원문 : https://arxiv.org/abs/2309.03852
이 글에 대한 모든 권리는 원문 저자에게 있음.
###
FLM-101B: An Open LLM and How to Train It with $100K Budget
Xiang Li1†, Yiqun Yao1†, Xin Jiang1†, Xuezhi Fang1†, Xuying Meng2, Siqi Fan3, Peng Han3, Jing Li4, Li Du1, Bowen Qin1, Zheng Zhang1, Aixin Sun5, Yequan Wang1∗
1Beijing Academy of Artificial Intelligence, Beijing, China
2Institute of Computing Technology, Chinese Academy of Sciences, Beijing, China 3University of Electronic Science and Technology of China, Chengdu, China 4Harbin Institute of Technology, Shenzhen, China
5School of Computer Science and Engineering, Nanyang Technological University, Singapore
Abstract
Large language models (LLMs) have achieved remarkable success in NLP and multimodal tasks, among others. Despite these successes, two main challenges remain in developing LLMs: (i) high computational cost, and (ii) fair and objective evaluations. In this paper, we report a solution to significantly reduce LLM training cost through a growth strategy. We demonstrate that a 101B-parameter LLM with 0.31T tokens can be trained with a budget of 100K US dollars. Inspired by IQ tests, we also consolidate an additional range of evaluations on top of existing eval- uations that focus on knowledge-oriented abilities. These IQ evaluations include symbolic mapping, rule understanding, pattern mining, and anti-interference. Such evaluations minimize the potential impact of memorization. Experimental results show that our model, named FLM-101B, trained with a budget of $100K, achieves performance comparable to powerful and well-known models, e.g., GPT-3 and GLM-130B, especially on the additional range of IQ evaluations. The checkpoint of FLM-101B is released at https://huggingface.co/CofeAI/FLM-101B.
대규모 언어 모델(LLM)은 자연어 처리와 다중 모드 작업 등에서 괄목할 만한 성공을 거두었다. 이러한 성공에도 불구하고 LLM 개발에는 (i) 높은 계산 비용과 (ii) 공정하고 객관적인 평가라는 두 가지 주요 과제가 남아있다. 이 논문에서는 성장 전략을 통해 LLM 훈련 비용을 크게 절감할 수 있는 솔루션을 소개한다. 0.31T 토큰이 포함된 101B 파라미터 LLM을 10만 달러의 예산으로 훈련할 수 있음을 입증한다. 또한 IQ 테스트에서 영감을 받아 지식 중심 능력에 초점을 맞춘 기존 평가에 추가적인 평가 범위를 통합했다. 이러한 IQ 평가에는 심볼릭 매핑, 규칙 이해, 패턴 마이닝, 간섭 방지 등이 포함된다. 이러한 평가는 암기의 잠재적 영향을 최소화한다. 실험 결과에 따르면 10만 달러의 예산으로 훈련된 FLM-101B라는 이름의 모델은 특히 추가 범위의 IQ 평가에서 강력하고 잘 알려진 모델(예: GPT-3 및 GLM-130B)에 필적하는 성능을 달성하는 것으로 나타났다. FLM-101B의 체크포인트는 https://huggingface.co/CofeAI/FLM-101B 에서 확인할 수 있다.
1. Introduction
Large language models (LLMs) have demonstrated great successes in a wide range of tasks, particularly in language processing [65; 64; 11; 30] and multimodal tasks [82; 33]. Throughout their development, many model architectures have been proposed and evaluated, including decoder- only structures (e.g., the GPT series [40; 41; 3] and the LLAMA series [58; 59]), encoder-only structures (e.g., BERT [10]), and encoder-decoder structures (e.g., T5 [44]), along with their vari- ants [29; 21; 55; 45]. Regardless of the differences in model architectures, all LLMs face the same challenge of high training cost. There is also a current trend suggesting using larger amounts of training data. For example, the LLAMA-1 [58] models use 1-1.4 T tokens for training, while LLAMA-2 [59] series use 2T tokens. A primary emphasis in LLM research hence is to find effective solutions to reduce training costs.
대규모 언어 모델(LLM)은 다양한 작업, 특히 언어 처리 [65; 64; 11; 30] 및 다중 모드 작업 [82; 33]에서 큰 성공을 거두었다. 개발 과정에서 디코더 전용 구조(예: GPT 시리즈 [40; 41; 3] 및 LLAMA 시리즈 [58; 59]), 인코더 전용 구조(예: BERT [10]), 인코더-디코더 구조(예: T5 [44]) 및 그 변형[29; 21; 55; 45] 등 많은 모델 아키텍처가 제안 및 평가되었다. 모델 아키텍처의 차이에 관계없이 모든 LLM은 높은 훈련 비용이라는 동일한 문제에 직면해 있다. 또한 최근에는 더 많은 양의 학습 데이터를 사용하는 추세이다. 예를 들어, LLAMA-1 [58] 모델은 트레이닝에 1-1.4T 토큰을 사용하는 반면, LLAMA-2 [59] 시리즈는 2T 토큰을 사용한다. 따라서 LLM 연구에서 가장 중점을 두는 것은 훈련 비용을 절감할 수 있는 효과적인 솔루션을 찾는 것이다.
In this paper, we present our solutions to train an LLM at the 100B-parameter scale using a growth strategy inspired by our previous research [78]. “Growth” means that the number of parameters is not fixed, but expands from small to large along the training progresses. Figure 1 illustrates three typical scenarios for growth strategies. As the FLOPs of LLMs are approximately proportional to their number of parameters [19], the area under the parameter curve represents the computational cost of training. Figure 1(a) serves as a reference for the cost with a constant number of parameters (y-axis)
이 논문에서는 이전 연구[78]에서 영감을 얻은 성장 전략을 사용하여 100B 파라미터 규모에서 LLM을 훈련하는 솔루션을 제시한다. "성장"이란 파라미터의 수가 고정되어 있지 않고 훈련이 진행되면서 작은 것에서 큰 것으로 확장되는 것을 의미한다. 그림 1은 성장 전략에 대한 세 가지 일반적인 시나리오를 보여준다. LLM의 FLOP은 파라미터 수에 거의 비례하므로[19], 파라미터 곡선 아래의 면적은 트레이닝의 계산 비용을 나타낸다. 그림 1(a)는 파라미터 수가 일정한 경우의 비용(y축)에 대한 참조이다.
*Corresponding author. Email: tshwangyequan@gmail.com
†Indicates equal contribution.

Figure 1: An overview of different growth strategies.
w.r.t. the number of tokens (x-axis). Figure 1(b) illustrates a straightforward linear growth strategy, leading to a cost-saving of exactly 50%; Figure 1(c) showcases a modest growth strategy that reduces the cost by less than 50%; in contrast, Figure 1(d) represents an aggressive growth strategy, which reduces the cost by more than 50%. This analysis informs our decision to employ the aggressive growth strategy for maximal computational savings. In our model training, we achieve aggressive growth with an enhanced growth strategy originated in our previous work MSG [78], a strategy that achieves strict function-preserving when growing.
토큰 수(X축)를 기준으로 한다. 그림 1(b)는 비용을 정확히 50% 절감하는 간단한 선형 성장 전략을, 그림 1(c)는 비용을 50% 미만 절감하는 적당한 성장 전략을, 반대로 그림 1(d)는 비용을 50% 이상 절감하는 공격적인 성장 전략을 보여준다. 이 분석을 통해 계산 비용을 최대로 절감하기 위해 공격적인 성장 전략을 사용하기로 결정했다. 모델 훈련에서 우리는 이전 작업인 MSG [78]에서 유래한 향상된 성장 전략으로 공격적인 성장을 달성했는데, 이는 성장 시 엄격한 함수 보존function-preserving을 달성하는 전략이다.
With a fixed $100K budget, we focus on 100B+ parameters. Although the Chinchilla laws [19] suggest that training a smaller model with more data may potentially result in higher scores on some benchmarks due to more sufficient training, we believe that verifying the feasibility of a growth strategy [15; 51; 6; 78] would be a new direction and beneficial to the community of LLM as well. This is because (i) larger models have higher upper bounds for capabilities that may not be reached by scaling only the training data [69], and (ii) data can be linearly scaled up with the budget, while a growth strategy has the potential for saving cost regardless of the amount of available data, if it turns out to be feasible. Existing studies such as [19] have not extensively investigated this area because they only consider the scenarios where model sizes are fixed through training.
10만 달러의 고정 예산으로 100억 개 이상의 파라미터에 집중한다. 친칠라 법칙[19]에 따르면 더 많은 데이터로 더 작은 모델을 훈련하면 더 충분한 훈련으로 인해 일부 벤치마크에서 더 높은 점수를 받을 수 있지만, 우리는 성장 전략[15; 51; 6; 78]의 타당성을 검증하는 것이 새로운 방향이며 LLM 커뮤니티에도 도움이 될 것이라고 믿는다. 그 이유는 (i) 모델이 클수록 훈련 데이터만 확장해서는 도달할 수 없는 기능의 상한이 높고[69], (ii) 데이터는 예산에 따라 선형적으로 확장할 수 있는 반면, 성장 전략은 실현 가능한 것으로 판명될 경우 사용 가능한 데이터의 양과 관계없이 비용을 절감할 수 있는 잠재력을 가지고 있기 때문이다. 19]와 같은 기존 연구에서는 훈련을 통해 모델 크기가 고정된 시나리오만 고려했기 때문에 이 영역을 광범위하게 조사하지 않았다.
Another critical challenge in LLM research is evaluation. Existing mainstream evaluations can be broadly grouped into two categories: knowledge evaluation (i.e., MMLU [17] and C-Eval [20]), and NLP tasks evaluation. Such evaluations may not fully reflect the model capability due to potential data leakage if some of the evaluation datasets were also used in model training. In addition, it is also difficult to distinguish whether the models remember a piece of knowledge or possess the capacity for reasoning and/or inference. Borrowing some ideas from Intelligence Quotient (IQ) tests (i.e., Perceptual Reasoning and Working Memory [67]), we consolidate another range of evaluations on LLMs, including symbolic mapping, rule understanding, pattern mining, and anti-interference evaluations. Symbolic mapping [71] evaluation tests the capability of LLMs in learning to use (less meaningful) symbols instead of (more meaningful) category labels for some forms of classification tasks. Rule understanding evaluation is to test the capability of understanding some given rules, and then to perform corresponding actions. Pattern mining (involving both induction and deduction), is often used in various levels of competition. It tests the pattern-finding capability (e.g., repetition of certain parts of a given input). Last but not least, anti-interference is an ability to recognize core information from noisy input [5; 84]. We believe the evaluations inspired by IQ tests are less likely to be affected by data leakage or memorization, hence providing another dimension for fair, objective, and reliable evaluations of LLMs.
LLM 연구에서 또 다른 중요한 과제는 평가이다. 기존의 주류 평가는 크게 두 가지 범주로 분류할 수 있다: 지식 평가(예: MMLU [17] 및 C-Eval [20])와 NLP 작업 평가. 이러한 평가는 평가 데이터 세트 중 일부가 모델 학습에도 사용된 경우 잠재적인 데이터 유출로 인해 모델 성능을 충분히 반영하지 못할 수 있다. 또한 모델이 특정 지식을 기억하고 있는지, 추론 및/또는 추론 능력을 보유하고 있는지를 구분하는 것도 어렵다. 지능지수(IQ) 테스트(예: 지각 추론 및 작업 기억[67])에서 몇 가지 아이디어를 차용하여 기호 매핑, 규칙 이해, 패턴 마이닝, 간섭 방지 평가 등 LLM에 대한 또 다른 범위의 평가를 통합했다. 기호 매핑[71] 평가는 일부 형태의 분류 작업에서 (더 의미 있는) 카테고리 레이블 대신 (덜 의미 있는) 기호를 사용하는 방법을 학습하는 데 있어 LLM의 능력을 테스트한다. 규칙 이해 평가는 주어진 규칙을 이해하고 해당 작업을 수행할 수 있는 능력을 테스트하는 것이다. 패턴 마이닝(귀납과 연역 모두 포함)은 다양한 수준의 경쟁에서 자주 사용된다. 패턴 찾기 기능(예: 주어진 입력의 특정 부분 반복)을 테스트한다. 마지막으로 간섭 방지 기능은 잡음이 많은 입력에서 핵심 정보를 인식하는 능력이다[5; 84]. 저희는 IQ 테스트에서 영감을 얻은 평가가 데이터 유출이나 암기의 영향을 덜 받기 때문에 LLM에 대한 공정하고 객관적이며 신뢰할 수 있는 평가를 위한 또 다른 차원을 제공한다고 믿는다.
