invalid section headers; notably, this problem did not occur with the ICL-based approach using GPT-4. Therefore, we lightly post-processed LEDs outputs using a simple script that identifies section headers produced by the model not in the ground truth set and uses fuzzy string matching15 to replace them with the closest valid header. For example, in one run, this process converted the (incorrect) predicted section header “HISTORY OF PRESENT” to the nearest valid header “HISTORY OF PRESENT ILLNESS”.
실제로 미세 조정된 LED 모델이 때때로 잘못된 섹션 헤더를 생성하는 것을 발견했다. 특히 GPT-4를 사용하는 ICL 기반 접근 방식에서는 이 문제가 발생하지 않았다. 따라서 기준 데이터 세트에 없는 섹션 헤더를 식별하고 퍼지 문자열 매칭15을 사용하여 가장 가까운 유효한 헤더로 대체하는 간단한 스크립트를 사용하여 LED 출력을 가볍게 후처리했다. 예를 들어, 한 번의 실행에서 이 프로세스는 (잘못된) 예측 섹션 헤더인 "현재 상태"를 가장 가까운 유효한 헤더인 "현재 상태 없음"으로 변환했다.
Table 4: Hyperparameters used with FLAN-T5 on the Dialogue2Note subtask A
Hyperparameter Value Comment
max_source_length 1024 truncate input sequences to this max length
max_target_length 512 truncate output sequences to this max length
source_prefix “Summarize the following patient-
doctor dialogue. Include all medically relevant information, including family history, diagnosis, past medical (and surgical) history, immunizations, lab results and known allergies. You should first predict the most relevant clinical note section header and then summarize the dialogue. Dialogue:”
instruction text prepended to all inputs
train_batch_size 8 batch size during training
eval_batch_size 12 batch size during inference
learning_rate 1e-4 learning rate during training
optimizer AdamW (Loshchilov and Hutter,
2019)
optimizer used during training
num_train_epochs 20 total number of training epochs
warmup_ratio 0.1 proportion of training steps to linearly increase the learning rate to learning_rate
lr_scheduler linear with warmup learning rate linearly increased during first
warmup_ratio fraction of train steps and linearly decreased to 0 afterwords
weight_decay 0.01 not applied to bias & LayerNorm weights
label_smoothing 0.1 label smoothing factor used during training
bf16 true whether to use BF16 during training
num_beams 2 beam size used during beam search decoding
Table 5: Fine-tuning FLAN-T5. Accuracy of predicted section headers and score of generated note sections is shown. Jointly learning to predict section headers and generate notes improve performance. Bold: best scores.
표 5: FLAN-T5 미세 조정하기. 예측된 섹션 헤더의 정확도와 생성된 노트 섹션의 점수가 표시되어 있다. 섹션 헤더 예측과 노트 생성을 공동으로 학습하면 성능이 향상된다. 굵게 표시: 최고 점수.
C. Fine-tuning Seq2Seq Models
When training the sequence-to-sequence (seq2seq) models for both subtask A (Appendix A) and B (§3.1), we followed a canonical supervised fine-tuning (SFT) process. We start with a pretrained, encoder-decoder transformer-based language model (Vaswani et al., 2017). First, the encoder maps each token in the input to a contextual embedding. Then, the autoregressive decoder generates an output, token-by-token, attending to the outputs of the encoder at each timestep. Decoding proceeds until a special “end-of-sequence” token (e.g. </s>) is generated, or a maximum number of tokens have been generated. Formally, X is the input sequence, which in our case is a doctor-patient dialogue, and Y is the corresponding output sequence of length T , in our case a clinical note. We model the conditional probability:
서브태스크 A(부록 A)와 B(§3.1)에 대한 시퀀스 간(seq2seq) 모델을 훈련할 때 표준 감독 미세 조정(SFT) 프로세스를 따랐다. 먼저 사전 학습된 인코더-디코더 트랜스포머 기반 언어 모델(Vaswani et al., 2017)로 시작한다. 먼저 인코더가 입력의 각 토큰을 문맥 임베딩에 매핑한다. 그런 다음 자동 회귀 디코더는 각 타임스텝에서 인코더의 출력에 따라 토큰 단위로 출력을 생성한다. 디코딩은 특수한 "시퀀스 끝" 토큰(예: </s>)이 생성되거나 최대 토큰 수가 생성될 때까지 계속 진행된다. 공식적으로 X는 입력 시퀀스(이 경우 의사-환자 대화)이고, Y는 길이 T의 대응하는 출력 시퀀스(이 경우 임상 메모)이다. 조건부 확률을 모델링한다:

During training, we optimize over the model parameters θ the sequence cross-entropy loss:
훈련 중에 모델 파라미터 θ에 대해 시퀀스 교차 엔트로피 손실을 최적화한다:
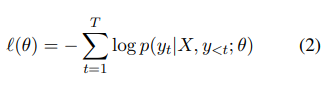
Table 6: Hyperparameters used with Longformer-Encoder-Decoder (LED) on the Dialogue2Note subtask B
표 6: 다이얼로그2노트 하위 작업 B에서 롱포머-인코더-디코더(LED)와 함께 사용되는 하이퍼파라미터
Hyperparameter Value Comment
max_source_length 4096 truncate input sequences to this max length
max_target_length 1024 truncate output sequences to this max length
source_prefix “Summarize the following patient-
doctor dialogue. Include all medically relevant information, including family history, diagnosis, past medical (and surgical) history, immunizations, lab results and known allergies. Dialogue:”
instruction text prepended to all inputs
train_batch_size 8 batch size during training
eval_batch_size 6 batch size during inference
learning_rate 3e-5 learning rate during training
optimizer AdamW (Loshchilov and Hutter,
2019)
optimizer used during training
num_train_epochs 50 total number of training epochs
warmup_ratio 0.1 proportion of training steps to linearly increase the learning rate to learning_rate
lr_scheduler linear with warmup learning rate linearly increased during first
warmup_ratio fraction of train steps and linearly decreased to 0 afterwords
weight_decay 0.01 not applied to bias & LayerNorm weights
label_smoothing 0.1 label smoothing factor used during training
fp16 true whether to use FP16 during training
num_beams 4 beam size used during beam search decoding
min_length 100 min length of generated sequences
max_length 1024 max length of generated sequences
length_penalty 2.0 values > 0 promote longer output sequences
no_repeat_ngram 3 ngrams of this size can only occur once
maximizing the log-likelihood of the training data. As is common, we use teacher forcing during training, feeding previous ground truth inputs to the decoder when predicting the next token in the sequence. During inference, we generate the output using beam search (Graves, 2012). Beams are ranked by mean token log probability after applying a length penalty. Models are fine-tuned using the HuggingFace Transformers library.16
훈련 데이터의 로그 가능성을 최대화한다. 일반적인 경우와 마찬가지로, 훈련 중에 교사 포싱을 사용하여 시퀀스의 다음 토큰을 예측할 때 이전 기준값 입력을 디코더에 공급한다. 추론 중에는 빔 검색을 사용하여 출력을 생성한다(Graves, 2012). 빔은 길이 페널티를 적용한 후 평균 토큰 로그 확률에 따라 순위가 매겨진다. 모델은 HuggingFace 트랜스포머 라이브러리를 사용하여 미세 조정된다.16
16https://github.com/huggingface/transformers/
blob/main/examples/pytorch/summarization/run_ summarization.py