To summarize, the paper has made the following contributions. First, to the best of our knowledge, this is the first attempt to use a growth strategy to train an LLM with 100B+ parameters from scratch. Simultaneously, it is probably the lowest-cost model with 100B+ parameters, costing only 100,000 US dollars. Second, we address several instability issues via promising approaches for hyperparameter search, function-preserving growth, and improvements based on our FreeLM [25]. Our methodology holds potential benefits for the broader research community. Third, we conduct extensive evaluations, including both the commonly used knowledge-oriented benchmarks and the new range of evaluations inspired by IQ tests. Experimental results show that, despite its low training cost, FLM-101B is competitive and robust. Lastly, we release the model checkpoints, code, related tools, et al. to promote research on bilingual Chinese and English LLMs at the scale of 100B+.
요약하자면, 이 논문은 다음과 같은 공헌을 했다. 첫째, 우리가 아는 한, 성장 전략growth strategy을 사용하여 100억 개 이상의 파라미터를 가진 LLM을 처음부터 학습시킨 것은 이번이 처음이다. 동시에, 100억 개 이상의 파라미터를 가진 모델 중 가장 낮은 비용으로 10만 달러에 불과한 모델일 것이다. 둘째, 우리는 하이퍼파라미터 검색, 함수 보존 성장, FreeLM[25]에 기반한 개선에 대한 유망한 접근 방식을 통해 몇 가지 불안정성 문제를 해결한다. 우리의 방법론은 광범위한 연구 커뮤니티에 잠재적인 이점을 제공한다. 셋째, 일반적으로 사용되는 지식 중심 벤치마크와 IQ 테스트에서 영감을 얻은 새로운 범위의 평가를 모두 포함하여 광범위한 평가를 수행한다. 실험 결과에 따르면 FLM-101B는 낮은 훈련 비용에도 불구하고 경쟁력이 있고 강력한 것으로 나타났다. 마지막으로 모델 체크포인트, 코드, 관련 도구 등을 공개하여 100억 달러 이상의 규모로 중국어와 영어 이중 언어 LLM에 대한 연구를 촉진한다.
2. Design Overview of FLM-101B
In this section, we provide an outline of FLM-101B, detailing its architecture, pre-training methods, and configuration specifics.
이 섹션에서는 FLM-101B의 아키텍처, 사전 교육 방법 및 구성 세부 사항을 자세히 설명하는 개요를 제공한다.
2.1 Architecture
The architecture of an LLM significantly impacts its capabilities. Current researches [80; 3] under- score the high costs associated with experimenting on diverse architectures. Hence, it is more suitable to select an architecture with great potential for cost effectiveness and model capability.
LLM의 아키텍처는 그 기능에 큰 영향을 미친다. 기존 연구[80; 3]에서는 다양한 아키텍처를 실험하는 데 드는 높은 비용을 과소평가하고 있다. 따라서 비용 효율성과 모델 기능에 대한 잠재력이 큰 아키텍처를 선택하는 것이 더 적합하다.
Backbone. Among the many existing model architectures, we adopt FreeLM [25] as the backbone for our models, with modifications. FreeLM is based on GPT [41], a transformer-like architecture with a decoder-only configuration known for its exceptional performance. Different from GPT, FreeLM features two pre-training objectives: the language objective and the teacher objective (Section 2.2). We preserve the GPT-style transformer block designs, including the Pre-LayerNorm and the additional LayerNorm after the last transformer layer. We employ the tokenizer derived from GPT-4, characterized by a vocabulary size of 100, 256.
백본. 기존의 많은 모델 아키텍처 중에서 FreeLM[25]을 수정하여 모델의 백본으로 채택했다. FreeLM은 뛰어난 성능으로 잘 알려진 디코더 전용 구성의 변압기형 아키텍처인 GPT[41]를 기반으로 한다. FreeLM은 GPT와 달리 언어 목표와 선생 목표라는 두 가지 사전 학습 목표를 제공한다(섹션 2.2). 프리-레이어노름과 마지막 트랜스포머 레이어 이후의 추가 레이어노름을 포함한 GPT 스타일의 트랜스포머 블록 설계를 유지한다. 저희는 100, 256의 어휘 크기가 특징인 GPT-4에서 파생된 토큰화기를 사용한다.
Integration of xPos. To enhance long sequence modeling, we integrate the Extrapolatable Position Embedding (xPos) [56] in FLM-101B. This innovation draws inspiration from the principles of RoPE [54], which aims to improve the length extrapolation ability. By introducing an exponential decay into the rotation matrix, xPos strives to rectify this hurdle. To the best of our knowledge, FLM-101B is the largest model to date that incorporates the xPos technology.
xPos의 통합. 긴 시퀀스 모델링을 향상시키기 위해, 우리는 외삽 가능한Extrapolatable 위치 임베딩(xPos)[56]을 FLM-101B에 통합했다. 이 혁신은 길이 외삽length extrapolation 능력을 향상시키는 것을 목표로 하는 RoPE [54]의 원리에서 영감을 얻었다. 회전 행렬에 기하급수적 감쇠를 도입함으로써 xPos는 이러한 장애물을 바로잡기 위해 노력한다. 우리가 아는 한, FLM-101B는 현재까지 xPos 기술을 통합한 모델 중 가장 큰 모델이다.
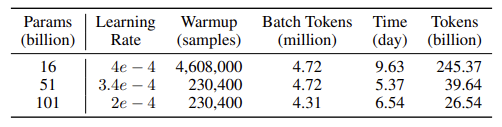
Model Sizes. Benefiting from the proposed growth strategy, the FLM series produces three models with 16B, 51B, and 101B (i.e., FLM-101B) parameters in a single training. The training process is carried out in a sequential manner, starting from a smaller model (i.e., 16B) and progressively growing to larger ones (i.e., 51B and 101B).
모델 크기. 제안된 성장 전략의 이점을 활용하여 FLM 시리즈는 단일 트레이닝에서 16B, 51B, 101B(즉, FLM-101B) 파라미터를 가진 세 가지 모델을 생산한다. 훈련 프로세스는 더 작은 모델(예: 16B)에서 시작하여 점진적으로 더 큰 모델(예: 51B 및 101B)로 성장하는 순차적인 방식으로 수행된다.
2.2 Pre-Training Setup
FLM-101B. By design, FLM-101B is an English-Chinese bilingual model pre-trained with causal language modeling. It mixes English and Chinese corpora at a ratio of approximately 53.5% : 46.5% for language modeling. Inspired by the finding that instruction data can augment LLMs’ comprehension capabilities [37], we integrate multi-task instructionally prompted data: OIG (Open Instruction Generalist) 1 and COIG (Chinese Open Instruction Generalist) 2, in the pre-training stage.
FLM-101B. FLM-101B는 인과적 언어 모델링으로 사전 학습된 영어-중국어 이중 언어 모델이다. 언어 모델링을 위해 영어와 중국어 코퍼스를 약 53.5% : 46.5%의 비율로 혼합한다. 명령어 데이터가 LLM의 이해 능력을 강화할 수 있다는 연구 결과[37]에서 아이디어를 얻어, 멀티태스크 명령어 데이터를 통합했다: 사전 훈련 단계에서 OIG(Open Instruction Generalist) 1과 COIG(Chinese Open Instruction Generalist) 2를 통합한다.
eFLM-16B. To evaluate the effect of using domain-specific knowledge data (Section 4.2), we apply the FreeLM teacher signals [25] to enhance FLM. Due to computational cost, we incorporate the teacher signals only in the smallest 16B.
eFLM-16B. 도메인별 지식 데이터(섹션 4.2) 사용의 효과를 평가하기 위해 FreeLM 선생 신호[25]를 적용하여 FLM을 향상시킨다. 계산 비용으로 인해 선생 신호는 가장 작은 16B에만 통합한다.
model. This knowledge-enhanced FLM-16B is named eFLM-16B.
1https://huggingface.co/datasets/laion/OIG 2https://huggingface.co/datasets/BAAI/COIG
Table 1: Partial configurations for different growth stages.
The original FreeLM incorporates two training objectives: language modeling objective guided by language signals and binary classification objective guided by teacher signals. In FLM-101B, we unify the two objectives by using a masking strategy and two specialized tokens. These tokens facilitate the transformation of the binary classification objective into the unified language modeling format. The unified training objective leads to training stability when the model becomes much larger in scale. Hence, for eFLM-16B, we transform this binary classification into the format of causal language modeling. Specifically, we employ two emojis: 😈 (U+1F621) and (U+1F608) 3, from the vocabulary to replace the original binary labels of 1 and 0. We apply zero-masking to the loss for tokens in the propositions and predict one of these two special tokens at the end of each proposition. By this method, we unify the teacher objective and language modeling. Moreover, we discard the original Iterative Training approach [25] and completely mix the samples from both signals in every batch. This strategy can enhance the consistency of data sampling distribution as well as improve training stability.


기존 FreeLM에는 언어 신호에 따른 언어 모델링 목표와 선생 신호에 따른 이진 분류 목표라는 두 가지 훈련 목표가 통합되어 있다. FLM-101B에서는 마스킹 전략과 두 개의 특수 토큰을 사용하여 두 가지 목표를 통합한다. 이러한 토큰은 이진 분류 목표를 통합 언어 모델링 형식으로 쉽게 변환할 수 있게 해준다. 통합된 훈련 목표는 모델의 규모가 훨씬 커질 때 훈련 안정성으로 이어집니다. 따라서 eFLM-16B의 경우 이 이진 분류를 인과적 언어 모델링 형식으로 변환한다.
언어 모델링 형식으로 변환한다. 구체적으로 두 가지 이모티콘을 사용한다: 😈 (U+1F621) 및 (U+1F608) 3의 두 가지 이모티콘을 사용한다. 어휘에서 원래의 이진 레이블인 1과 0을 대체한다. 명제의 토큰 손실에 제로 마스킹을 적용하고 각 명제의 끝에 있는 이 두 가지 특수 토큰 중 하나를 예측한다. 이 방법을 통해 선생 목표와 언어 모델링을 통합한다. 또한, 기존의 반복 훈련 접근 방식[25]을 버리고 모든 배치에서 두 신호의 샘플을 완전히 혼합한다. 이 전략은 데이터 샘플링 분포의 일관성을 높이고 훈련 안정성을 향상시킬 수 있다.
2.3 Growth Strategy
The essence of the low cost in scaling FLM-101B up is the growth strategy in model training. Specifically, we train three models, with 16B, 51B, and 101B parameters respectively, in a sequential manner. Each model inherits knowledge from its predecessor. This is contrary to the common practice that the models of different sizes are trained independently [58; 59].
FLM-101B를 저렴한 비용으로 확장할 수 있는 핵심은 모델 훈련의 성장 전략이다. 구체적으로는 각각 16B, 51B, 101B 파라미터로 구성된 세 가지 모델을 순차적으로 학습시킵니다. 각 모델은 이전 모델로부터 지식을 상속받는다. 이는 서로 다른 크기의 모델을 독립적으로 훈련하는 일반적인 관행과 상반된다 [58; 59].
Function-preserving Growth. Function preservation means that before and after growth, the models yield consistent outputs given the same arbitrary inputs. This property has proven beneficial for both knowledge inheritance [8; 6; 51] and training stability [78]. The growth operators used in FLM-101B training originate from [78], with improvement. Specifically, to adapt these operators to the multi-node 3D parallel framework, we implement them by extending the model structures offline and reloading the checkpoint when the next stage starts.
기능 보존 성장. 기능 보존은 성장 전후에 동일한 임의의 입력이 주어졌을 때 모델이 일관된 출력을 산출한다는 것을 의미한다. 이 특성은 지식 상속[8; 6; 51] 및 훈련 안정성[78] 모두에 유익한 것으로 입증되었다. FLM-101B 훈련에 사용되는 성장 연산자는 개선된 [78]에서 유래했다. 특히 이러한 연산자를 다중 노드 3D 병렬 프레임워크에 적용하기 위해 모델 구조를 오프라인으로 확장하고 다음 단계가 시작될 때 체크포인트를 다시 로드하는 방식으로 구현했다.
Schedules and Cost-Effectiveness. Model growth scheduling is a trade-off between the pros and cons inherent to models of different sizes [78]: a smaller model is faster in computing each training step, enabling more rapid consumption of training data for broader commonsense knowledge; conversely, a larger model is better in the reduction of loss per step, indicating a deeper understanding of the nuanced linguistic patterns. We train the 16B model with 245.37B tokens, the 51B model with 39.64B tokens, and the 101B model with 26.54B tokens. The billion tokens per day of different sizes are listed in Table 1. Under this growth schedule, the total time cost for our 101B model is 21.54 days, which is 72% time-saving (or a 3.56x speedup) compared to training a 101B model from scratch (76.74 days). This is consistent with our motivations depicted in Figure 1.
스케줄과 비용 효율성. 모델 성장 스케줄링은 다양한 크기의 모델에 내재된 장단점을 절충한 것이다[78]. 작은 모델은 각 훈련 단계를 더 빠르게 계산하여 더 광범위한 상식 지식을 위한 훈련 데이터를 더 빠르게 소비할 수 있으며, 반대로 큰 모델은 단계당 손실 감소에 있어 더 우수하여 미묘한 언어 패턴을 더 깊게 이해할 수 있음을 나타낸다. 16B 모델은 245.37억 개의 토큰으로, 51B 모델은 396.64억 개의 토큰으로, 101B 모델은 265.54억 개의 토큰으로 훈련한다. 크기별로 하루에 생성되는 10억 개의 토큰은 표 1에 나와 있다. 이러한 성장 일정에 따라 101B 모델의 총 소요 시간은 21.54일로, 101B 모델을 처음부터 훈련할 때(76.74일)에 비해 72% 시간을 절약(또는 3.56배 속도 향상)할 수 있다. 이는 그림 1에 묘사된 우리의 동기와 일치한다.
2.4 The Parallelism Setup and Model Configurations
FLM-101B is trained on a cluster of 24 DGX-A800 GPU (8×80G) servers. Following the growth strategy, we sequentially complete the model training for sizes 16B, 51B, and 101B on this cluster.
FLM-101B는 24개의 DGX-A800 GPU(8×80G) 서버로 구성된 클러스터에서 학습된다. 성장 전략에 따라 이 클러스터에서 16B, 51B, 101B 크기에 대한 모델 학습을 순차적으로 완료한다.
The Parallel Strategies. Data parallelism [60] and tensor model parallelism [52] have become the standard approaches for training models at the billion scale. Nevertheless, an excessive amount of tensor parallelism may escalate GPU communication overheads, hampering training efficiency. To tackle this problem, we integrate pipeline model parallelism [35] and employ a 3D parallel strategy for optimal throughput. Moreover, by employing sequence parallelism [24], we slice the inputs to the Transformer core’s LayerNorm and Dropout layers along the sequence length dimension, leading to additional savings in GPU computational resources and memory utilization. We also utilize the Megetron-LM 4 implementation of the distributed optimizer [46] to further reduce the GPU memory consumption, which is a technique that evenly distributes the optimizer states across data parallel ranks.
병렬 전략. 데이터 병렬 처리[60]와 텐서 모델 병렬 처리[52]는 10억 개 규모의 모델을 훈련하기 위한 표준 접근 방식이 되었다. 그럼에도 불구하고 과도한 양의 텐서 병렬 처리는 GPU 통신 오버헤드를 증가시켜 훈련 효율성을 저해할 수 있다. 이 문제를 해결하기 위해 파이프라인 모델 병렬 처리[35]를 통합하고 최적의 처리량을 위해 3D 병렬 전략을 사용한다. 또한 시퀀스 병렬 처리[24]를 사용하여 시퀀스 길이 차원을 따라 Transformer 코어의 LayerNorm 및 드롭아웃 레이어에 대한 입력을 슬라이스하여 GPU 연산 리소스와 메모리 사용률을 추가로 절감한다. 또한 분산 옵티마이저[46]의 Megetron-LM 4 구현을 활용하여 GPU 메모리 소비를 더욱 줄였는데, 이는 옵티마이저 상태를 데이터 병렬 랭크에 고르게 분배하는 기법이다.
3https://apps.timwhitlock.info/emoji/tables/unicode
Table 2: Parallel strategies and throughput for different growth stages. For NVIDIA A800 GPUs, the peak theoretical FLOPs per second is 312 teraFLOPs/sec. Gradient accumulation is applied for the large global batch size.

Table 2 shows the parallelism configurations and training throughput in each stage of FLM-101B training under our growth strategy. In different stages, we configure different Tensor Parallel Pipeline Parallel sizes to achieve higher throughput. The single-GPU throughput for all three training stages consistently exceeds 160 teraFLOPs/sec with a utilization rate of at least 51.3%. For comparison, GLM-130B achieves 135 teraFLOPs/sec [80] with a 42.27% utilization rate. We can also find that FLM-101B has a higher FLOP utilization rate than Megatron-LM [24] under a similar model size.
표 2는 성장 전략에 따른 FLM-101B 훈련의 각 단계별 병렬 구성과 훈련 처리량을 보여준다. 각 단계마다 더 높은 처리량을 달성하기 위해 다양한 텐서 병렬 파이프라인 병렬 크기를 구성한다. 세 가지 훈련 단계 모두에서 단일 GPU 처리량은 최소 51.3%의 활용률로 초당 160 테라플롭을 지속적으로 초과한다. 비교를 위해 GLM-130B는 42.27%의 사용률로 초당 135 테라FLOPs[80]를 달성한다. 또한 FLM-101B는 비슷한 모델 크기에서 Megatron-LM[24]보다 더 높은 FLOP 활용률을 보인다.
FLM-101B Configurations. The FLM-101B model is structured with a hidden state dimension of 10, 240, a layer number of 80, a context window of 2,048 tokens, 80 attention heads, and a vocabulary size of 100, 256. FLM-101B uses the AdamW optimizer [31] with β1 = 0.9 and β2 = 0.95. A cosine learning rate schedule is employed, leading to a final learning rate of 6e 6. We use a weight decay of 0.1 and gradient clipping of 1.0.
FLM-101B 구성. FLM-101B 모델은 숨겨진 상태 차원 10, 240, 레이어 수 80, 컨텍스트 창 2,048 토큰, 주의 헤드 80개, 어휘 크기 100, 256으로 구성된다. FLM-101B는 β1 = 0.9, β2 = 0.95의 AdamW 옵티마이저[31]를 사용한다. 코사인 학습률 스케줄이 사용되어 최종 학습률은 6e 6이다. 0.1의 가중치 감쇠와 1.0의 그라데이션 클리핑을 사용한다.
Table 1 presents part of the hyperparameters used in different growth stages. In each growth stage, we approximately inherit the previous learning rate and adhere to the same schedule. The learning rate at the beginning of each stage is reported in the table. In the 16B stage, 4,608k samples are used for learning rate warmup, while in later growth stages, we use fewer samples of 230.4k. Note that we do not apply batch size warmup because we address the stability issue in a different manner, detailed in Section 3.
The training duration and token consumption for each stage are also outlined in Table 1. In total, FLM-101B training is accomplished within 22 days using 311.54B tokens.
표 1은 다양한 성장 단계에서 사용되는 하이퍼파라미터의 일부를 보여준다. 각 성장 단계에서는 이전 학습 속도를 대략적으로 상속하고 동일한 일정을 준수한다. 각 단계가 시작될 때의 학습률은 표에 나와 있다. 16B 단계에서는 학습률 워밍업에 4,608천 개의 샘플이 사용되는 반면, 이후 성장 단계에서는 이보다 적은 230.4천 개의 샘플을 사용한다. 안정성 문제는 섹션 3에서 자세히 설명하는 다른 방식으로 해결하기 때문에 배치 크기 워밍업을 적용하지 않습니다.
각 단계의 훈련 기간과 토큰 소비량도 표 1에 요약되어 있다. 총 311.54억 개의 토큰을 사용하여 22일 이내에 FLM-101B 트레이닝이 완료된다.
3. Training Stability of FLM-101B
Models beyond 100B parameters [49; 80] usually suffer from a bunch of notorious stability issues including loss divergence, gradient explosion, and numerical overflow/underflow. This not only inflates the cost of searching for feasible hyperparameters like optimal learning rates, but also intensifies ongoing maintenance during training, such as babysitting, issue resolution, data adjustment, and rebooting. Moreover, this makes the budget of the whole project unpredictable. We have undertaken the following efforts to mitigate these issues.
100B 파라미터[49; 80]를 초과하는 모델은 일반적으로 손실 발산, 기울기 폭발, 수치 오버플로/언더플로 등 악명 높은 안정성 문제를 겪게 된다. 이는 최적의 학습 속도와 같이 실현 가능한 하이퍼파라미터를 찾는 데 드는 비용을 증가시킬 뿐만 아니라 학습 중 베이비시터babysitting, 문제 해결, 데이터 조정, 재부팅과 같은 지속적인 유지보수 작업을 강화한다. 또한 이로 인해 전체 프로젝트의 예산을 예측할 수 없게 된다. 이러한 문제를 완화하기 위해 다음과 같은 노력을 기울였다.
Loss Prediction. The Tensor Programs theories [75; 28] unveil the universal relations across the training dynamics of a series of models with the model width tending to infinite. For certain classes of hyperparameters, this results in a parameterized mapping for their optimal value between a small model and its larger counterparts, which is termed µP [76]. Two important insights are:
손실 예측. 텐서 프로그램 이론[75; 28]은 모델 폭이 무한대로 향하는 일련의 모델의 훈련 역학 전반에 걸친 보편적인 관계를 밝혀낸다. 특정 클래스의 하이퍼파라미터의 경우, 이는 작은 모델과 더 큰 모델 사이의 최적 값에 대한 파라미터화된 매핑을 생성하며, 이를 µP라고 한다[76]. 두 가지 중요한 인사이트가 있다:
The wider, the better: theoretically, under µP transfer, a wider model will always yield lower loss than its narrower counterparts when exposed to identical data [76]. As a direct corollary, if a narrow model converges, its wider counterparts will always converge.
Bfloat16과 혼합 정밀도. 런타임 메모리를 절약하고 시간 비용을 줄이기 위해 혼합 정밀도 훈련을 적용한다. 특히 0에 근접하는 값에 대한 정밀도가 뛰어나 µP에 더 적합한 FP16 대신 Bfloat16을 선택했다. 그 결과, [76]에서 보고한 FP16 언더플로 문제가 발생하지 않는다. 우리가 알기로는 현재 혼합 정밀도 + µP로 성공적으로 훈련된 FLM 모델이 가장 큰 모델이다. 또한, Bfloat16은 손실 스케일 조정의 필요성을 없애기 때문에 훈련 절차가 더욱 유망하고 재현 가능하다.
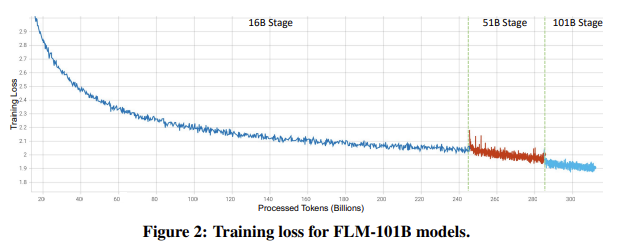
Figure 2: Training loss for FLM-101B models.
Loss prediction: the loss value of a large model is predictable using the loss of its smaller counterparts, as claimed in GPT-4 technical report [36]. For the first time in the open-source world, µScaling [77] provides evidence that loss prediction can be achieved by combining µP [76] and (a modified) scaling law [23; 18; 19].
손실 예측: GPT-4 기술 보고서 [36]에서 주장한 바와 같이, 큰 모델의 손실 값은 작은 모델의 손실을 사용하여 예측할 수 있다. 오픈 소스 세계 최초로 µScaling [77]은 µP [76]와 (수정된) 스케일링 법칙 [23; 18; 19]을 결합하여 손실 예측을 달성할 수 있다는 증거를 제시한다.
Based on these findings, our method to solve training stability is as follows: we first determine the data distribution before the FLM-16B training starts. Next, we perform a grid search on three hyperparameters including the learning rate, initialization standard deviation, and the softmax tem- perature in the output layer. This grid search is performed by running a proxy model (less than 100M ) with a hidden state dimension (“model width”) of 256 and a head number of 2. All the other structural hyperparameters and training data of the proxy model are identical to those of FLM-16B. A single run of grid search takes 24.6 hours with data parallelism on 6 nodes, which is equivalent to 6 hours per run given our 24-node infrastructure. Finally, We find a group of well-performing hyperparameters: learning rate = 4e 4, standard deviation = 1.6e 2, and softmax temperature = 2.0, through this grid search. Transferring these hyperparameters to the 16B model via µP [76] led to a seamless training experience devoid of instabilities. Combining with MSG [78], we also witness no post-growth divergence in FLM-51B and FLM-101B.
이러한 결과를 바탕으로 훈련 안정성을 해결하기 위한 방법은 다음과 같다. 먼저 FLM-16B 훈련을 시작하기 전에 데이터 분포를 결정한다. 다음으로 학습 속도, 초기화 표준편차, 출력 레이어의 소프트맥스 온도 등 세 가지 하이퍼파라미터에 대해 그리드 검색을 수행한다. 이 그리드 검색은 숨겨진 상태 차원("모델 폭")이 256이고 헤드 수가 2인 프록시 모델(100M 미만)을 실행하여 수행된다. 프록시 모델의 다른 모든 구조적 하이퍼파라미터와 훈련 데이터는 FLM-16B의 그것과 동일하다. 그리드 검색을 한 번 실행하는 데는 6개의 노드에서 데이터 병렬 처리로 24.6시간이 걸리며, 이는 24개의 노드 인프라를 고려할 때 실행당 6시간에 해당한다. 마지막으로, 이 그리드 검색을 통해 학습률 = 4e 4, 표준 편차 = 1.6e 2, 소프트맥스 온도 = 2.0과 같은 우수한 성능의 하이퍼파라미터 그룹을 찾았다. 이러한 하이퍼파라미터를 µP[76]를 통해 16B 모델로 전송한 결과 불안정성 없이 원활한 훈련 환경을 구축할 수 있었다. MSG [78]와 결합하여 FLM-51B 및 FLM-101B에서 성장 후 발산도 관찰되지 않았다.
The full training loss curve is presented in Figure 2. The first stage (16B) stably goes through 246B tokens. Immediately afterwards, FLM grows from 16B to 51B. As expected, the training is stable. More importantly, we observe that the loss curve becomes steeper. It matches the intuition that a larger model is better in loss reduction per step. Subsequently, FLM grows to 101B. Although the training data for the 51B stage are only 40B tokens, the 101B training remains stable, and the loss curve becomes slightly steeper again. This loss curve proves the effectiveness of the growth strategy.
전체 훈련 손실 곡선은 그림 2에 나와 있다. 첫 번째 단계(16B)는 246B 토큰을 안정적으로 통과한다. 그 직후 FLM은 16B에서 51B로 증가한다. 예상대로 훈련은 안정적이다. 더 중요한 것은 손실 곡선이 가파르게 변하는 것을 관찰할 수 있다는 것이다. 이는 모델이 클수록 단계당 손실 감소가 더 우수하다는 직관과 일치한다. 그 후 FLM은 101B로 증가한다. 51B 단계의 학습 데이터는 40B 토큰에 불과하지만 101B 학습은 안정적으로 유지되며 손실 곡선이 다시 약간 가파르게 된다. 이 손실 곡선은 성장 전략의 효과를 증명한다.
Our implementations of µP are largely consistent with those in µScaling [77], with modifications to handle the rotary embedding. Thus, the intermediate loss ranges for FLM-16B are also predictable with the results from multiple proxy widths at the same steps.
우리의 µP 구현은 회전식 임베딩을 처리하기 위한 수정 사항을 제외하고는 µScaling [77]의 구현과 대체로 일치한다. 따라서 FLM-16B의 중간 손실 범위는 동일한 단계에서 여러 프록시 폭의 결과를 통해 예측할 수 있다.
Mixed Precision with Bfloat16. We apply mixed-precision training to save run-time memory and reduce time costs. Specifically, we choose Bfloat16 instead of FP16 due to its superior precision for values approaching zero, making it more suitable for µP. As a result, we do not encounter the FP16 underflow issue reported by [76]. To our knowledge, the FLM models are currently the largest ones successfully trained with mixed precision + µP. Moreover, Bfloat16 negates the need for loss scale adjustments, making our training procedure more promising and reproducible.
4. Benchmark Evaluation
Many existing benchmarks (e.g., Open LLM) focus on assessing the knowledgeability of LLMs. In this section, we discuss the results of FLM on these benchmarks. We argue that knowledge alone might not comprehensively reflect LLM’s capability (see Section 4.2 for more details). Thus, in addition to the common benchmark evaluation, we borrow the concept of IQ tests and evaluate LLMs with some specific tasks in Section 5.
기존의 많은 벤치마크(예: Open LLM)는 LLM의 지식성을 평가하는 데 중점을 둔다. 이 섹션에서는 이러한 벤치마크에 대한 FLM의 결과에 대해 논의한다. 우리는 지식만으로는 LLM의 역량을 포괄적으로 반영하지 못할 수 있다고 주장한다(자세한 내용은 섹션 4.2 참조). 따라서 일반적인 벤치마크 평가 외에도 섹션 5에서 IQ 테스트의 개념을 차용하여 몇 가지 구체적인 과제를 통해 LLM을 평가한다.
Cost Estimation Method. Due to the considerable computational expense of LLMs, we also emphasize their associated costs in our experimental results. However, it is hard to directly compare the actual cost of LLMs due to their different infrastructures, and the different costs incurred on different hardware. To objectively compare training costs, we use the number of floating-point operations for training as the cost estimation index, which can be estimated from the model’s hyperparameters, configuration, and training data [35]. Since many models do not release the complete training configuration (e.g., GPT-3, LLAMA series), we estimate FLOPs within a range5.
비용 추정 방법. LLM은 상당한 계산 비용이 들기 때문에 실험 결과에서 관련 비용도 강조한다. 그러나 각기 다른 인프라와 하드웨어에 따라 발생하는 비용이 다르기 때문에 LLM의 실제 비용을 직접 비교하기는 어렵습니다. 훈련 비용을 객관적으로 비교하기 위해 모델의 하이퍼파라미터, 구성, 훈련 데이터로부터 추정할 수 있는 훈련용 부동소수점 연산 횟수를 비용 추정 지표로 사용한다[35]. 많은 모델이 완전한 훈련 구성을 공개하지 않기 때문에(예: GPT-3, LLAMA 시리즈), 범위 내에서 FLOP을 추정한다5.
For monolingual LLMs, e.g., GPT-3, the cost from monolingual data is equal to the total cost. The computational cost of GPT-3 is calculated as 376.41 ( 53.77) zettaFLOPs, and LLAMA-2 (13B) as 210.37 ( 28.77) zettaFLOPs. Because the cost is linear to both model parameters and training data [19], we could calculate the cost of the remaining LLAMA models easily. For bilingual or multilingual models, it is necessary to estimate based on the amount of data in the corresponding language. The total cost of GLM-130B is 421.60 zettaFLOPs. We know that the data ratio of English and Chinese is 1:1. Hence, the cost of GLM-130B for English is 210.80 zettaFLOPs, and the same for Chinese. The data ratio of FLM-101B is 53.5% : 46.5% for English and Chinese. The total cost of FLM-101B is 52.76 zettaFLOPs. According to the data ratio, the cost for English and Chinese is 28.22 zettaFLOPs and 24.54 zettaFLOPs, respectively.
단일 언어 LLM(예: GPT-3)의 경우 단일 언어 데이터로 인한 비용은 총 비용과 같다. GPT-3의 계산 비용은 376.41(53.77) zettaFLOPs로 계산되고, LLAMA-2(13B)는 210.37(28.77) zettaFLOPs로 계산된다. 비용은 모델 파라미터와 학습 데이터 모두에 선형적이므로[19], 나머지 LLAMA 모델의 비용도 쉽게 계산할 수 있다. 이중 언어 또는 다국어 모델의 경우 해당 언어의 데이터 양을 기준으로 추정해야 한다. GLM-130B의 총 비용은 421.60제타플롭이다. 영어와 중국어의 데이터 비율은 1:1이라는 것을 알고 있다. 따라서 영어에 대한 GLM-130B의 비용은 210.80제타플롭이고 중국어에 대한 비용도 동일하다. FLM-101B의 데이터 비율은 영어와 중국어가 53.5% : 46.5%이다. FLM-101B의 총 비용은 52.76 zettaFLOPs이다. 데이터 비율에 따라 영어와 중국어의 비용은 다음과 같다. 각각 28.22제타플롭과 24.54제타플롭이다.
4.1 Open LLM Evaluation
Open LLM is an open-source project 6. Its target is to track and evaluate the open-sourced LLMs and chatbots. Open LLM contains four tasks: ARC-Challenge (ARC for short), HellaSwag, MMLU, and TruthfulQA. The Open LLM Leaderboard applies the average score of these tasks as a metric.
오픈 LLM은 오픈소스 프로젝트6이다. 이 프로젝트의 목표는 오픈 소스 LLM과 챗봇을 추적하고 평가하는 것이다. Open LLM에는 네 가지 작업이 포함되어 있다: ARC-Challenge (줄여서 ARC), HellaSwag, MMLU, TruthfulQA이다. Open LLM 리더보드에는 이러한 작업의 평균 점수가 지표로 적용된다.
ARC: The ARC [9] dataset is proposed for graduate-school level closed book science question- answering tasks. Most problems in ARC are solvable with life experiences and Wikipedia searches. Thus, a model is expected to perform better if exposed to more commonsense and factual data.
ARC: ARC [9] 데이터 세트는 대학원 수준의 비공개 서적 과학 문제 풀이 과제를 위해 제안되었다. ARC의 대부분의 문제는 실제 경험과 위키피디아 검색을 통해 해결할 수 있다. 따라서 모델은 보다 상식적이고 사실적인 데이터에 노출될 경우 더 나은 성능을 발휘할 것으로 예상된다.
HellaSwag: This is a sentence completion task emphasizing on commonsense inference [79]. We observe that the increase in HellaSwag performance is highly correlated with the reduction of training loss. This is intuitive because the training data is usually enriched with common sense.
헬라스웨그: 상식적인 추론에 중점을 둔 문장 완성 과제이다[79]. 우리는 HellaSwag 성능의 증가가 훈련 손실의 감소와 높은 상관관계가 있음을 관찰했다. 이는 훈련 데이터가 일반적으로 상식적인 내용이 풍부하기 때문에 직관적으로 이해할 수 있다.
MMLU: MMLU includes 57 multiple-choice tasks covering subjects spanning STEM to social science [17]. The tasks differ significantly in complexity, with many STEM-oriented questions demanding domain-specific professional knowledge and intricate reasoning to be solved.
MMLU: MMLU에는 STEM에서 사회 과학에 이르는 주제를 다루는 57개의 객관식 과제가 포함되어 있다[17]. 과제의 난이도는 상당히 다양하며, 많은 STEM 중심 문제는 도메인별 전문 지식과 복잡한 추론을 통해 해결해야 한다.
TruthfulQA: TruthfulQA contains 817 factual questions to detect model falsehoods caused by naively mimicking human language patterns [27]. The solutions to these questions are closely associated with English Wikipedia sources. The task probes a model’s factual knowledge and resistance to popular misconceptions.
TruthfulQA : TruthfulQA에는 인간의 언어 패턴을 순진하게 모방하여 발생하는 모델 오류를 탐지하기 위한 817개의 사실적 질문이 포함되어 있다[27]. 이러한 질문에 대한 해답은 영어 위키백과 소스와 밀접하게 연관되어 있다. 이 작업은 모델의 사실적 지식과 대중적 오해에 대한 저항력을 조사한다.
Table 3: Performance of FLM-101B and baselines including LLAMA series and GLM-130B. In order to visually compare the performance and cost, we estimate the floating-point opera- tions (zetta = 1021) of the training process.
표 3: FLM-101B의 성능과 LLAMA 시리즈 및 GLM-130B를 포함한 기준선. 성능과 비용을 시각적으로 비교하기 위해 훈련 프로세스의 부동 소수점 연산(제타 = 1021)을 추정한다.
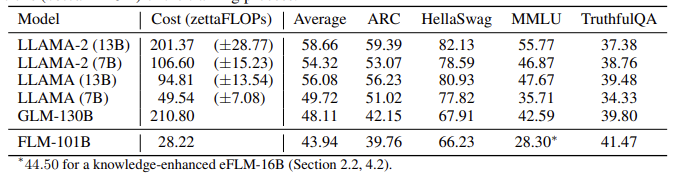
∗44.50 for a knowledge-enhanced eFLM-16B (Section 2.2, 4.2).
Table 3 details the performance of FLM-101B and strong baselines, including LLAMA series and GLM-130B. Because GPT-3 is closed-source, we could not get the probability values for a fair comparison. As a result, we cannot list GPT-3 here.
표 3은 FLM-101B의 성능과 강력한 기준선(LLAMA 시리즈 및 GLM-130B 포함)에 대해 자세히 설명한다. GPT-3는 비공개 소스이기 때문에 공정한 비교를 위한 확률 값을 얻을 수 없었다. 따라서 여기서는 GPT-3를 나열할 수 없다.
GLM-130B results are achieved by our run on an open-sourced checkpoint.
5This range originates from the use of checkpoint activation. Please check [35] for more details.
6https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboar
Results. Among all the baseline models, FLM-101B ranks last with an average of 43.94. However, going deeper into the nature of these tasks, this does not necessarily indicate the inferiority of our model and training procedures.
결과. 모든 기준 모델 중에서 FLM-101B는 평균 43.94로 최하위를 기록했다. 그러나 이러한 작업의 특성을 자세히 살펴보면 이것이 반드시 모델과 훈련 절차의 열등함을 의미하지는 않는다.
1) MMLU typically requires domain knowledge to solve. In our training of FLM-101B, no English textbook or sample exam questions are intentionally used. Nevertheless, in an FLM variant that incorporates this knowledge with FreeLM objectives (eFLM-16B, Section 2.2), even a 16B FLM model can outperform GLM-130B, supporting our claims here.
1) MMLU는 일반적으로 도메인 지식이 있어야 풀 수 있다. FLM-101B 교육에서는 영어 교과서나 샘플 시험 문제를 의도적으로 사용하지 않는다. 그럼에도 불구하고 이러한 지식을 FreeLM 목표(eFLM-16B, 섹션 2.2)와 통합한 FLM 변형에서는 16B FLM 모델조차도 GLM-130B를 능가할 수 있으며, 이는 여기에서 우리의 주장을 뒷받침한다.
2) As aforementioned, TruthfulQA, ARC, and HellaSwag emphasize more on common sense and Wiki-level knowledge, and their performances improve with the increased amount of data and the reduction of training loss. With less than 0.16T English data (about one-tenth of LLAMA-2), FLM-101B already achieves the best accuracy of 41.47 among all the baselines on TruthfulQA. On ARC and HellaSwag, FLM-101B is comparable to GLM-130B with a similar amount of English data (approximately 0.2T). Also, the training data of GLM-130B includes ARC and HellaSwag, as expressly claimed in [80]. In our understanding, superior performance of FLM-101B can be expected on these three tasks if exposed to more training data.
2) 앞서 언급한 바와 같이 TruthfulQA, ARC, 헬라스웨그HellaSwag는 상식과 위키 수준의 지식에 더 중점을 두고 있으며, 데이터 양이 증가하고 학습 손실이 감소함에 따라 성능이 향상된다. 0.16T 미만의 영어 데이터(LLAMA-2의 약 10분의 1)로 FLM-101B는 이미 TruthfulQA의 모든 기준선 중 최고 정확도인 41.47을 달성했다. ARC와 헬라스웨그에서 FLM-101B는 비슷한 양의 영어 데이터(약 0.2T)를 가진 GLM-130B와 비슷하다. 또한 [80]에서 명시적으로 주장한 바와 같이 GLM-130B의 훈련 데이터에는 ARC와 HellaSwag가 포함되어 있다. 우리의 이해에 따르면, 더 많은 훈련 데이터에 노출될 경우 이 세 가지 작업에서 FLM-101B의 우수한 성능을 기대할 수 있다.
4.2 Evaluation on the Professional Knowledge-Enhanced Version
We have also conducted experiments on a knowledge-enhanced version (eFLM-16B, detailed in Section 2.2) of the FLM to validate the effect of using domain-specific knowledge data. To reduce the training cost, we continue to train the smallest FLM-16B with teacher signals from a combination of (i) part of the auxiliary training data of MMLU [17], (ii) exam questions in similar domains and formats to C-Eval [20] 7, and (iii) other domain knowledge data. Note that, eFLM-16B is not a typical fine-tuning with additional data, which may affect the language capability of LLM. Recall that the FLM series uses FreeLM as its backbone which can learn both language and teacher signals. In this training, we preserve the language signal. Table 4 lists the result of eFLM-16B and baselines on C-Eval.
또한 도메인별 지식 데이터 사용의 효과를 검증하기 위해 FLM의 지식 강화 버전(eFLM-16B, 섹션 2.2에 자세히 설명)에 대한 실험을 수행했다. 훈련 비용을 줄이기 위해 (i) MMLU [17]의 보조 훈련 데이터 일부, (ii) C-Eval [20] 7과 유사한 도메인 및 형식의 시험 문제, (iii) 기타 도메인 지식 데이터의 조합에서 나온 선생 신호로 가장 작은 FLM-16B를 계속 훈련하고 있다. eFLM-16B는 추가 데이터를 사용한 일반적인 파인튜닝이 아니며, 이는 LLM의 언어 기능에 영향을 미칠 수 있다는 점에 주의. FLM 시리즈는 언어와 선생 신호를 모두 학습할 수 있는 FreeLM을 백본으로 사용한다는 점을 기억하라. 이 훈련에서는 언어 신호를 보존한다. 표 4에는 eFLM-16B의 결과와 C-Eval의 기준선이 나와 있다.
Table 4: Performance of eFLM-16B and baselines on C-eval. In this table, eFLM-16B refers to the professional-knowledge-enhanced FLM-16B. Note that C-Eval leaderboard only keeps one decimal place for the evaluation results.
이 표에서 eFLM-16B는 전문 지식이 강화된 FLM-16B를 의미한다. C-Eval 순위표는 평가 결과에 대해 소수점 이하 한 자리만 유지한다.

Results. Enhanced with professional knowledge, significant improvements are observed. On MMLU task, the incorporation of the teacher signals with professional knowledge data results in a score of 44.50 for eFLM-16B (see Table 3), which surpasses GLM-130B (42.59), a model that also uses multi-task data in the related domain [80]. As a comparison, the MMLU score is 27.02 for the un- enhanced FLM-16B. On C-Eval tasks 8, we observe that eFLM-16B performs better than GLM-130B by about 2 points. As a comparison, the average C-Eval score of the vanilla FLM-16B is 27.0, which underperforms GLM-130B. These results suggest that evaluation with professional knowledge may not fully reflect the capability of LLMs, particularly when different LLMs are trained with different data collections, and some may not come with a clear list.
결과. 전문지식으로 강화된 경우 상당한 개선된다. MMLU 과제에서 선생 신호를 전문지식 데이터와 통합하면 eFLM-16B의 점수는 44.50점(표 3 참조)으로, 관련 영역에서 멀티태스크 데이터를 사용하는 모델인 GLM-130B(42.59점)를 능가한다[80]. 비교를 위해, 강화되지 않은 FLM-16B의 MMLU 점수는 27.02이다. C-Eval 과제 8에서 eFLM-16B는 GLM-130B보다 약 2점 정도 더 나은 성능을 보였다. 이에 비해 바닐라 FLM-16B의 평균 C-Eval 점수는 27.0점으로 GLM-130B보다 성능이 떨어진다. 이러한 결과는 특히 서로 다른 데이터 수집을 통해 학습된 서로 다른 LLM의 경우, 전문 지식을 통한 평가가 LLM의 역량을 충분히 반영하지 못할 수 있음을 시사한다.
4.3 Evaluation of the Growth Strategy
Our core method for reducing computational cost is the growth strategy. We would like to answer the question of whether our growth strategy is effective in knowledge inheritance, and the trajectory of how model capabilities grow with size. Hence, we evaluate the performance of FLM on all the stages: 16B, 51B, and 101B. The training data for each stage is 0.245T, 0.04T, and 0.027T, respectively, in an accumulative manner according to the growth setting. Table 5 shows the performance of FLM models at each stage.
계산 비용을 줄이기 위한 핵심 방법은 성장 전략이다. 우리는 성장 전략이 지식 계승에 효과적인지, 모델 역량이 규모에 따라 어떻게 성장하는지에 대한 질문에 답하고자 한다. 따라서 우리는 모든 단계에서 FLM의 성과를 평가한다: 16B, 51B, 101B. 각 단계의 훈련 데이터는 성장 설정에 따라 누적 방식으로 각각 0.245T, 0.04T, 0.027T이다. 표 5는 각 단계별 FLM 모델의 성능을 보여준다.
7C-Eval can be considered as a Chinese version of MMLU.
8The scores are achieved on the test set by submitting to the C-Eval platform.
Table 5: Performance of the three stages of FLM on Open LLM. To reduce the computational cost during evaluation, we sample 20% and 30% items for HellaSwag and MMLU tasks, respectively.
표 5: Open LLM에서 FLM의 세 단계 성능. 평가 시 계산 비용을 줄이기 위해 헬라스웨그와 MMLU 작업에 대해 각각 20%와 30%의 항목을 샘플링했습니다.

Results. As expected, the performance of FLM improves with the increase in model size. FLM-101B achieves the best performance on almost all tasks. This means that our model inherits knowledge from the previous stage after each growth. We also observe that the 101B model improves the performance scores more significantly than the 51B model, with less data. This indicates that the models are successfully incorporating new weights in training after growth, and taking advantage of larger model sizes when the loss is low. Interestingly, the performance on ARC and HellaSwag increases steadily and significantly. This corresponds exactly to the steady decline of the model loss. Again, as we claimed in Section 4.1, when more training data is processed, FLM’s performance on Open LLM becomes better.
결과. 예상대로 FLM의 성능은 모델 크기가 커질수록 향상된다. FLM-101B는 거의 모든 작업에서 최고의 성능을 달성했다. 이는 모델이 성장할 때마다 이전 단계의 지식을 상속한다는 것을 의미한다. 또한 101B 모델이 더 적은 데이터로 51B 모델보다 성능 점수를 더 크게 향상시키는 것을 관찰했다. 이는 모델이 성장 후 학습에 새로운 가중치를 성공적으로 통합하고 손실이 적을 때 더 큰 모델 크기를 활용하고 있음을 나타낸다. 흥미롭게도 ARC와 헬라스웨그의 성능은 꾸준히 그리고 크게 향상된다. 이는 모델 손실이 꾸준히 감소하는 것과 정확히 일치한다. 다시 말하지만, 4.1절에서 주장했듯이 더 많은 훈련 데이터를 처리할수록 Open LLM에서 FLM의 성능이 더 좋아진다.
The above experiments evaluate the knowledge-related ability of FLM and how the performances depend on the amount and domain of training data. We also conduct an additional range of evaluations inspired by IQ tests in the following section.
위의 실험을 통해 FLM의 지식 관련 능력과 학습 데이터의 양과 도메인에 따라 성능이 어떻게 달라지는지 평가했다. 또한 다음 섹션에서는 IQ 테스트에서 영감을 얻은 다양한 평가를 추가로 수행한다.
5. Evaluations Inspired by IQ Tests
Section 4 details the evaluation of existing benchmarks, focusing on knowledge. As we discussed in Section 1, knowledge could not fully reflect the Intelligence Quotient (IQ) of LLMs. To this end, we use existing IQ-related datasets [71; 72; 53] and make necessary modifications or generate new synthetic datasets where necessary.
섹션 4에서는 지식에 초점을 맞춘 기존 벤치마크의 평가에 대해 자세히 설명한다. 섹션 1에서 논의했듯이, 지식은 LLM의 지능지수(IQ)를 충분히 반영하지 못했다. 이를 위해 기존 IQ 관련 데이터셋[71; 72; 53]을 활용하고 필요한 경우 수정하거나 새로운 합성 데이터셋을 생성한다.
Specifically, the IQ test mainly considers four aspects: symbolic mapping, rule understanding, pattern mining, and anti-interference. A common key property of these tasks is that they are dependent on the inference and generalization in a new context, instead of the previously-learned knowledge. We re-organize the modified existing datasets and our newly generated datasets under these four aspects, and introduce the motivation for each aspect, as well as the detailed execution methods.
특히 IQ 테스트는 주로 심볼릭 매핑, 규칙 이해, 패턴 마이닝, 간섭 방지라는 네 가지 측면을 고려한다. 이러한 작업의 공통적인 핵심 속성은 이전에 학습한 지식이 아닌 새로운 맥락에서의 추론과 일반화에 의존한다는 것이다. 수정된 기존 데이터셋과 새롭게 생성된 데이터셋을 이 네 가지 측면으로 재구성하고, 각 측면에 대한 동기 부여와 세부 실행 방법을 소개한다.
Compared Methods. Borrowing psychological ideas that the measurement of IQ is dependent on age 9, we mainly consider models trained with similar amounts of data to FLM-101B. As a milestone of LLM development, GPT-3 (175B) [3] proposed in-context learning for the first time. GLM-130B [80] is the first open English-Chinese bilingual LLM. Hence, we select them as baseline models. Both models are trained with 300 ~400 billion tokens, which are in the same range as ours. GPT-3 focuses on English, so it is not included in the Chinese-related evaluation (i.e., CLUE-IQ).
비교 방법. IQ의 측정이 9세에 좌우된다는 심리학적인 아이디어를 차용하여, FLM-101B와 비슷한 양의 데이터로 학습된 모델을 주로 고려했다. LLM 개발의 이정표로서 GPT-3(175B)[3]는 처음으로 인컨텍스트 학습을 제안했다. GLM-130B [80]은 최초의 개방형 영어-중국어 이중 언어 LLM이다. 따라서 이 두 모델을 기준 모델로 선택했다. 두 모델 모두 우리와 같은 범위인 3,000억~4,000억 개의 토큰으로 학습된다. GPT-3는 영어에 중점을 두기 때문에 중국어 관련 평가(즉, CLUE-IQ)에는 포함되지 않는다.
5.1 Symbolic Mapping Evaluation
An existing study [71] points out that classification tasks (e.g., document classification, sentiment classification) in textual forms often lack generalization. This is because they often come with very indicative and meaningful category labels. Such labels may laterally appear in the raw training data or popular websites, i.e., SemEval, IMDB [32], and Yelp 10 et al.. This leads a model to over-fit the semantics of the labels instead of inferring them from the new context, while the latter is critical for measuring intelligence as well. Considering this, we use a symbolic mapping method to replace the original category labels with symbols that are unlikely to be seen in the training data. Hence, we can evaluate the LLMs’ language understanding ability as well as the generalization abilities to a new context. Because the labels are from a given scope, we form our evaluation task as in-context learning with few-shot examples for each label.
기존 연구[71]에 따르면 텍스트 형식의 분류 작업(예: 문서 분류, 감성 분류)은 일반화가 부족한 경우가 많다고 지적한다. 이는 종종 매우 지시적이고 의미 있는 카테고리 레이블이 함께 제공되기 때문이다. 이러한 레이블은 원시 훈련 데이터나 인기 웹사이트(예: SemEval, IMDB [32], Yelp 10 등)에 측면적으로 나타날 수 있다. 이로 인해 모델은 새로운 컨텍스트에서 레이블을 추론하는 대신 레이블의 의미를 과도하게 맞추게 되는데, 후자는 지능을 측정하는 데에도 중요하다. 이러한 점을 고려하여 심볼릭 매핑 방법을 사용하여 원래 카테고리 레이블을 학습 데이터에서 볼 수 없는 기호로 대체한다. 이를 통해 LLM의 언어 이해 능력은 물론 새로운 맥락에 대한 일반화 능력도 평가할 수 있다. 레이블은 주어진 범위에서 나온 것이기 때문에 각 레이블에 대한 몇 개의 예시를 사용하여 상황 내 학습으로 평가 과제를 구성한다.
9https://ocw.mit.edu/ans7870/9/9.00SC/MIT9_00SCF11_text.pdf, page 367.
10https://www.yelp.com/dataset/documentation/main
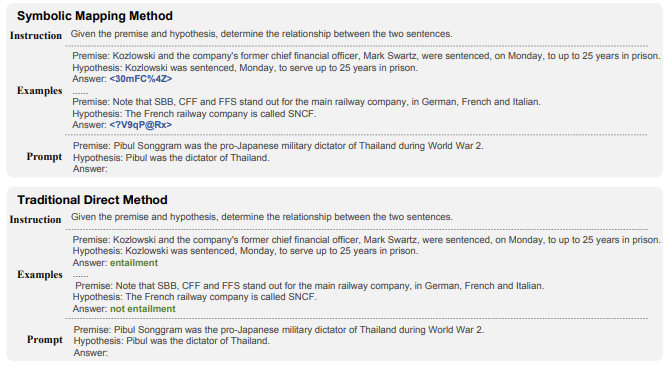
Figure 3: An example of symbolic mapping. The main difference is that the symbolic mapping method replaces the original label with random strings. In this example, we use <30mFC%4Z> and <?V9qP@Rx> to replace entailment and not entailment, respectively.
가장 큰 차이점은 심볼릭 매핑 방법은 원래 레이블을 임의의 문자열로 대체한다는 것이다. 이 예제에서는 <30mFC%4Z>와 <?V9qP@Rx>를 사용하여 각각 수반과 수반이 아닌 것을 대체한다.
5.1.1 Data Collection
We use the existing benchmark datasets (e.g., SuperGLUE [61], CLUE [74]) as the source and sample up to 300 instances. Then, we replace the original category labels with random strings. Figure 3 shows an example. In this case, the entailment category is replaced by random string <30mFC%4Z> while the not entailment category is replaced by <?V9qP@Rx>. This processing also mitigates the problem that these datasets may contaminate the LLM pre-training data, since both benchmarks are public with lots of reproductions. Table 6 presents the statistics and task types of the rebuilt datasets.
기존 벤치마크 데이터 세트(예: SuperGLUE [61], CLUE [74])를 소스로 사용하고 최대 300개의 인스턴스를 샘플링한다. 그런 다음 원래 카테고리 레이블을 임의의 문자열로 바꿉니다. 그림 3은 그 예를 보여준다. 이 경우 수반 범주는 임의 문자열 <30mFC%4Z>로 대체되고 비수반 범주는 <?V9qP@Rx>로 대체된다. 또한 이 처리는 두 벤치마크가 모두 공개되어 복제물이 많기 때문에 이러한 데이터 세트가 LLM 사전 훈련 데이터를 오염시킬 수 있는 문제를 완화한다. 표 6은 재구성된 데이터 세트의 통계 및 작업 유형을 나타낸다.
Table 6: Statistics for SuperGLUE-IQ and CLUE-IQ datasets. “WSD” stands for “Word Sense Disambiguation”; “SS” stands for “Sentence Similarity”; “KR” stands for “Keyword Recognition”; coref. stands for “coreference resolution”.
표 6: SuperGLUE-IQ 및 CLUE-IQ 데이터 세트에 대한 통계. "WSD"는 "단어 의미 명확성"을 의미한다. "SS"는 "문장 유사성"을 의미한다. "KR"은 "키워드 인식"을 의미한다. 핵심. "공동참조 해결"을 의미한다.

5.1.2 SuperGLUE-IQ
SuperGLUE is a benchmark dataset used in evaluating the classification ability of various models including LLMs. However, the data is publicly available and many websites have reproduced this dataset. As a result, it is inevitable that the models might have already been trained on it. Thus, we build a new dataset named SuperGLUE-IQ based on the original dataset. Since the answers for the test set of SuperGLUE are not publicly available, we use a validation set here. There are two rules for selecting the sub-tasks: (i) the number of instances exceeds 100; (ii) the classification categories are fixed sets. The building process is detailed in Section 5.1.1. Table 7 lists the performance of FLM-101B and the baselines.
SuperGLUE는 LLM을 포함한 다양한 모델의 분류 능력을 평가하는 데 사용되는 벤치마크 데이터 세트이다. 그러나 데이터는 공개적으로 사용 가능하며 많은 웹사이트에서 이 데이터 세트를 재현했다. 결과적으로 모델이 이미 이에 대해 훈련을 받았을 수도 있다. 따라서 원본 데이터 세트를 기반으로 SuperGLUE-IQ라는 새 데이터 세트를 구축한다. SuperGLUE 테스트 세트에 대한 답변은 공개적으로 제공되지 않으므로 여기서는 검증 세트를 사용한다. 하위 작업 선택에는 두 가지 규칙이 있다. (i) 인스턴스 수가 100을 초과한다. (ii) 분류 범주는 고정된 세트이다. 구축 프로세스는 섹션 5.1.1에 자세히 설명되어 있다. 표 7에는 FLM-101B의 성능과 기준선이 나열되어 있다.
Results. On BoolQ, WiC, and RTE tasks, FLM-101B and GPT-3 perform at the same level, and both outperform GLM-130B. In specific, GPT-3 and FLM-101B are more than 9 points better than GLM 130B on BoolQ. On WSC task, FLM-101B and GPT-3 perform comparably while both perform worse than GLM-130B with about an 18 points gap. The technical report of GLM-130B [80] shows that they use both the WSC and RTE datasets in training. It is interesting to observe that the performance of GLM-130B on the two tasks has such a difference. Since the original label is replaced by a random string, overfitting can be ruled out to a certain extent. We believe that the main reason lies in the structure of language models: GLM-130B contains a bidirectional encoder while FLM-101B and GPT-3 are uni-directional. This feature potentially makes GLM-130B perform better in English coreference resolution tasks, while poor in reasoning-related tasks (e.g., BoolQ). More importantly, the costs of the three models are very different. FLM-101B achieves a comparable performance with GPT-3 under about 1/13 of its computational cost.
결과. BoolQ, WiC 및 RTE 작업에서 FLM-101B와 GPT-3는 동일한 수준에서 성능을 발휘하며 둘 다 GLM-130B보다 성능이 뛰어나다. 구체적으로 BoolQ에서는 GPT-3과 FLM-101B가 GLM 130B보다 9포인트 이상 우수하다. WSC 작업에서 FLM-101B와 GPT-3은 비슷한 성능을 보이지만 둘 다 약 18포인트 차이로 GLM-130B보다 성능이 나쁘다. GLM-130B [80]의 기술 보고서는 훈련에 WSC 및 RTE 데이터 세트를 모두 사용한다는 것을 보여준다. 두 작업에 대한 GLM-130B의 성능에 이러한 차이가 있다는 점은 흥미롭다. 원래 레이블이 임의의 문자열로 대체되므로 과적합이 어느 정도 배제될 수 있다. 우리는 주된 이유가 언어 모델의 구조에 있다고 믿는다. GLM-130B에는 양방향 인코더가 포함되어 있고 FLM-101B 및 GPT-3은 단방향 인코더가 포함되어 있다. 이 기능은 잠재적으로 GLM-130B가 영어 상호 참조 해결 작업에서 더 나은 성능을 발휘하는 반면 추론 관련 작업(예: BoolQ)에서는 좋지 않습니다. 더 중요한 것은 세 모델의 비용이 매우 다르다는 것이다. FLM-101B는 계산 비용의 약 1/13로 GPT-3과 비슷한 성능을 달성한다.
Table 7: Performance on SuperGLUE-IQ of GPT-3, GLM-130B, and FLM-101B. The result of GPT-3 is evaluated by API. GLM-130B is evaluated with its open-sourced checkpoint.

5.1.3 CLUE-IQ
CLUE [74] is an open benchmark for Chinese NLP tasks. Similar to SuperGLUE-IQ, we build CLUE-IQ based on the CLUE dataset. Because GPT-3 is unable to handle Chinese well, here we compare FLM-101B with GLM-130B only. There are four tasks to be evaluated, including AFQMC, CSL, OCNLI, and CLUEWSC2020.11 Similar to SuperGLUE-IQ, we follow the same two rules to filter the original CLUE. Table 8 lists the performances of FLM-101B and GLM-130B.
CLUE [74]는 중국어 NLP 작업에 대한 개방형 벤치마크이다. SuperGLUE-IQ와 마찬가지로 CLUE 데이터셋을 기반으로 CLUE-IQ를 구축한다. GPT-3는 중국어를 잘 처리하지 못하기 때문에 여기서는 FLM-101B와 GLM-130B만을 비교한다. 평가할 작업은 AFQMC, CSL, OCNLI, CLUEWSC2020.11 SuperGLUE-IQ와 마찬가지로 동일한 두 가지 규칙에 따라 원본 CLUE를 필터링한다. 표 8에는 FLM-101B와 GLM-130B의 성능이 나와 있다.
Table 8: Performance on CLUE-IQ for GLM-130B and FLM-101B.

Results. On CLUE-IQ, our proposed FLM-101B achieves the best average performance of
42.07. Among the evaluated tasks, FLM-101B outperforms GLM-130B on AFQMC,
결과. CLUE-IQ에서 제안된 FLM-101B는 다음과 같은 최고의 평균 성능을 달성했다.
42.07. 평가된 작업 중 FLM-101B는 AFQMC에서 GLM-130B보다 성능이 뛰어나다,
CSL, and CLUEWSC2020. The results show that FLM-101B has good Chinese ability at the level of 100B parameters. Interestingly, FLM-101B performs better than GLM-130B on Chinese WSC, while worse than GLM-130B on English WSC. In addition, FLM-101B performs worse than GLM-103B on OCNLI. These results suggest that Chinese and English are different in nature and a model excelling in one language may not be good at both. Finally, from a cost-effective perspective, FLM-101B achieves better performance in Chinese at about 12% of the training cost of the counterpart.
CSL 및 CLUEWSC2020. 그 결과 FLM-101B는 100B 파라미터 수준에서 중국어 능력이 우수한 것으로 나타났다. 흥미롭게도 FLM-101B는 중국어 WSC에서는 GLM-130B보다 성능이 좋지만 영어 WSC에서는 GLM-130B보다 성능이 떨어진다. 또한 FLM-101B는 OCNLI에서 GLM-103B보다 성능이 더 나쁘다. 이러한 결과는 중국어와 영어는 본질적으로 다르며 한 가지 언어에 뛰어난 모델이 두 가지 언어 모두에서 우수하지 않을 수 있음을 시사한다. 마지막으로, 비용 효율성 측면에서 볼 때, FLM-101B는 해당 모델에 비해 약 12%의 훈련 비용으로 중국어에서 더 나은 성능을 달성한다.
5.2 Rule Understanding Evaluation
Symbolic mapping is able to lighten the negative effects of data overfitting. From a different perspective, we consider understanding rules and executing them according to the given rules is a strong indication of reasoning capability. To this end, we design rule understanding evaluation. Note that, this test is different from reasoning based on the chain of thought. The former focuses on the understanding ability of simple rules (e.g., counting) and performing the right action in a closed setting, while the latter focuses on reasoning ability in an open setting (e.g., different valid reasons for the same conclusion). For example, “counting an increasing sequence of numbers” is a typical task for rule understanding evaluation, which can be zero-shot.
심볼릭 매핑은 데이터 과적합의 부정적인 영향을 완화할 수 있다. 다른 관점에서, 우리는 규칙을 이해하고 주어진 규칙에 따라 실행하는 것이 추론 능력을 나타내는 강력한 지표라고 생각한다. 이를 위해 규칙 이해도 평가를 설계했다. 이 테스트는 사고 연쇄the chain of thought에 기반한 추론과는 다르다. 전자는 폐쇄된 환경에서 간단한 규칙(예: 숫자 세기)을 이해하고 올바른 행동을 수행하는 능력에 초점을 맞추는 반면, 후자는 개방된 환경에서의 추론 능력(예: 동일한 결론에 대한 여러 가지 타당한 이유)에 초점을 맞추고 있다. 예를 들어, '증가하는 일련의 숫자 세기'는 규칙 이해 평가의 전형적인 과제이며, 제로 샷이 될 수 있다.
Details of Selected Tasks and Data. Counting (0-shot) is the simplest test method for rule under- standing ability. Here, we build a bilingual dataset with 300 randomly generated items and report the results on 148 of them with English instructions. A typical example is “Let’s count from 10010 to 10035: 10010, 10011, 10012,”. String replacement (4-shots) is another task that examines the model’s capacity to edit the text precisely following human intention. We build two sub-tasks: Replace-Word and Replace-Lowercase, each of which contains 300 instances. Each instance starts with a clear instruction: for the “Replace-Word” task, it is like “In the following sentence, replace the specified word with the target word. word to replace: **WQHF** target word: **DFBB**”; for the “Replace-Lowercase” task, it is like “For the following text, please modify all uppercase letters to lowercase”. The counting range and words to replace are sampled with a uniform distribution. Table 9 shows the performance of our proposed FLM-101B against GPT-3 and GLM-130B on both counting and string replacement tasks.
선택한 과제 및 데이터의 세부 사항. 숫자 세기(제로샷)는 규칙 이해 능력에 대한 가장 간단한 테스트 방법이다. 여기서는 무작위로 생성된 300개의 항목으로 이중 언어 데이터 세트를 구축하고, 그 중 148개에 대한 결과를 영어 지침과 함께 보고한다. 일반적인 예는 "10010부터 10035까지 세어 봅시다: 10010, 10011, 10012,". 문자열 교체(4샷)는 사람의 의도에 따라 텍스트를 정확하게 편집할 수 있는 모델의 능력을 테스트하는 또 다른 과제이다. 두 가지 하위 작업을 구축한다: 단어 바꾸기와 소문자 바꾸기이며, 각각 300개의 인스턴스가 포함되어 있다. 각 인스턴스는 명확한 지침으로 시작된다. '단어 바꾸기' 작업의 경우 "다음 문장에서 지정된 단어를 대상 단어로 바꿔라. 대체할 단어: **WQHF** 대상 단어: **DFBB**"; "바꾸기-소문자" 작업의 경우 "다음 텍스트의 경우 대문자를 모두 소문자로 수정하라"와 같은 식이다. 바꾸기 범위와 바꿀 단어는 균일한 분포로 샘플링된다. 표 9는 계산 및 문자열 교체 작업 모두에서 제안된 FLM-101B의 GPT-3 및 GLM-130B 대비 성능을 보여준다.
11For the details of these tasks, please refer to the original work [74].
Table 9: Performance of FLM-101B, GPT-3, and GLM-130B on rule understanding tasks.

Results. On counting task, FLM-101B achieves 69.59%, about 9 points better than GLM-130B. GPT-3 wins the first place in counting and Replace-Lowercase, and second place in Replace-Word. This is potentially because GPT-3 has the largest amount of English training data. This experiment shows that the advantages of each model are varied. Hence, in future work, rule understanding evaluation tasks should cover more scenarios. Finally, considering the cost of each model, the performance of FLM-101B is satisfactory.
결과. 계산 작업에서 FLM-101B는 69.59%를 달성하여 GLM-130B보다 약 9점 더 높았다. GPT-3는 수 세기와 소문자 바꾸기에서 1위, 단어 바꾸기에서 2위를 차지했다. 이는 GPT-3가 가장 많은 양의 영어 학습 데이터를 보유하고 있기 때문일 가능성이 높다. 이 실험은 각 모델의 장점이 다양하다는 것을 보여준다. 따라서 향후 연구에서는 규칙 이해도 평가 작업에 더 많은 시나리오를 포함해야 한다. 마지막으로 각 모델의 비용을 고려했을 때 FLM-101B의 성능은 만족스러운 수준이다.
5.3 Pattern Mining Evaluation
Pattern Mining test is common in IQ tests. In detail, it is the induction and deduction of the patterns emerging in a new context. In general, it is difficult even for humans and is frequently used in intelligence tests. Again, we face the problem that the same test data might have appeared in large quantities, so we also use replacement methods similar to Section 5.1 to alleviate this problem.
Specifically, we build a benchmark with three tasks (i.e., Head & Tail, Full Repeating, and Head Slicing) for evaluation. Head & Tail is to add a head and a tail to the given input, which should be exactly the same as the ones in the given examples. Regarding Full Repeating, the input sequence should be fully repeated once. For the Head Slicing task, the model needs to return the first fixed number of characters of the input. The number can be inferred from the preceding examples. No instruction or clue is provided except the examples.
패턴 마이닝 테스트는 IQ 테스트에서 흔히 볼 수 있다. 자세히 설명하면 새로운 맥락에서 나타나는 패턴을 유도하고 추론하는 것이다. 일반적으로 사람조차도 어려워 지능 테스트에 자주 사용된다. 여기서도 동일한 테스트 데이터가 대량으로 나타날 수 있다는 문제에 직면하기 때문에 5.1절과 유사한 대체 방법을 사용하여 이 문제를 완화한다.
구체적으로 세 가지 작업(즉, 헤드 앤 테일, 풀 리피팅, 헤드 슬라이싱)으로 벤치마크를 구축하여 평가한다. 헤드 앤 테일은 주어진 입력에 헤드와 테일을 추가하는 것으로, 주어진 예제에서와 정확히 동일해야 한다. 전체 반복의 경우 입력 시퀀스가 한 번만 완전히 반복되어야 한다. 헤드 슬라이싱 작업의 경우 모델은 입력의 첫 번째 고정 문자 수를 반환해야 한다. 이 숫자는 앞의 예제에서 유추할 수 있다. 예제 외에는 어떠한 지침이나 단서도 제공되지 않는다.

Figure 4: Examples of pattern mining evaluation.
Figure 4 shows examples of these tasks. We sample the input strings, heads, and tails from a uniform distribution. These tasks are actually the “alphabetical” versions of the list_functions sub-task of Big-Bench [53]. The original numerical version is so simple that most existing LLMs could achieve 90%+ accuracy. To improve the distinctiveness, we replace the numbers with characters. All these tasks require the model to discover the behavior patterns inside the given examples. Each task is 5-shot and contains 100 instances. Table 10 lists the experimental results of our proposed FLM-101B against GPT-3 and GLM-130B on pattern mining tasks.
그림 4는 이러한 작업의 예를 보여준다. 균등 분포에서 입력 문자열, 머리, 꼬리를 샘플링한다. 이러한 작업은 실제로 Big-Bench [53]의 list_functions 하위 작업의 "알파벳순" 버전이다. 원래의 수치 버전은 매우 간단하여 대부분의 기존 LLM이 90% 이상의 정확도를 달성할 수 있다. 차별성을 높이기 위해 숫자를 문자로 대체했다. 이 모든 작업은 모델이 주어진 예제 내에서 행동 패턴을 발견하도록 요구한다. 각 작업은 5개의 샷으로 구성되며 100개의 인스턴스를 포함한다. 표 10은 패턴 마이닝 태스크에 대해 제안한 FLM-101B와 GPT-3 및 GLM-130B의 실험 결과를 나열한 것이다.
Table 10: Performance of FLM-101B, GPT-3, and GLM-130B on pattern mining tasks.
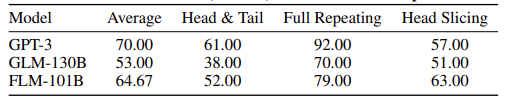
Results. On all three tasks, FLM-101B outperforms GLM-130B by a large margin. For the head & tail and full repeating tasks, FLM-101B is a few points behind GPT-3, but outperforms the latter on the head slicing task. Considering the computational cost, FLM-101B exhibits noticeable abilities in this area.
결과. 세 가지 작업 모두에서 FLM-101B가 GLM-130B를 큰 차이로 앞섰다. 헤드 & 테일 및 전체 반복 작업의 경우 FLM-101B는 GPT-3보다 몇 점 뒤쳐지지만 헤드 슬라이싱 작업에서는 후자보다 성능이 뛰어나다. 계산 비용을 고려할 때 FLM-101B는 이 영역에서 눈에 띄는 능력을 보여준다.
5.4 Anti-interference Evaluation
Anti-interference capability is critical for finding and utilizing information that is truly related to a specific goal, in an unseen and noisy context (Figure 5). We believe that in addition to generalization, anti-interference is also one of the important principles of AGI. For example, many LLMs will babble when given noisy cues. Another famous hard problem, the cocktail party problem in speech recognition [38], also suggests the importance of the anti-interference ability of intelligent agents. To this end, we conduct this anti-interference evaluation. Figure 5 shows two typical examples of this test.
간섭 방지 기능은 눈에 보이지 않고 잡음이 많은 상황에서 특정 목표와 진정으로 관련된 정보를 찾고 활용하기 위해 매우 중요하다(그림 5). 일반화 외에도 간섭 방지 기능도 AGI의 중요한 원칙 중 하나라고 생각한다. 예를 들어, 많은 LLM은 노이즈가 주어지면 더듬거린다babble. 또 다른 유명한 난제인 음성 인식의 칵테일 파티 문제[38]도 지능형 에이전트의 간섭 방지 능력의 중요성을 시사한다. 이를 위해 간섭 방지anti-interference 평가를 수행한다. 그림 5는 이 테스트의 대표적인 두 가지 예를 보여준다.

Figure 5: Examples of anti-interference evaluation.
Selected Tasks and Data Collection. We conduct anti-interference evaluation in three task types: multiple key retrievals, single supporting fact tracking, and two supporting facts tracking. Multiple key retrieval is a kind of puzzle that hides some important information (referred to as keys) inside a lot of irrelevant text. If the anti-interference ability of LLMs is not good enough, they will output the wrong or even meaningless words. Even if LLMs pass the first challenge, they may still fail due to multiple relevant noises. We collect a multiple key retrieval dataset in similar formats as those in [7] with at most 3 keys in each instance, exemplified in Figure 5. The single supporting fact tracking and two supporting facts tracking tasks test whether a model can find the chain of supporting facts to answer a question correctly, which is hidden inside a set of irrelevant statements. There are two sub-tasks in the babi-20 [72] benchmark (qa1 and qa2 12) that are aligned with this setting. Thus, we directly modify them in a generative format with 3 shots. We randomly sampled 300 questions for each of these three tasks. Table 11 shows the evaluation results on anti-interference.
선택된 작업 및 데이터 수집. 트위터에서는 다중 키 검색, 단일 근거 사실 추적, 두 가지 근거 사실 추적의 세 가지 작업 유형으로 간섭 방지 평가를 수행한다. 다중 키 검색은 관련 없는 많은 텍스트 안에 중요한 정보(키라고 함)를 숨기는 일종의 퍼즐이다. LLM의 간섭 방지 기능이 충분하지 않으면 잘못되거나 심지어 의미 없는 단어를 출력한다. LLM이 첫 번째 과제를 통과하더라도 여러 관련 노이즈로 인해 실패할 수 있다. 그림 5에 예시된 것처럼 [7]과 유사한 형식의 다중 키 검색 데이터셋을 수집하며, 각 인스턴스에 최대 3개의 키가 포함된다. 단일 지원 사실 추적과 두 개의 지원 사실 추적 작업은 모델이 질문에 올바르게 답하기 위한 일련의 지원 사실을 찾을 수 있는지 테스트하며, 이는 관련 없는 문장 집합에 숨겨져 있다. babi-20 [72] 벤치마크에는 이 설정과 일치하는 두 개의 하위 작업(qa1 및 qa2 12)이 있다. 따라서 3번의 샷으로 생성 형식으로 직접 수정한다. 이 세 가지 작업 각각에 대해 무작위로 300개의 질문을 샘플링했다. 표 11은 간섭 방지에 대한 평가 결과를 보여준다.
12We drop qa3 due to the long context length and extraordinary difficulty for all the models
Table 11: Performance of FLM-101B, GPT-3, and GLM-130B on anti-interference evaluation.
표 11: 간섭 방지 평가에서 FLM-101B, GPT-3 및 GLM-130B의 성능.

Results. Among all the baselines for this evaluation, FLM-101B achieves the second-best passing rates of 89.00%, 59.00%, and 32.33%, respectively, which is an advantage of about 11%, 3%, and 6% compared to GLM-130B. Considering the computational cost, FLM-101B delivers exciting performance.
In conclusion, on our four additional evaluations inspired by the IQ tests, FLM-101B outperforms GLM-130B and obtains competitive results compared to GPT-3 in some tasks with much lower costs. Except for the impacts of training data, the superiority may be owed to a story that in the growth strategy, the smaller models in early stages refine a more efficient searching space, which keeps taking effect when the model grows larger with increased generalization ability.
결과. 이 평가의 모든 기준선 중에서 FLM-101B는 각각 89.00%, 59.00%, 32.33%로 두 번째로 우수한 합격률을 달성했으며, 이는 GLM-130B에 비해 약 11%, 3%, 6%의 우위를 점한 것이다. 계산 비용을 고려할 때 FLM-101B는 놀라운 성능을 제공한다.
결론적으로, IQ 테스트에서 영감을 얻은 네 가지 추가 평가에서 FLM-101B는 GLM-130B보다 성능이 뛰어나며 일부 작업에서 훨씬 낮은 비용으로 GPT-3와 비교하여 경쟁력 있는 결과를 얻었다. 학습 데이터의 영향을 제외하면, 이러한 우월성은 성장 전략에서 초기 단계의 작은 모델이 보다 효율적인 검색 공간을 다듬어 일반화 능력이 향상되어 모델이 커질 때 계속 효과를 발휘한다는 이야기 때문일 수 있다.
6. Related Work
Scaling Up Language Models to 100B. The burgeoning advancements in hardware and computa- tional techniques in recent years [47; 52] have laid a robust groundwork for the expansion of language models. The benefits of scaling up LLMs include discernible advantages in language perplexity supported by studies on scaling laws [23; 18; 19; 77], as well as the emergent cognitive competencies in models [69; 4].
언어 모델을 100B로 확장. 최근 몇 년 동안 하드웨어와 컴퓨팅 기술의 급격한 발전[47; 52]은 언어 모델 확장을 위한 강력한 토대를 마련했다. 확장 법칙에 대한 연구[23; 18; 19; 77]와 모델의 새로운 인지 역량[69; 4]에 의해 뒷받침되는 언어 난해성에서의 뚜렷한 이점이 LLM 확장의 이점으로 포함된다.
In the realm of 100+ billion parameters, examples of closed-source pre-trained LLMs include GPT-3 [3], Gopher [42], and Palm [1]. For closed-source models trained on Chinese data, notable mentions are Ernie 3.0 [63], Pangu-Σ [48], and InternLM [57]. Turning our attention to open-source variants, OPT [81] and BLOOM [49] are among the counterparts to GPT-3; the Llama [58; 59] series strategically operates on a slightly reduced scale (approximately 70B parameters) but amplifies the data to 2T. GLM-130B [80] is an open-source bilingual model with decent performance in both Chinese and English tasks. Nevertheless, the development trajectory and cost of GLM-130B remain largely inaccessible to many academic and industrial entities. FLM-101B is an exemplary paradigm for achieving comparable performance with a relatively small $100K budget. It is our aspiration that this model serves as a catalyst, expediting research advancements and making them more economically feasible in this domain.
1,000억 개 이상의 파라미터가 있는 영역에서 pre-trained 오픈 소스 LLM의 예로는 GPT-3 [3], Gopher [42], Palm [1] 등이 있다. 중국 데이터로 학습된 클로즈드 소스 모델의 경우, Ernie 3.0 [63], Pangu-Σ [48], InternLM [57]이 주목할 만한 예이다. 오픈 소스 변형으로 관심을 돌리면, OPT [81] 및 BLOOM [49]이 GPT-3에 대응하는 모델 중 하나이며, Llama [58; 59] 시리즈는 전략적으로 약간 축소된 규모(약 70B 파라미터)로 작동하지만 데이터를 2T로 증폭한다. GLM-130B [80]는 오픈 소스 이중 언어 모델로 중국어와 영어 작업 모두에서 적절한 성능을 제공한다. 그럼에도 불구하고 GLM-130B의 개발 궤적과 비용은 많은 학계 및 산업체에서 접근하기 어려운 수준이다. FLM-101B는 상대적으로 적은 10만 달러의 예산으로 비슷한 성능을 달성할 수 있는 모범적인 패러다임이다. 이 모델이 촉매제 역할을 하여 이 분야에서 연구 발전을 촉진하고 경제적으로 더 실현 가능하게 만드는 것이 우리의 희망이다.
Aligning with Humans. Despite the evidence that foundation LLMs present reasoning abilities in zero/few-shot learning and chain-of-thought prompting [3; 70], further refinement is needed to enhance their abilities to follow instructions [68] and align with human preferences [37; 36; 13; 2]. Supervised fine-tuning releases the potential of LLMs to imitate the instruction-following formats and provide human-like responses in dialogical and problem-solving contexts [66; 73; 34; 26]. Meanwhile, policy optimization methods [50; 43] lead LLMs to generate responses that maximize rewards congruent with human preferences, e.g., being helpful and harmless [12].
인간과 일치. 기초 LLM이 제로/퓨 샷 학습과 연쇄 사고 프롬프트에서 추론 능력을 보인다는 증거에도 불구하고[3; 70], 지시를 따르는 능력[68]을 향상시키고 인간의 선호도에 맞추기 위해서는 추가적인 정교화가 필요하다[37; 36; 13; 2]. SFT는 대화 및 문제 해결 상황에서 instruction-following formats을 모방하고 인간과 유사한 응답을 제공할 수 있는 LLM의 잠재력을 해방시킨다[66; 73; 34; 26]. 한편, policy optimization methods[50; 43]은 LLM이 인간의 선호도에 부합하는 보상을 극대화하는 응답을 생성하도록 유도한다(예: 도움이 되고 무해한 응답)[12].
On the other hand, although these post-training techniques have proven effective and successful in industrial applications, the scaling laws regarding model sizes persist even after alignment with humans: larger models provide more factual and reasonable responses [16], as well as being better calibrated with their confidence probabilities [22]. We hereby release FLM-101B as a large foundation model, making it an accessible starting point for subsequent alignment studies.
반면에 이러한 사후 훈련 기법은 산업 응용 분야에서 효과적이고 성공적인 것으로 입증되었지만, 모델 크기와 관련된 스케일링 법칙은 인간과 정렬한 후에도 지속된다. 즉, 모델이 클수록 더 사실적이고 합리적인 응답을 제공하고[16] 신뢰 확률로 더 잘 보정된다[22]. 이에 따라 우리는 FLM-101B를 대규모 기초 모델로 출시하여 후속 얼라인먼트 연구를 위한 접근 가능한 출발점으로 삼는다.
LLM Evaluation. Widely-used approaches to evaluate LLMs include natural language processing benchmarks [74; 61], commonsense knowledge benchmarks [9; 79; 27], and professional knowledge benchmarks [17; 20]. For chatbots after fine-tuning, automatic and semi-automatic playgrounds are developed to evaluate their human alignment abilities [83]. Although knowledge-oriented ability is important, the results can be substantially impacted by training data and domains. To measure other classes of abilities, existing research like Big-Bench [53] and babi-20 [72] include some sub-tasks relevant to IQ tests, while others still depend more on NLP and knowledge. In this work, we add additional ranges of evaluation in the IQ-test paradigms by re-organizing existing datasets as well as creating new ones where proper.
LLM 평가. 자연어 처리 벤치마크 [74; 61], 상식 지식 벤치마크 [9; 79; 27], 전문 지식 벤치마크 [17; 20] 등 LLM을 평가하는 데 널리 사용되는 접근 방식이 있다. 파인튜닝 후 챗봇의 경우 자동 및 반자동 놀이터가 개발되어 인간 정렬 능력을 평가한다 [83]. 지식 중심 능력도 중요하지만, 훈련 데이터와 도메인에 따라 결과에 상당한 영향을 받을 수 있다. 다른 종류의 능력을 측정하기 위해 Big-Bench [53] 및 babi-20 [72]과 같은 기존 연구에는 IQ 테스트와 관련된 일부 하위 과제가 포함되어 있지만 다른 과제는 여전히 NLP 및 지식에 더 많이 의존한다. 이 연구에서는 기존 데이터 세트를 재구성하고 적절한 경우 새로운 데이터 세트를 생성하여 IQ 테스트 패러다임에 평가 범위를 추가했다.
Model Growth A line of existing work studies the progressive expansion of structures in training Transformer-like models [14; 51; 15; 6; 39; 62; 78]. To our knowledge, FLM-101B presents the first attempt to use a growth strategy to train LLMs in the 100B+ scale. For a more comprehensive summary, please refer to [78].
모델 성장 기존 연구에서는 트랜스포머와 유사한 모델을 훈련할 때 구조의 점진적인 확장을 연구했다[14; 51; 15; 6; 39; 62; 78]. 우리가 알기로는 FLM-101B가 성장 전략을 사용하여 100억 개 이상의 LLM을 훈련하는 첫 번째 시도이다. 보다 포괄적인 요약은 [78]을 참조하시기 바란다.
7. Conclusions and Future Work
In this paper, we introduce FLM-101B, an open-source LLM that is successfully trained from scratch within a $100,000 budget. The key idea of reducing the training cost of FLM-101B is to utilize the growth strategy to break through the fixed number of model parameters. To fairly evaluate LLMs, we conduct a set of evaluations inspired by IQ tests. We believe that along this pathway, better IQ evaluation methods will continue to emerge in future studies. Experimental results show that FLM-101B outperforms strong baseline models under the same computational cost.
이 페이퍼에서는 10만 달러의 예산으로 처음부터 성공적으로 학습한 오픈 소스 LLM인 FLM-101B를 소개한다. FLM-101B의 훈련 비용을 줄이기 위한 핵심 아이디어는 고정된 모델 파라미터 수를 돌파하기 위해 성장 전략을 활용하는 것이다. 유니티는 LLM을 공정하게 평가하기 위해 IQ 테스트에서 영감을 얻은 일련의 평가를 수행한다. 이 경로를 따라 향후 연구에서 더 나은 IQ 평가 방법이 계속 등장할 것으로 믿는다. 실험 결과에 따르면 FLM-101B는 동일한 계산 비용으로 강력한 기준 모델을 능가하는 것으로 나타났다.
The power of LLMs is very exciting. We believe that LLMs are one of the important possible technical paths to AGI. For the sustainable development of LLMs, we believe that it may be an effective path to construct a basic LLM with strong reasoning capabilities but not a large amount of knowledge (for cost saving), and then expand the knowledge of the LLM in different domains to better support applications. Besides, our exploration on the growth strategy as well as training stability would potentially be beneficial for future attempts of further scaling up LLMs, e.g., beyond 1T parameters.
LLM의 힘은 매우 흥미롭다. 우리는 LLM이 AGI로 가는 중요한 기술적 경로 중 하나라고 믿는다. LLM의 지속 가능한 발전을 위해서는 비용 절감을 위해 추론 능력은 강하지만 지식의 양이 많지 않은 기본 LLM을 구축하고, 다양한 영역에서 LLM의 지식을 확장하여 애플리케이션을 더 잘 지원하는 것이 효과적인 경로가 될 수 있다고 믿는다. 또한, 성장 전략과 학습 안정성에 대한 탐색은 향후 1T 파라미터를 넘어서는 등 LLM을 더욱 확장하려는 시도에 도움이 될 수 있을 것이다.
Acknowledgments
This work is supported by the National Key R&D Program of China (2022ZD0116300) and the National Science Foundation of China (NSFC No. 62106249). We would like to thank Hanxiao Qu, Yan Tian, Xigang Cao, Xiaolong Zhang, Kailong Xie and Conghui Guo for their help on computational resources, Quanyue Ma, Hanyu Zhao, Yihui Guo and Jiahong Leng for their help on data, and all other colleagues’ strong supports for this project.
이 연구는 중국 국가 중점 R&D 프로그램(2022ZD0116300)과 중국 국립과학재단(NSFC 번호: 62106249)의 지원을 받았다. 계산 리소스에 도움을 준 한샤오 쿠, 얀 티안, 시강 카오, 샤오롱 장, 카이롱 시에, 콩후이 구오, 데이터에 도움을 준 콴유 마, 한유 자오, 이휘 구오, 지아홍 렝, 그리고 이 프로젝트에 대한 다른 모든 동료들의 강력한 지원에 감사의 말씀을 전한다.